Python实战社群
Java实战社群
长按识别下方二维码,按需求添加
.jpg")
扫码关注添加客服
进Python社群▲

扫码关注添加客服
进Java社群▲
 作者 | 贝爽,本文转自雷锋网
作者 | 贝爽,本文转自雷锋网
昨晚做了一个梦,梦里的我变成漫画里的人物,正在为参与选秀苦练舞蹈,期待着万众瞩目登上舞台的一天。
然而一觉醒来,这个美梦竟然成“真”了!

大眼睛,饱满苹果肌,摆着离出道还有亿点点距离的律动~妥妥的漫画女主角既视感。
没错,这项黑科技就是手机QQ相机里的热门AI玩法——漫画脸。从画面来看,哪怕受拍摄人物大幅度动作,融合感依旧满分。
类似的,一经上线便备受用户们追捧的还有“童话脸”等多个AI特效玩法。
AI特效看似操作简单,但要想一秒内达到如此效果,其背后的技术支撑可并不简单。
细心的朋友可能会发现,漫画脸的AI特效get了一项技能——实时抠图。在动态场景下, 无论是人像的头部、面部,还是半身像,都能够被精准识别,并转化为漫画版,看不出一点破绽。
这项技能在学术上叫做语义分割技术。而这些特效背后使用的语义分割技术叫做GYSeg,它是腾讯光影研究室(Tencent GYLab)在计算机视觉领域的自研算法。最近GYSeg算法刚刚参加完MIT Scene Parsing Benchmark 场景解析国际竞赛,从多个参赛团队中脱颖而出,以0.6140的成绩斩获了冠军。值得一提的是,近两周团队持续优化算法,并再次刷线最新成绩至0.6235,仍处榜单第一名。
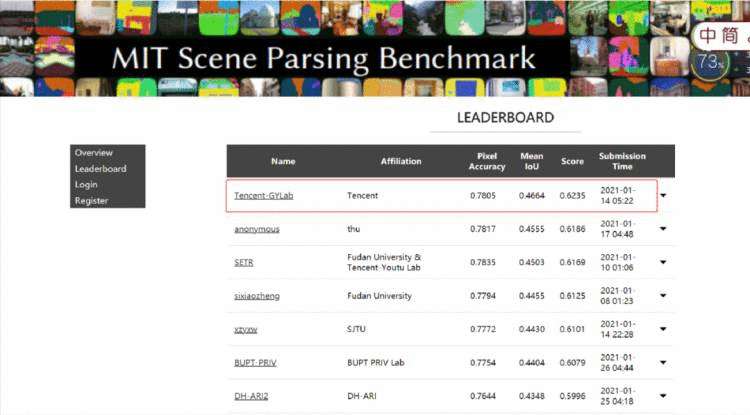
专业科普一下,MIT Scene Parsing Benchmark 是全球公认的最具挑战性、权威性的场景解析、语义分割评测集。其发布的ADE20K数据集是计算机视觉三大顶会(CVPR、ICCV和ECCV)语义分割论文的权威基准数据集。
每年有众多国际顶尖企业、学术机构参加这项国际赛事,比如本届参赛的团队还有商汤科技、亚马逊、复旦、北大、MIT等国内外研究机构和高校。
1
实时抠图神器:GYSeg算法
简单理解,语义分割技术就是让计算机能够识别出图像场景中每一个像素所代表的语义类别。
以人像图像为例,人像的全身、半身、头部、头发、多人/单人以及多样化的背景都是其需要识别的目标。
而从更大范围来讲,现实生活场景十分丰富、目标复杂、尺度范围大,如本次比赛所使用的ADE20K数据集包含了150个类别,涉及人类生活各个方面的场景。这对于AI语义识别本身提出了较高的挑战。
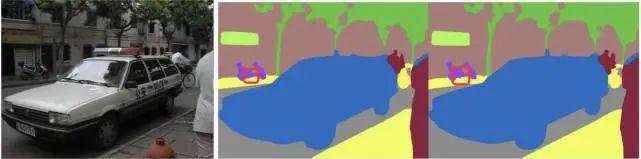
更重要的是,同种类的物体在不同场景中很可能表现出不同的大小、比例和姿态;不同物体之间可能存在相互遮挡问题,由此会带来严重的语义混淆。
为了克服以上难点,GYSeg算法在数据增强、网络设计、训练、推断方面进行了一系列创新,并建立了一套通用的整体分割架构。
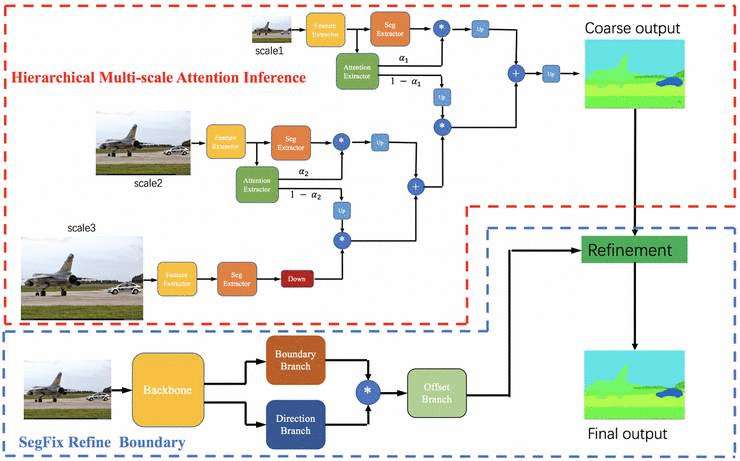
在网络设计方面,GYSeg算法采用自研的GYNet作为backbone,并接入ASPP模块进行特征的增强与融合,获得了更多的Context以及感受野,同时,整体结构达到了很好的速度跟精度的平衡。
在分割head方面,为提高不同尺度物体和小物体的分割精度,采用基于Multi-scale Attention的方式使网络在不同尺度上自适应的学习。
在推断阶段,GYSeg算法采用了多种不同尺度级联式推断融合。在此基础上,使用ADE训练集数据搭建SegFix网络,对Multi-scale Attention的输出结果进行精修,以提升边缘分割的一致性。同时,在训练过程,加入OHEM提升困难样本学习能力,在多物体分割中采用gradient loss对物体边缘进行约束来提升边缘的准确性。
在数据增强方面,除了针对复杂场景使用随机缩放、crop、对比度、blur等常规操作外,对于语义明确、数量较少的类别,GYSeg算法还采用了“复制-粘贴”的方式进行扩充。如动物、摩托车、自行车等。
在loss约束方面,借助OHEM进行在线困难样本挖掘,GYSeg算法在validation集上Miou提升0.4%,优于focalloss(提升0.26%)。
如上述案例所见,在人像分割方面,GYSeg算法凭借对人像半身、全身,室内、室外,单人/多人等多复杂场景的需求的不断的打磨和优化,成功应用到了腾讯QQ、腾讯微视等多个产品中。其结合发布器技术中台强大的图形图像渲染引擎,通过为前景人像和背景添加不同的滤镜特效或更酷的背景效果,实现 “七夕卡通画“、“怪兽护体”等各种特效玩法。
2
全栈式AI,落地泛娱乐场景
当然,GYSeg自研算法只是腾讯光影研究室AI能力的局部体现。
伴随新技术的不断发展和进步,AI在泛娱乐领域的应用场景变得更加丰富。在此基础上,光影研究室围绕计算机视觉技术展开了全栈式布局。
从技术能力上来讲,目前主要分为两大方面:应用AI能力和基础AI能力。

值得一提的是,依托腾讯庞大和丰富的内容产业,以上几乎所有AI能力都在移动端找到了落地场景,并成功覆盖到了手机QQ相机、手机QQ音视频通话、腾讯微视等20多条业务线中,为用户带来了全新的数字化娱乐体验。
应用AI能力
应用AI能力隶属于"基础美"的范畴,其主要目的是实现人像照片的系列美化功能,包含人脸的各种美颜/美妆/捏脸,不同场景的滤镜,以及底层的拍摄质量提升等。
具体表现为GAN的生成, 3D的重建,以及AR/交互AI等技术。
很多朋友应该知道,前段时间火爆全网的“童话脸”特效,不仅有李雪琴亲传童话世界基本生存须知“公主病”,更是受到辣目洋子、刘晓庆、王大陆等众多明星青睐。

童话脸特效背后依靠的便是GAN技术,它是腾讯光影研究室首次将GAN与3D卡通风格相结合的应用尝试,同时也是业内的第一次尝试。
据了解,从算法研究到上线首发,研究团队仅用了两周的时间,并成功克服了用户ID生成,StyleGAN稳定性,移动端实时化三大落地挑战。而且,基于自研的GYNet,其在移动端的网络计算量降低了200倍。目前这项AI能力仍在持续积累和迭代中。
在3D重建方面,光影研究室推出了3D捏脸能力,它可以根据用户给定的照片自动化捏出一个3D的人脸效果。从脸部的shape,五官的细节,到头发的效果,在最大限度保留用户ID的基础上,提供了最佳体验效果。

同时,在硬件适配方面,研究室团队针对低端机多了大量优化工作,包括底层使用TNN Inference框架,模型结构的小型化,模型的量化、裁剪,工程Pipeline的设计等。最终按照机型进行分发,保证了效果与速度的trade-off在高中低档机型的全面覆盖。
基础AI能力
这方面主要涉及检测&关键点、分割、分类三大类。上述语义分割算法GYSeg的研发属于这一范畴。值得一提的是,关于分割技术,光影研究室团队发表的论文《Context Prior for Scene Segmentation》,还登上了计算机视觉顶会CVPR2020。
在落地方面,除了泛娱乐场景外,以上前沿技术在图像处理、自动驾驶,自动医疗诊断等领域也有着极大地应用价值。比如语义分割算法GYSeg,在自动驾驶领域可用于区分路面阴影和真正的障碍物,以减少汽车误判率等。
据光影研究室介绍,团队定位为PCG的发布器技术中台,也承接了移动端的拍摄/相机/玩法类的AI能力,旨在通过前沿的AI能力、先进的玩法引擎和3D渲染技术,为腾讯的社交、短视频等产品用户提供服务。总体而言,业务方向更偏向To C端,更注重提升用户的娱乐体验。
透过光影研究室的技术布局和应用落地,可见其身上有两个显著的标签,一是聚焦“泛娱乐化场景”,二是“移动端部署”,后者从目前的落地成果来看,在行业内已具备核心竞争力。在整个腾讯AI产业布局中,这两个标签,也是腾讯光影研究室区别于腾讯优图、腾讯AI Lab最显著的差异化特征。
免责声明:本文内容来源于网络,文章版权归原作者所有,意在传播相关技术知识&行业趋势,供大家学习交流,若涉及作品版权问题,请联系删除或授权事宜。

程序员专栏 扫码关注填加客服 长按识别下方二维码进群

近期精彩内容推荐:
 几句话,离职了
几句话,离职了
中国男性的私密数据大赏,女生勿入!
为什么很多人用“ji32k7au4a83”作密码?
一个月薪 12000 的北京程序员的真实生活 !


在看点这里 好文分享给更多人↓↓
好文分享给更多人↓↓










 京公网安备 11010802041100号
京公网安备 11010802041100号