本文的代码文件原件可以在我们的数据臭皮匠中输入第六章1拿到1.基本概念介绍频繁项集和关联规则的挖掘首先需要了解一些概念,如支持度,置信度,事务,事务集,项,项集,频繁项
本文的代码文件原件可以在我们的 "数据臭皮匠" 中输入"第六章1" 拿到
1.基本概念介绍
频繁项集和关联规则的挖掘首先需要了解一些概念, 如支持度, 置信度, 事务,事务集,项,项集, 频繁项集等, 首先介绍下基本的概念定义(以下为笔者的简单化理解, 更严谨的定义请参考书中内容):
首先假设我们有一个由多行多列组成的表格
事务: 可以将事务简单理解为表格的其中一行
事务集:一个表格会有多行, 这个包括多个事务的集合就叫事务集
项:表格中每一行会包括多个值, 每一个值就是一个项
项集:多个项组成一个集合, 这个由多个项组成的集合就叫项集
k项集: 包含k个项的项集为k项集 , 如{I1,I2} 为一个2项集
支持度:假设有A项集, 表格共有N行, 其中包括A项集的有m行, 则绝对支持度为m, 相对支持度为m/N
置信度:表格中, 包括项集A的行有n1行, 同时包括项集A和B的有n2行, 置信度c = n2/n1
频度: 表格中有n1行包括项集A, n1即为A的频度
频繁项集: 如果项集的A的相对支持度满足预设的最小支持度阈值, 则项集A为频繁项集
规则: 假设有A,B两个项集, 由A出现可以推出B也出现(即A=>B) 这就是一条规则
强规则: 同时满足最小支持度阈值和最小置信度阈值的规则为强规则
2.闭频繁项集和极大频繁项集定义
从大型数据集中挖掘频繁项集的主要挑战是: 这种挖掘常常产生大量满足最小支持度阈值的项集, 这是因为如果一个项集是频繁的, 则它的每个子集也是频繁的(回忆下支持度的定义,N行的表格中有m行包括项集A, 则A的相对支持度为m/N)。如果一个包括100个项的项集为频繁项集{a1,a2,...a100} , 则它有100个频繁1项集,  =4950个频繁2项集{a1,a2}, {a1,a3}, ...{a99,a100} , 因此, 该100项的频繁项集共可以产生1.23*
=4950个频繁2项集{a1,a2}, {a1,a3}, ...{a99,a100} , 因此, 该100项的频繁项集共可以产生1.23*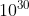 个频繁项集, 对于任何计算机, 这个项集都太大了, 大到无法计算和存储。
个频繁项集, 对于任何计算机, 这个项集都太大了, 大到无法计算和存储。
真超项集:假设X,Y为项集, 如果X是Y的真子项集, 则Y是X的真超项集。(X中每个项都包含在Y中, Y中至少有一个项不包含在X中)
闭的项集: 对于X项集, 如果表格中不存在与其拥有相同支持度的它的真超项集,则项集X为闭的。
闭频繁项集:如果项集X是闭的且频繁的, 则项集X为闭频繁项集。
极大频繁项集:对于频繁项集X,如果表格中不存在它的频繁的超项集, 则X为极大频繁项集
3.Apriori(先验)算法
Apriori算法使用一种称为逐层搜索的迭代方法, 首先通过扫描数据库,累计每个项的计数,并收集频繁1项集的集合。该集合记为L1,然后使用L1找出频繁2项集的集合L2, 使用L2找出L3, 如此下去,直到不能再找到频繁k项集。
为了提高频繁项集逐层产生的效率, 一种称为先验性质的重要性质用于压缩搜索空间。
先验性质:频繁项集的所有非空子集也一定是频繁的,从  到
到 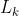 需要两步:连接步和剪枝步
需要两步:连接步和剪枝步
3.1 连接步
为找出 ,通过将 与自身连接产生候选k项集的集合, 该候选k项集的集合记为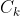 ,假设
,假设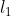 和
和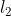 是 中的项集,
是 中的项集,![l_{i}\left [ j \right ]](https://img2.php1.cn/3cdc5/3beb/3b4/3f736f774b555e38.gif) 表示项集
表示项集 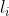 的第j 项。首先将 中的所有项集 排序,使得
的第j 项。首先将 中的所有项集 排序,使得![l_{i}\left [ 1 \right ]](https://img2.php1.cn/3cdc5/3beb/3b4/62681cee085fbde0.gif%5Cleft%20%5B%201%20%5Cright%20%5D) <
<![l_{i}\left [ 2 \right ]](https://img2.php1.cn/3cdc5/3beb/3b4/62681cee085fbde0.gif%5Cleft%20%5B%202%20%5Cright%20%5D) <...<
<...<![l_{i}\left [ k-1 \right ]](https://img2.php1.cn/3cdc5/3beb/3b4/62681cee085fbde0.gif%5Cleft%20%5B%20k-1%20%5Cright%20%5D) , 然后执行连接
, 然后执行连接 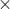 即 中的项集互相连接, 如果 和
即 中的项集互相连接, 如果 和 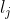 的前k-2项都是相同的, 则两者是可以连接的,连接的结果为
的前k-2项都是相同的, 则两者是可以连接的,连接的结果为 ![\left \{ l_{i}\left [ 1 \right ],l_{i}\left [ 2 \right ],...,l_{i}\left [ k-1 \right ],l_{j}\left [ k-1 \right ] \right \}](https://img2.php1.cn/3cdc5/3beb/3b4/70e63ca431bd7674.gif)

该连接过程需要将 中的元素两两连接, 执行完一遍
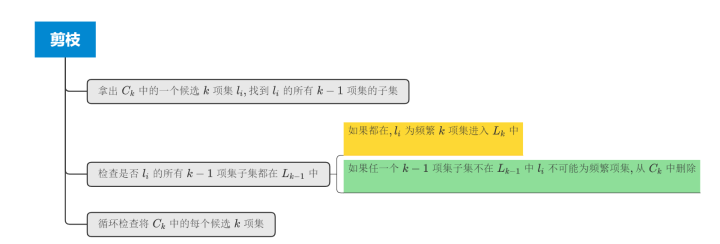
3.2 剪枝步
由连接步得到 后, 可以扫描数据库, 计算其中每个候选k项集的计数, 从而确定 ,但 可能很大, 在遍历它之前可以使用先验性质减少其中候选k项集的数量,即剪枝。剪枝原理为:如果k项集的任意一个k-1项集子集不在 中,则该k项集一定不是频繁项集,从而可以从 中删除。
在书中的P162-P163 有一个比较详细的例子, 读者可以认真看下, 应该可以很好的理解该过程
4.Apriori算法的代码实现
本代码使用书中数据集, 根据Apriori算法逐步实现, 可以和上文中文字介绍做一一比较, 可以看到代码结果和书中一致
def aprioriGen(Lk_1, k): #creates Ck """ 根据k-1项集产生候选k项集 Lk_1: k-1项集的列表 k: k项集的k """ retList = [] lenLk_1 = len(Lk_1) # k-1项集的长度 for i in range(lenLk_1): for j in range(i+1, lenLk_1): L1 = sorted(list(Lk_1[i])) # k等于2时, 1项集取空, k等于3时,2项集取第一个元素, k等于4时,3项集取前两个元素 L2 = sorted(list(Lk_1[j])) # k等于2时, 1项集取空, k等于3时,2项集取第一个元素, k等于4时,3项集取前两个元素 if L1[:k-2]==L2[:k-2]: # 如果前k减2个元素相等 , 就将两几何求并 retList.append(Lk_1[i] | Lk_1[j]) #set union return retList def get_subset(ss): """求一个k项集的所有k-1项集子集""" ls = list(ss) res = [] for i in range(len(ls)): res.append(set(ls[:i] + ls[(i+1):])) return res def check_in(Lk_1,ck): """ 返回布尔值, 检验候选k项集的所有k-1项集子集 是否都在L_(k-1)中 """ i = 0 # 取出候选k项集的一个k-1项集子集 for ss_sub in get_subset(ck): # 如果该k-1项集子集在在L_(k-1)中, 加1 if ss_sub in Lk_1: i+= 1 # 返回候选k项集的所有k-1项集子集 是否都在L_(k-1)中 return i == len(ck) def cut_branch(Ck,Lk_1): """剪枝, 只保留候选K项集集合中, 所有k-1项集都在L_(k-1) 的候选k项集 """ Ck_res = [] # 取出一个候选k项集 for ck in Ck: # 判断候选k项集的所有k-1项集子集 是否都在L_(k-1)中 flag = check_in(Lk_1,ck) # 如果是, 保留该候选k项集 if flag : Ck_res.append(ck) return Ck_res def createC1(dataSet): """从数据集中构建一项集候选集, 将每个一项集都以frozenset的数据类型保存 因为frozenset可以作为字典的key, 常规的set不可以, 方便后续对候选项集计数 """ C1 = [] for transaction in dataSet: for item in transaction: if not [item] in C1: C1.append([item]) # frozenset 可以作为字典的key, set 不可以 return [frozenset(i) for i in C1] def scanD(D, Ck, minSupport): """ D:数据集 Ck:候选k项集 minSupport:最小支持度阈值 """ # 扫描数据集,确定Ck中每个候选的计数 ssCnt = {} for tid in D: for can in Ck: if can.issubset(tid): ssCnt[can] = ssCnt.get(can,0)+1 # 根据最小支持度阈值筛选出频繁k项集 retList = [] supportData = {} for key in ssCnt: # 计算备选k项集的支持度 support = ssCnt[key] # 如果支持度大于阈值, insert进k项集的结果列表 if support >= minSupport: retList.insert(0,key) # 不管支持度是否大于阈值, 都记录下该备选k项集的支持度 supportData[key] = support return retList, supportData def apriori(dataSet, minSupport): C1 = createC1(dataSet)
# print(&#39;C1:&#39;,C1) D = [set(i) for i in dataSet] # 检查C1中每个备选1项集的支持度, L1为筛选出的1项集, supportData为每个备选1项集的支持度 L1, supportData = scanD(D, C1, minSupport) print(f&#39;L1:{L1}&#39;,&#39;\n&#39;) L = [L1] # 将1项集列表插入频繁k项集的结果列表 k = 2 # 2项集 # k项集为空的时候停止 while (len(L[k-2]) > 0): Ck = aprioriGen(L[k-2], k) # 连接步,产生备选k项集 print(&#39;过滤前:&#39;,len(Ck),Ck,&#39;\n&#39;) Ck = cut_branch(Ck,L[k-2]) # 剪枝 print(&#39;过滤后:&#39;,len(Ck),Ck,&#39;\n&#39;) Lk, supK = scanD(D, Ck, minSupport)#scan DB to get Lk 扫描数据集,确认C_k中的每个候选k项集是否为频繁项集 print(&#39;筛选后:&#39;,len(Lk),Lk,&#39;\n&#39;) supportData.update(supK) L.append(Lk) k += 1 return L, supportData data_ls =[[&#39;I1&#39;,&#39;I2&#39;,&#39;I5&#39;], [&#39;I2&#39;,&#39;I4&#39;], [&#39;I2&#39;,&#39;I3&#39;], [&#39;I1&#39;,&#39;I2&#39;,&#39;I4&#39;], [&#39;I1&#39;,&#39;I3&#39;], [&#39;I2&#39;,&#39;I3&#39;], [&#39;I1&#39;,&#39;I3&#39;], [&#39;I1&#39;,&#39;I2&#39;,&#39;I3&#39;,&#39;I5&#39;], [&#39;I1&#39;,&#39;I2&#39;,&#39;I3&#39;]] L, supportData =apriori(data_ls,minSupport = 2)
print(&#39;L:&#39;,L,&#39;\n&#39;)
print("supportData:",supportData)
结果为

参考文档:
-
数据挖掘概念与技术(原书第三版)
-
机器学习实战(人民邮电出版社) 第11章
关注公众号:数据臭皮匠;获得更多精彩内容
作者:范小匠
审核:灰灰匠
编辑:森匠




 京公网安备 11010802041100号
京公网安备 11010802041100号