作者:火山哥哥5237 | 来源:互联网 | 2023-08-31 13:02
前文提到数据中台商业的解决方案有很多,开源框架种类繁多,每一个模块都有很多开源的套件。可供选择的解决方案太多,重点推荐开源解决方案,框架图如下图所示。 6.数据仓库在
前文提到数据中台商业的解决方案有很多,开源框架种类繁多,每一个模块都有很多开源的套件。可供选择的解决方案太多,重点推荐开源解决方案,框架图如下图所示。
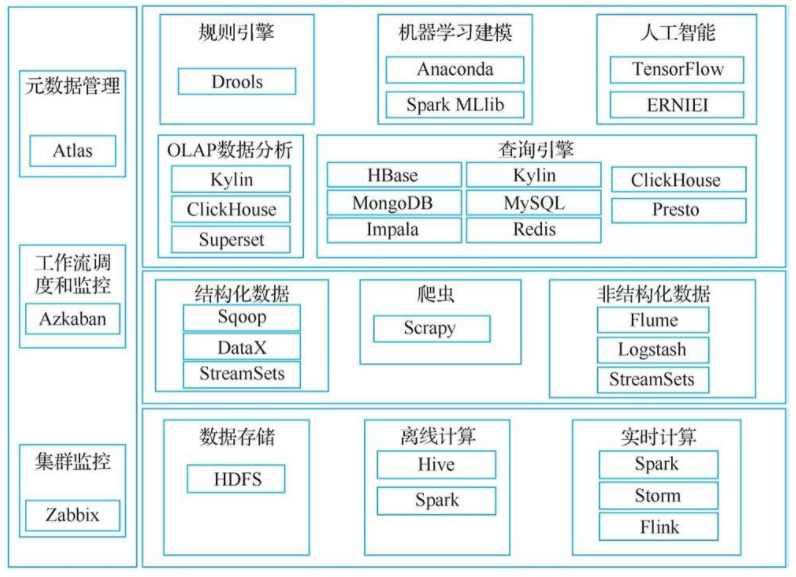
6.数据仓库
在数据平台选择好后,下一步的重要工作是实现企业的数据资产化,满足前端业务对数据应用的需求。数据资产化的关键举措是对企业的原始数据进行清洗和规整,将其转化为价值数据,然后从中抽象出主数据,进一步构建不同主题的数据标签体系。这些关键举措离不开数据仓库的标准化、存储、计算和建模体系化的支撑。目前,主流的数据仓库分为离线数据仓库和实时数据仓库,两者的典型区别是数据服务时间粒度。传统的离线数据仓库一般的数据服务时间粒度是天,实时数据仓库的数据服务时间粒度是分钟,甚至秒。从数据仓库存储和计算框架开源解决方案来看,目前行业的离线数据仓库普遍采用Hive+Spark的综合方案,而实时数据仓库当前的主流方案之一是HDFS+Flink+Kafka。目前,大部分企业在建设数据仓库时,综合考量性能、健壮性、投入产出比和运维复杂度,主要策略是以离线数据仓库的批处理计算为主,以实时数据仓库为辅助。
7.可视化自助数据分析
数据分析是实现数据价值的关键举措之一。透过错综复杂的数据关系发现价值点是一项费力、费时的工作。好的工具能够使这项工作事半功倍。为了提高数据分析的效率,行业涌现了多种解决方案,集中体现在自助取数、自助分析、多维分析、分析可视化这几个方面,目标是实现可视化自助数据分析。可视化自助数据分析的核心功能是支持多数据源接入、权限管理、高性能计算和可视化多维分析。目前,自助 OLAP 开源主要使用的计算引擎有Impala、Presto、ClickHouse和Kylin。在查询引擎部分,已经介绍过这几种计算引擎的特点,在此不再赘述。开源可视化解决方案主要有Superset、Redash和Metabase。Superset出自Airbnp,目前是Apache的开源项目,功能比较强大,网上的参考案例较多。Redash是一个轻量级的应用,部署简单,短小精悍,能满足日常分析需求。Metabase 的功能丰富程度介于Superset和Redash之间,网上的参考案例较少。在实际应用中,笔者重点推荐ClickHouse+Kylin+Superset的统一解决方案。预计算的OLAP使用Kylin引擎,及时查询的计算使用ClickHouse。
8.规则引擎
规则引擎是常用的实现数据价值的基础工具之一,常用的应用场景有风险管理、动态定价、精准营销、监控预警等。笔者过去一直使用开源工具Drools 结合二次开发搭建规则引擎,其优点是语法规则简单、支持动态规则配置、社区热度高、网上落地案例丰富、功能丰富且不断升级迭代,缺点是相对较重、应用门槛较高、聚合计算效率低等。对于实时规则应用场景,建议使用流式计算引擎计算复杂的聚合规则,而简单的规则计算使用Drools内核。
9.机器学习引擎
要从错综复杂的数据中挖掘出核心价值离不开算法的支持。智能化的真谛是使用机器学习算法、Al算法和其他算法不同程度地实现用机器替代人工。目前, 各种开源的算法包特别多, 当建模数据行数在千万级别时, 笔者常用 Anaconda 包和 XGBoost 包。当建模数据行数在亿级别时,笔者常用Spark MLlib。笔者使用的Al算法框架是TensorFlow。在自然语言处理方面,笔者常用的是百度的ERNIE框架,该框架在多个公开中文数据集下的性能比Google的BERT框架略好。
10.元数据管理
Atlas和Hadoop无缝连接,能有效地支持元数据管理、数据资产分类、元数据搜索、血缘关系可视化和数据治理。Atlas支持对元数据添加标签,然后通过标签对数据资产进行分门别类的管理,并基于标签进行统一权限控制和数据资产的安全管理。同时,Atlas还可以捕获各种元数据信息(如数据的产生、表的建立和执行、数据交互、数据ETL执行、数据存储、数据安全访问、数据的使用等),并支持查看元数据和血缘的可视化,便于及时发现数据的变化,快速定位数据问题。数据具有时效性,Atlas支持数据全生命周期管理(如在过了数据时效后,临时表被自动删除)。Atlas 还支持和多个外部平台(如Hive、SAS等)的元数据互联互通。我们可以将这些平台的元数据导入Atlas中,然后应用Atlas进行元数据管理和数据治理。
11.工作流调度和监控
数据应用百花齐放,系统后台需要对这些数据应用的工作流进行合理调度和监控,确保数据应用的及时性和稳定性。当任务运行失败时,系统要能及时发现并实时通知相关数据运维人员。这些功能是对工作流调度和监控工具的基本要求。目前,行业常用的开源工作流调度和监控工具主要是Oozie和Azkaban。两者的工作原理的最大区别是前者的工作流运行靠捕捉和监控更加细粒度的MapReduce批处理任务执行级别信息,而后者的工作流运行仅仅靠捕捉和监控较粗粒度的操作进程级别的信息。这会导致在任务出现失败或者断电后,Azkaban需要重新执行工作流,而Oozie可以基于失败的工作流重新执行。不过Azkaban的这个功能可以通过二次开发进行优化。Azkaban的优势是有完善的权限控制,支持对工作流的读写进行权限控制。
整体而言, Oozie的功能更加丰富, 比如支持Web、Rest API、Java API操作工作流,支持工作流的状态持久化存储、基于时间的定时任务调度及丰富的数据源等,但是其配置更复杂,开放性较弱,二次开发难度高,使用门槛更高。Azkaban是一个轻量级的应用,聚焦批量工作量的调度和监控,简单易用,更开放,支持二次开发。
总之,通过上述介绍的开源工具的部署、应用和整合,企业可以低成本且快速地搭建一套大数据平台,支持数据资产化,实现高性能的数据分析和数据应用,高效地支持业务的数字化和智能化转型。








 京公网安备 11010802041100号
京公网安备 11010802041100号