最近被大数据相关的小词儿,整的有点懵。
索性我们就来个专题,聊透数据库、数据仓库、数据湖以及风头正劲的“Lake house”——湖仓一体化。
 数据仓库是个啥?和数据库有什么不同?
数据仓库是个啥?和数据库有什么不同?
数据库的基本概念,大家应该都不陌生。如今但凡是个业务系统,都或多或少需要用到数据库。
即便我们不直接跟数据库打交道,它们也在背后默默滴为我们服务,比如刷个卡、取个钱,后台都是数据库们在扛着。
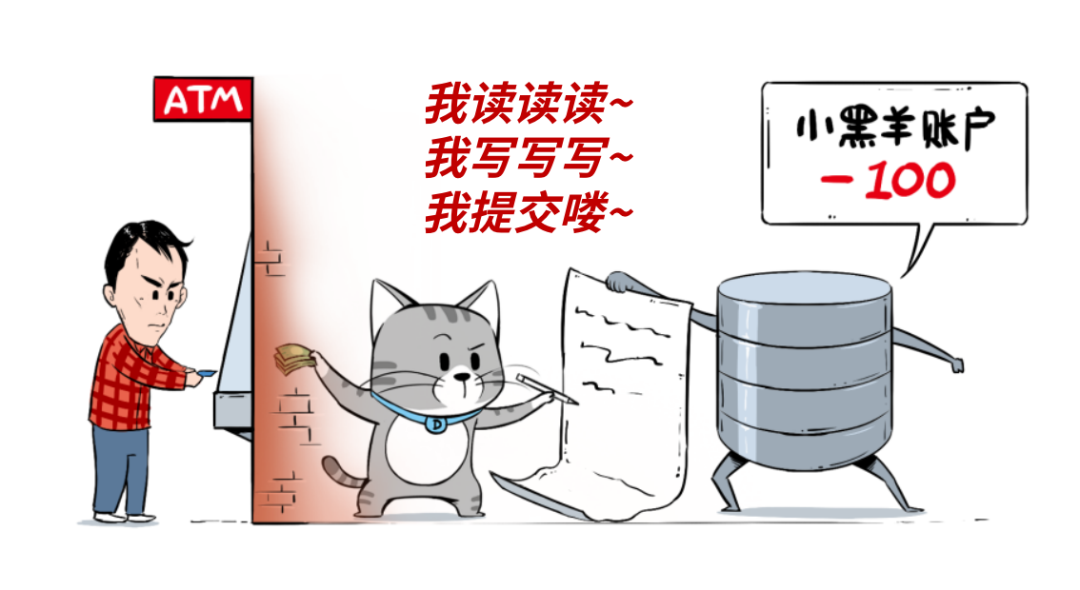
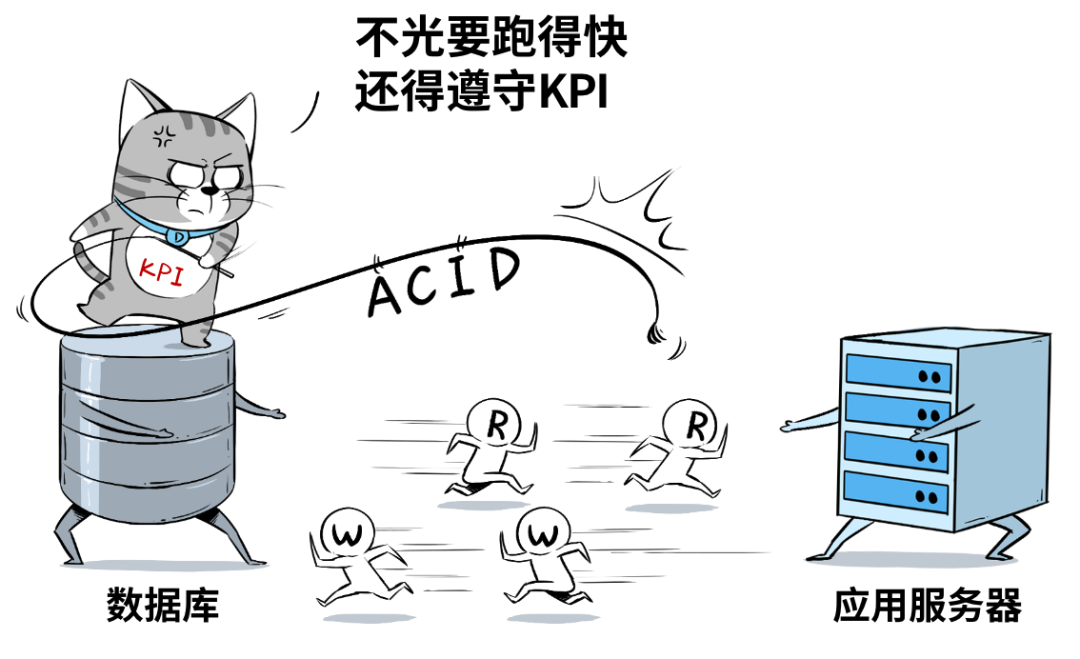
数据库主要用于「事务处理」,存取款这种算是最典型的,特别强调每秒能干多少事儿:QPS(每秒查询数)、TPS(每秒事务数)、IOPS(每秒读写数)等等。
但要是说起数据仓库,吃瓜群众还真很少接触到。
通常是业务发展到一定规模后,业务分析师、CIO、决策者们,希望从大量的应用系统、业务数据中,进行关联分析,最终整点“干货”出来。
比如为啥利润会下滑?为啥库存周转变慢了?向数据要答案,整点报告、图表出来给老板汇报,辅助经营决策。

可是,数据库“脑容量不足”,擅长事务性工作,不擅长分析型的工作,于是就产生了数据仓库。
虽然现在HTAP的概念很盛行,也就是混合事务/分析处理,用一套数据库架构来同时支持事务(OLTP)和分析(OLAP)两种需求,但真正大规模的分析和洞察,还是离不开数据仓库。
数据仓库相当于一个集成化数据管理的平台,从多个数据源抽取有价值的数据,在仓库内转换和流动,并提供给BI等分析工具来输出干货。
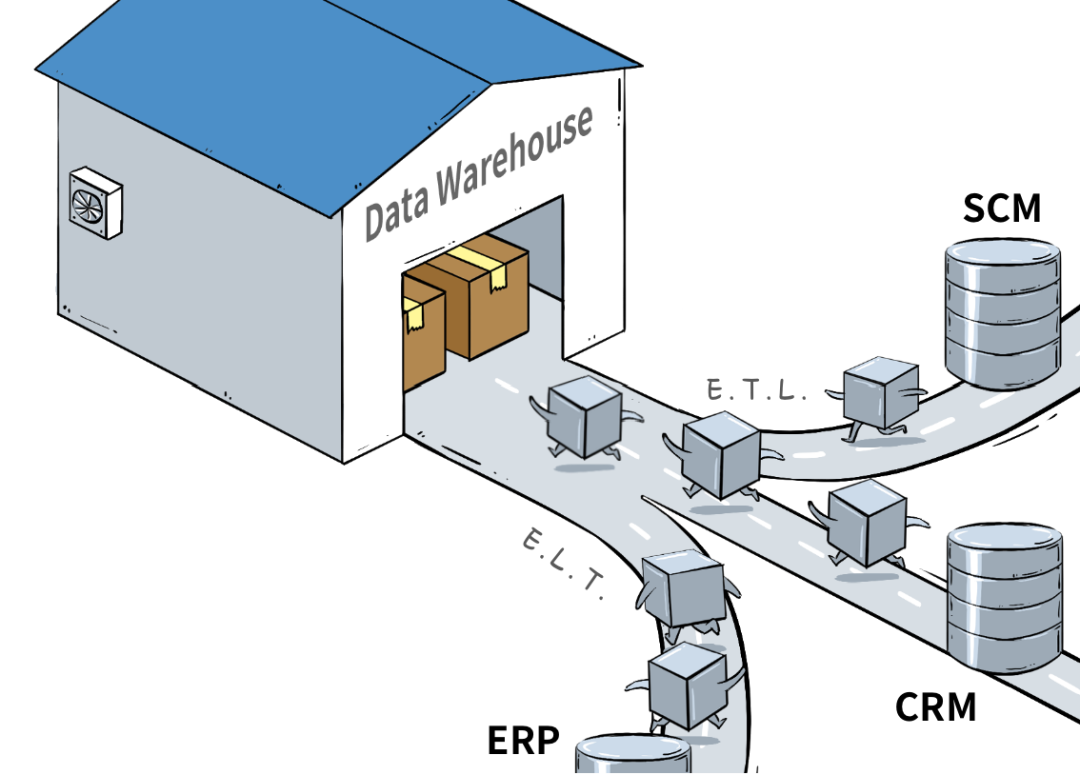
因为分析型业务需要大量的“读”操作,所以数据仓库通过“Denormalized”化的方式优化表结构,减少表间联接,牺牲空间来换取读性能。(一张表里的冗余数据增加了,但查询起来却更快了),并使用列式存储优化,来进一步提高查询速度、降低开销。
再结合面向分析场景的Schema设计,数据仓库就可以高效率、全方位、多维度的扛起“联机分析”重任了。
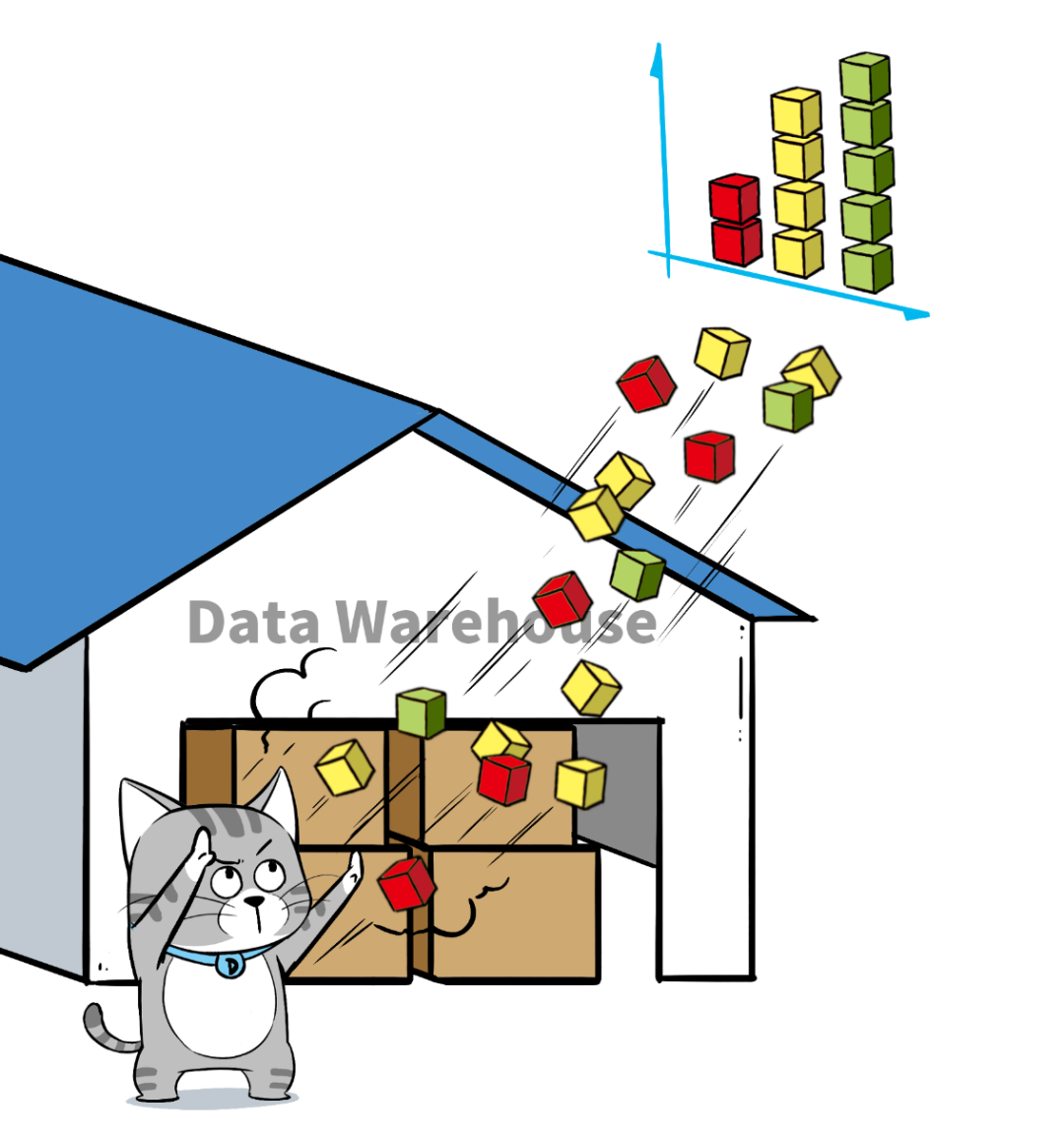
关于数据库和数据仓库的区别,我们再总结一下↓

来源:根据亚马逊云科技官网相关素材整理
 数据湖又是个啥?
数据湖又是个啥?
数据库负责干事务处理相关的事,数据仓库负责干业务分析相关的事,还有新兴的HTAP数据库既干事务又干分析,都已经这么内卷了,还要数据湖来干个毛线?
说白了,还是企业在持续发展,企业的数据也不断堆积,虽然“含金量”最高的数据都存在数据库和数仓里,支撑着企业的运转。
但是,企业希望把生产经营中的所有相关数据,历史的、实时的,在线的、离线的,内部的、外部的,结构化的、非结构化的,都能完整保存下来,方便“沙中淘金”。
数据库和数据仓库都干不了这活儿,怎么办呢?
挖个大坑,修个湖,把各种数据一滚脑灌进去囤起来,而且要持续灌,持续囤。这就是数据湖啦!

数据湖的本质,是由“➊数据存储架构+➋数据处理工具”组成的解决方案,而不是某个单一独立产品。
➊数据存储架构,要有足够的扩展性和可靠性,要满足企业能把所有原始数据都“囤”起来,存得下、存得久。
一般来讲,各大云厂商都喜欢用对象存储来做数据湖的存储底座,比如 Amazon Web Services(亚马逊云科技),修建“湖底”用的“砖头”,就是S3云对象存储。

➋数据处理工具,则分为两大类↓
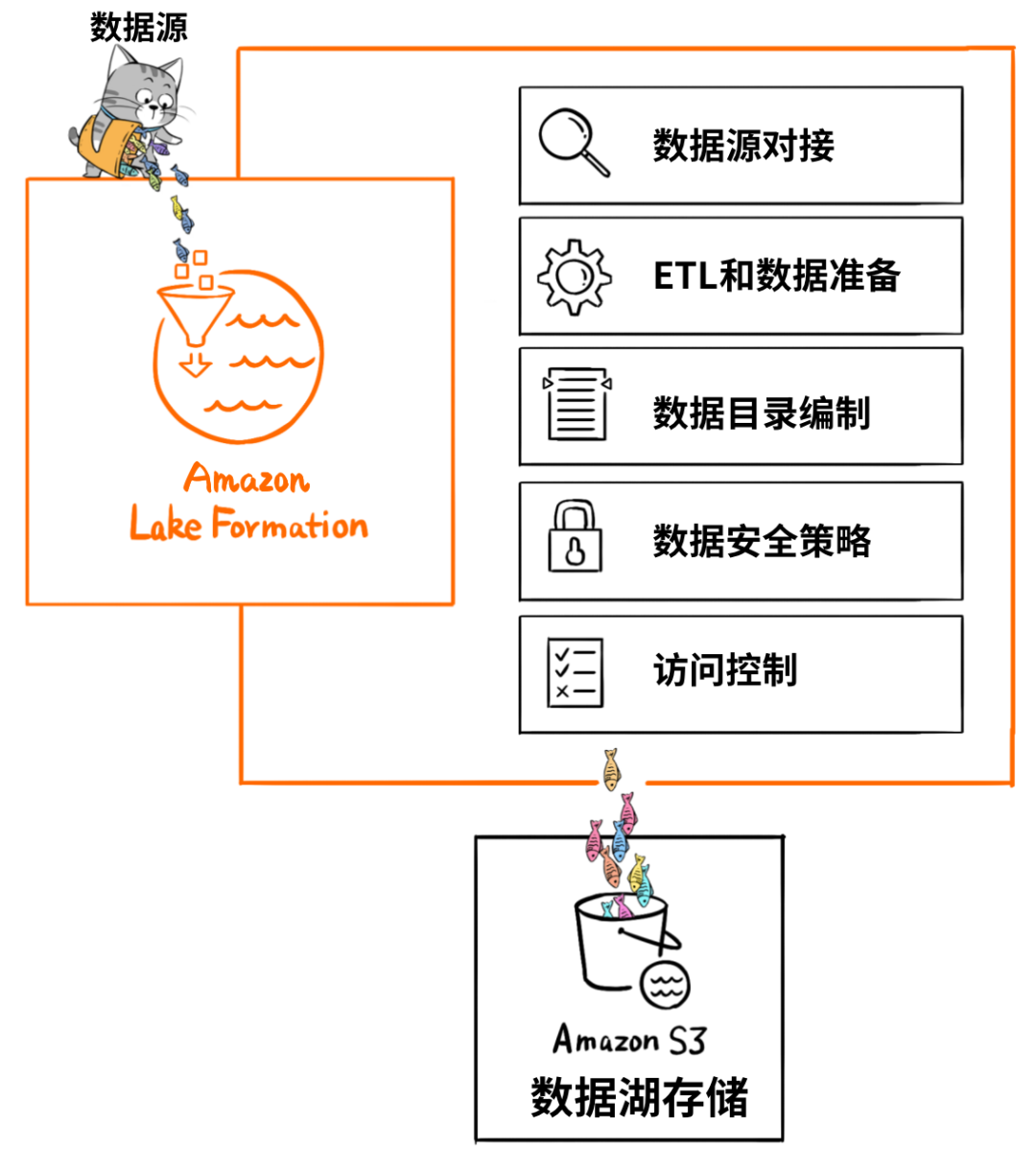
第一类工具,解决的问题是如何把数据“搬到”湖里,包括定义数据源、制定数据访问策略和安全策略,并移动数据、编制数据目录等等。

如果没有这些数据管理/治理工具,元数据缺失,湖里的数据质量就没法保障,“泥石俱下”,各种数据倾泻堆积到湖里,最终好好的数据湖,慢慢就变成了数据沼泽。

因此,在一个数据湖方案里,数据移动和管理的工具非常重要。
比如,Amazon Web Services提供“Lake Formation”这个工具,帮助客户自动化地把各种数据源中的数据移动到湖里,同时还可以调用Amazon Glue来对数据进行ETL,编制数据目录,进一步提高湖里数据的质量。
第二类工具,就是要从湖里的海量数据中“淘金”。
数据并不是存进数据湖里就万事大吉,要对数据进行分析、挖掘、利用,比如要对湖里的数据进行查询,同时要把数据提供给机器学习、数据科学类的业务,便于“点石成金”。

我们继续拿Amazon Web Services来举例子,基于Amazon Athena这个服务,就可以使用标准的SQL来对S3(数据湖)中的数据进行交互式查询。
再比如使用Amazon SageMaker机器学习服务,导入数据湖中的数据进行模型训练,这些都是常规操作。
小结一下,数据湖不只是个“囤积”数据的“大水坑”,除了用存储技术构建的湖底座以外,还包含一系列的数据入湖、数据出湖、数据管理、数据应用工具集,共同组成了数据湖解决方案。
 数据湖和数据仓库区别在哪儿?
数据湖和数据仓库区别在哪儿?
这个问题其实不难回答,我们先看下面这张对比表。
 来源:根据亚马逊云科技官网相关素材整理
来源:根据亚马逊云科技官网相关素材整理
从数据含金量来比,数据仓库里的数据价值密度更高一些,数据的抽取和Schema的设计,都有非常强的针对性,便于业务分析师迅速获取洞察结果,用与决策支持。
而数据湖更有一种“兜底”的感觉,甭管当下有用没有/或者暂时没想好怎么用,先保存着、沉淀着,将来想用的时候,尽管翻牌子就是了,反正都原汁原味的留存了下来。

而从产品形态看,数据仓库可以是独立的标准化产品,拿云上数仓来举例,Amazon Redshift,就是一款“数仓产品”。
数据湖则是一种架构,通常是围绕对象存储为“湖底座”的大数据管理方案组合。比如,Amazon Web Services并没有哪个产品叫“数据湖”,而是以S3为基础,结合一系列数据管理工具,帮助客户构建云上“数据湖”↓
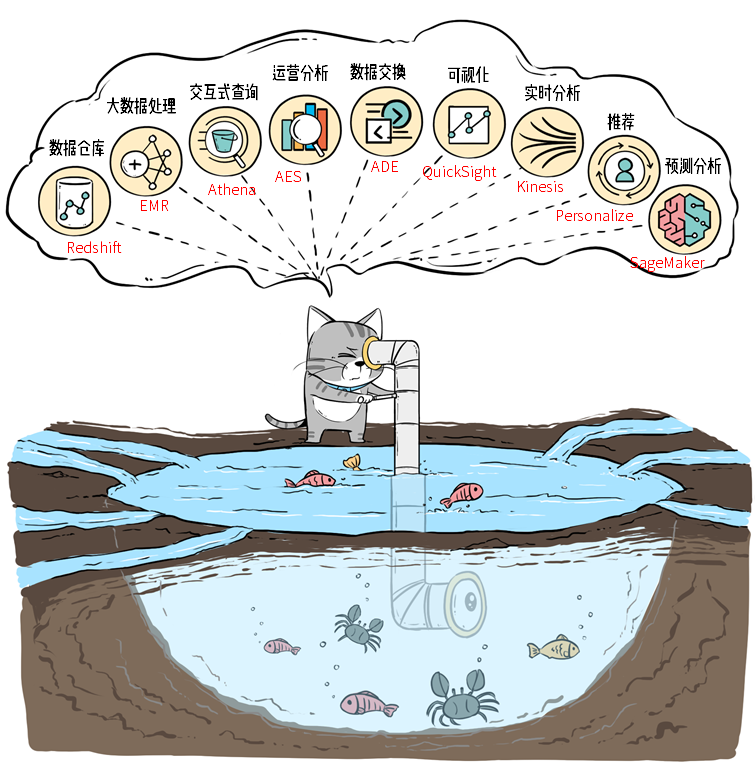
引用自文章:数据湖这个大坑,是怎么挖的?
回想以前科普Amazon Web Services数据湖的插画,可以看到,以“湖”为基础,“A厂”准备了各式各样的工具和服务,它们紧密集成在一起。这里应该狠狠mark一下,读到后面你会发现,“A厂”设计数据湖架构的初衷,就是奔着“湖仓架构”去的。
 为什么要把“湖”和“仓”糅到一起?
为什么要把“湖”和“仓”糅到一起?
曾经,数据仓库擅长的BI、数据洞察离业务更近、价值更大,而数据湖里的数据,更多的是为了远景画饼。
随着大数据和AI的上纲上线,原先的“画的饼”也变得炙手可热起来,为业务赋能,价值被重新定义。
而因为数仓和数据库的出发点不同、架构不同,企业在实际使用过程中,“性价比”差异很大。
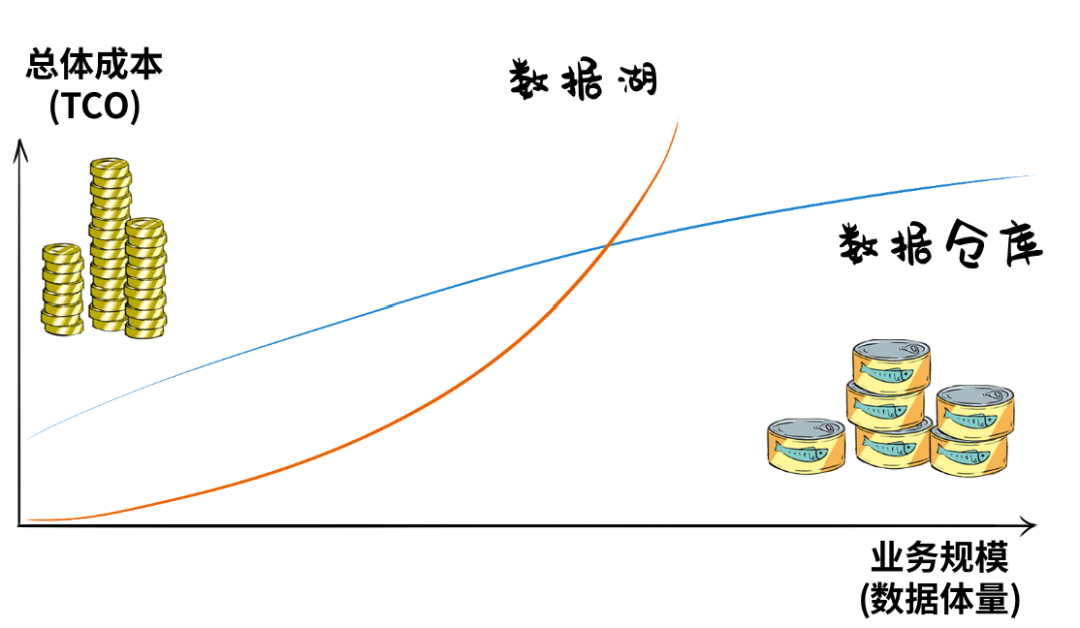 、
、
数据湖起步成本很低,但随着数据体量增大,TCO成本会加速飙升,数仓则恰恰相反,前期建设开支很大。
总之,一个后期成本高,一个前期成本高,对于既想修湖、又想建仓的用户来说,仿佛玩了一个金钱游戏。
于是,人们就想,既然都是拿数据为业务服务,数据湖和数仓作为两大“数据集散地”,能不能彼此整合一下,让数据流动起来,少点重复建设呢?

比如,让“数仓”在进行数据分析的时候,可以直接访问数据湖里的数据(Amazon Redshift Spectrum是这么干的)。再比如,让数据湖在架构设计上,就“原生”支持数仓能力(DeltaLake是这么干)。
正是这些想法和需求,推动了数仓和数据湖的打通和融合,也就是当下炙手可热的概念:Lake House。
 到底什么才是真正的Lake House?
到底什么才是真正的Lake House?
Lake House,坊间通常称之为“湖仓一体”,而Amazon Web Services则叫做“智能湖仓”。
Lake House架构最重要的一点,是实现“湖里”和“仓里”的数据/元数据能够无缝打通,并且“自由”流动。
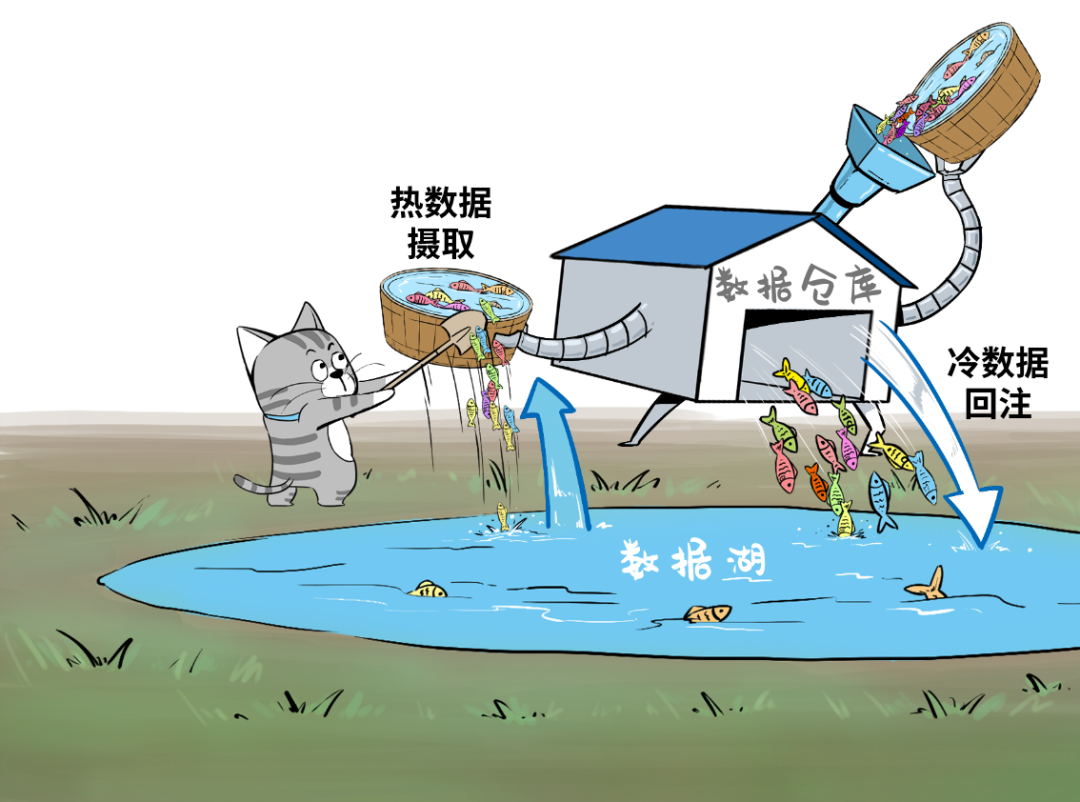
湖里的“新鲜”数据可以流到仓里,甚至可以直接被数仓使用,而仓里的“不新鲜”数据,也可以流到湖里,低成本长久保存,供未来的数据挖掘使用。
为了实现这个目标,Amazon Web Services推出了Redshift Spectrum,打通了数仓对数据湖的直接访问,能够高效查询S3数据湖当中的EB级数据。

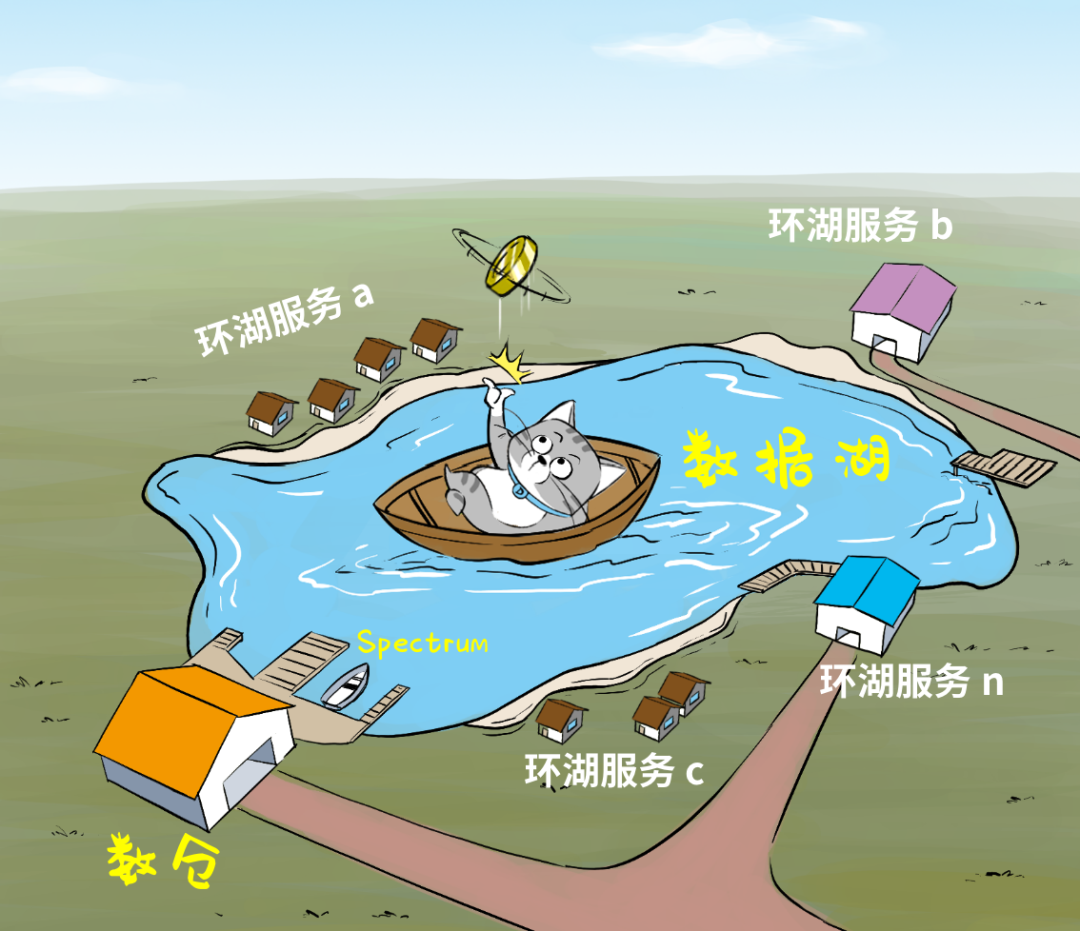
“Spectrum”是智能湖仓的核心组件,被称为“Lake House引擎”,它可以在湖与仓之间架起数据流动的管道↓
➊可以将数据湖中最近几个月的“热数据”摄取到数仓中;
➋反过来,也可以轻松将大量冷门历史数据从数仓转移至成本更低廉的数据湖内,同时这些移到湖里的数据,仍然可以被Redshift数仓查询使用;
➌处理数仓内的热数据与数据湖中的历史数据,生成丰富的数据集,全程无需执行任何数据移动操作;
➍生成的新数据集可以插入到数仓中的表内,或者直接插入由数据湖托管的外部表中。
做到这一步,基本上算是 get 到了Lake House的精髓,“湖仓一体”初见端倪。
但是,在实际业务场景下,数据的移动和访问,不仅限于数仓和数据湖之间,搜索引擎服务、机器学习服务、大数据分析服务……,都涉及到数据在本地(本系统)和数据湖之间的移动,以及数据在不同服务之间的移动。
数据积累得越多,移动起来就越困难,这就是所谓的“数据重力”。
所以,Lake House不仅要把湖、仓打通,还要克服“数据重力”,让数据在这些服务之间按需来回移动:入湖、出湖、环湖……
把数据湖和数据仓库集成起来只是第一步,还要把湖、仓以及所有其他数据处理服务组成统一且连续的整体,这就是Amazon Web Services为何把自家的Lake House架构称为“智能湖仓”,而非“湖仓一体”。
 “湖仓一体”只是开局,智能湖仓才是终极
“湖仓一体”只是开局,智能湖仓才是终极
智能湖仓并非单一产品,它描述的是一种架构。
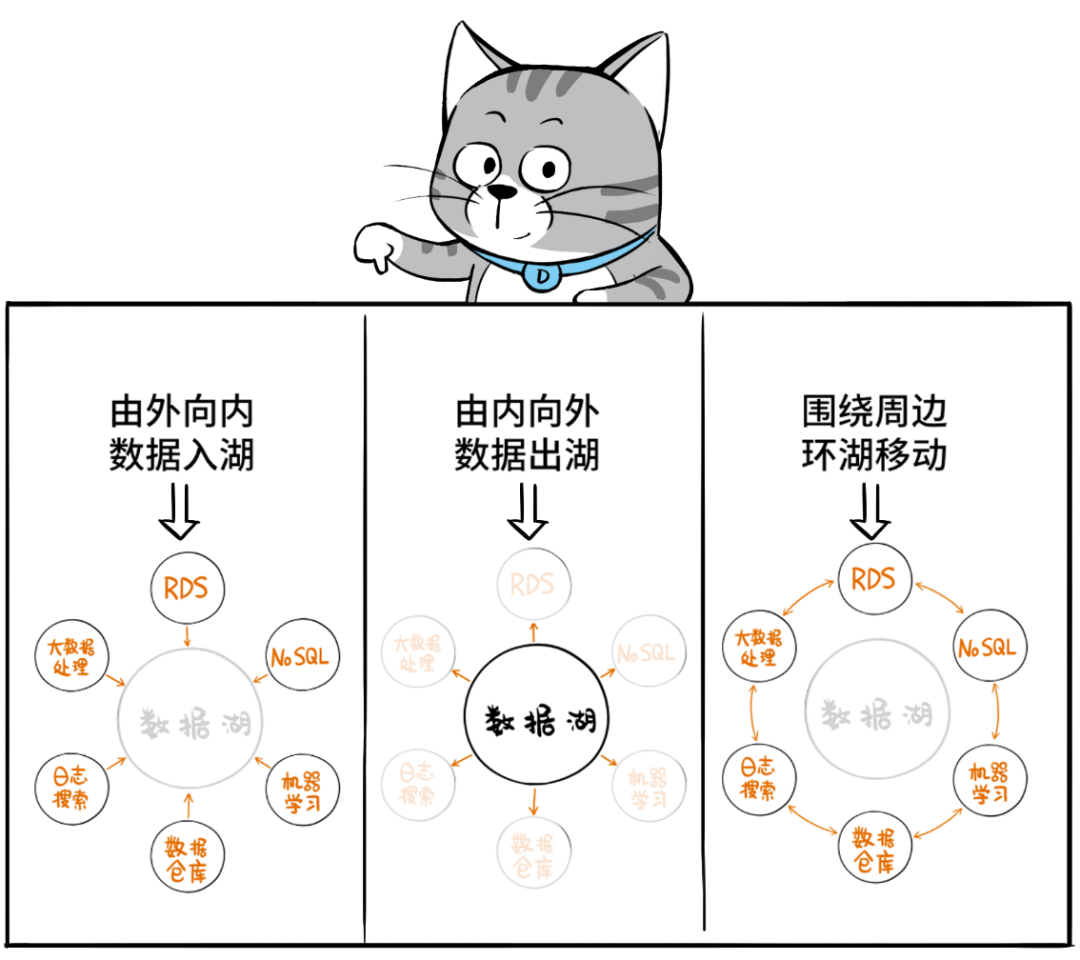
这套架构,以数据湖为中心,把数据湖作为中央存储库,再围绕数据湖建立专用“数据服务环”,环上的服务包括了数仓、机器学习、大数据处理、日志分析,甚至RDS和NOSQL服务等等。
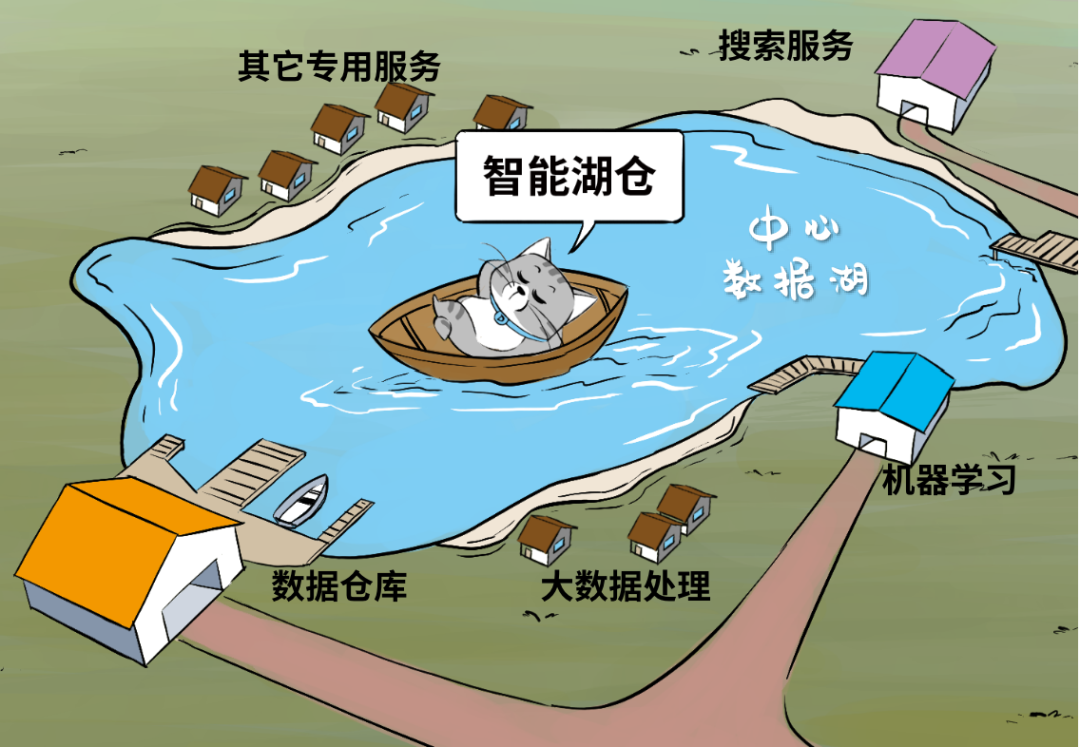
大家“环湖而饲”,既可以直接操纵湖内数据,也可以从湖中摄取数据,还可以向湖中回注数据,同时环湖的服务彼此之间也可以轻松交换数据。
任何热门的数据处理服务,都在湖边建好了,任何对口的数据都能召之即来、挥之则去。依靠这种无缝集成和数据移动机制,用户就能从容地用对的工具从对的数据中,挖出干货!
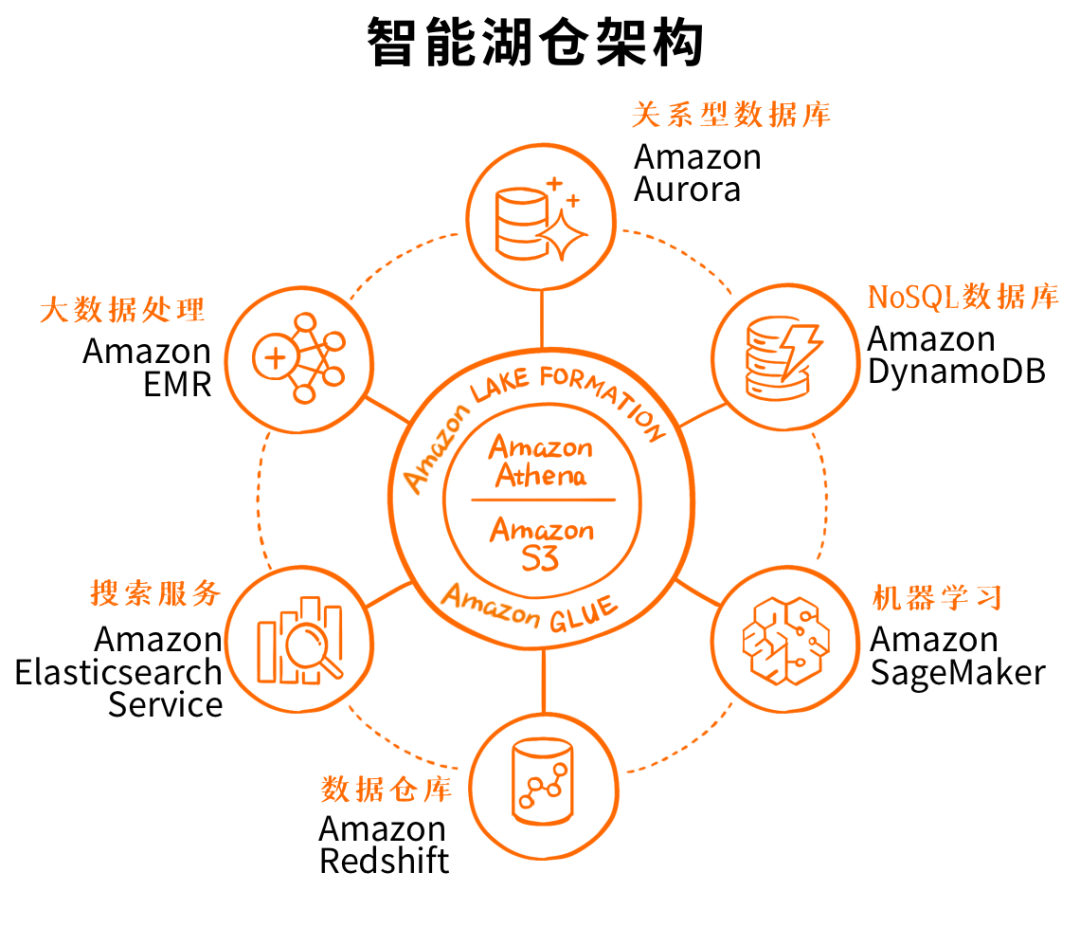
上面这张图看着就更加明白一些,中间是湖,周边集成了全套的云上数据服务,然后还有Lake Formation、Glue、Athena以及前面重点提到的Redshift Spectrum这些工具,来实现数据湖的构建、数据的管理、安全策略以及数据的移动。
如果我们再从数据获取到数据应用的完整流程来看,这些产品又是如何各司其职的呢?
Amazon Web Services官方给出了智能湖仓的参考架构↓
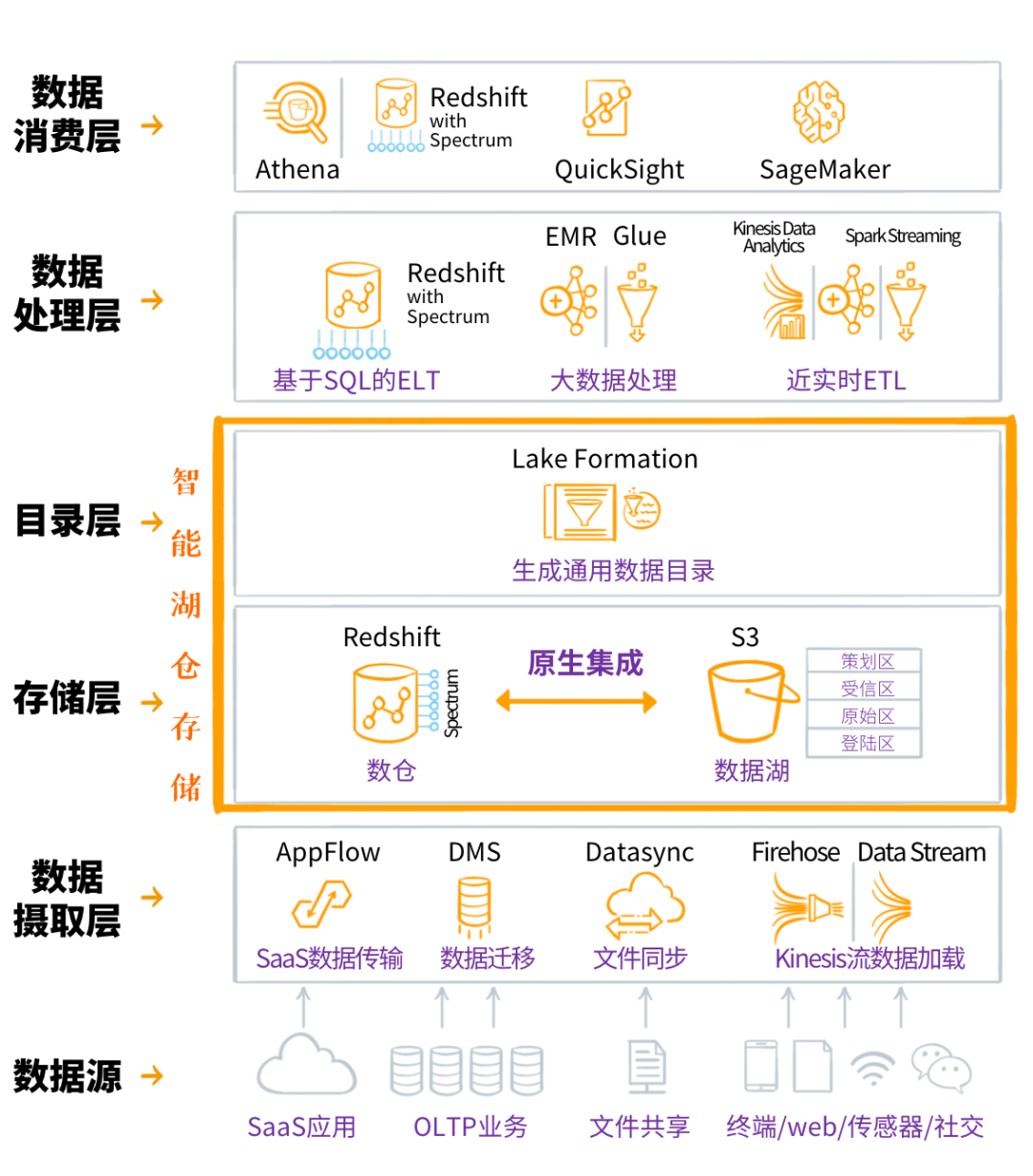
这个六层架构,从数据源定义、数据摄取和入湖入仓,到湖仓打通与集成,再到数据出湖、数据处理和数据消费,一气呵成,各种云上数据服务无缝集成在一起。
数据从各种源头“流入”到智能湖仓存储中,又按需流出,被处理、被消费。
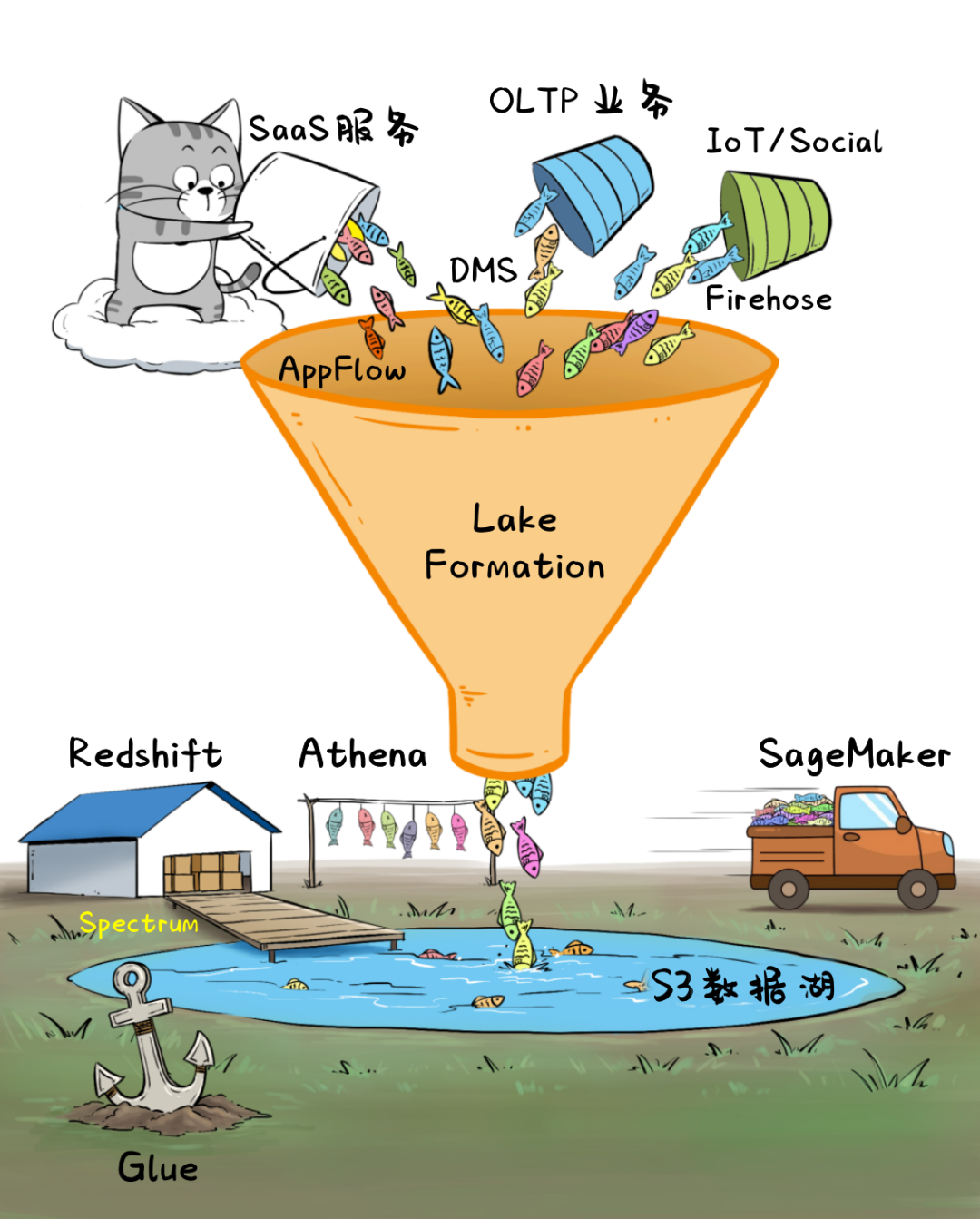
在“智能湖仓”架构下,企业可以轻松汇集和保存海量业务数据,并随心所欲地调用各种数据服务,用于BI、可视化分析、搜索、建模、特征提取、流处理等等,未来新的数据源、新的分析方法,也可以快速应对。
同时,数据湖的存储底座S3成本低廉并有近乎无限的扩展性,“湖边”大量的数据分析和处理的服务又是无长期成本的Serverless架构,企业“入坑”智能湖仓之后,完全没有后顾之忧。
不得不说,Amazon Web Services先知先觉,他们在“挖”数据湖的时候,就准备好了智能湖仓的图纸,用户的数据湖建成,智能湖仓竟然不知不觉也水到渠成了,没有翻云覆雨,不需要推倒重建。
我们甚至可以认为,“智能湖仓”架构是比所谓“数据中台”更能落地和务实的“中台”,如果数据中台是个饼,那智能湖仓就是把饼“烹熟烤香”的锅~
一入“湖仓”美如画,安心“淘金”不拉胯!
RECOMMEND
推荐阅读

01
《数据库系统:设计、实现与管理(基础篇)(原书第6版)》

作者:[英]托马斯 M. 康诺利(Thomas M. Connolly)
卡洛琳 E. 贝格(Carolyn E. Begg)
译者:宁洪 贾丽丽 张元昭
《数据库系统:设计、实现与管理(进阶篇)(原书第6版)》

作者:[英]托马斯 M. 康诺利(Thomas M. Connolly)
卡洛琳 E. 贝格(Carolyn E. Begg)
译者:宁洪 李姗姗 王静
推荐理由
本书是数据库领域的经典畅销著作,被世界多所大学选为教材,同时被广大技术人员和管理者人员视为必读书。本书作者曾在工业界致力于数据库系统的设计,后进入学术界精耕于教学,深谙专业人士和非专业人士在使用和学习数据库时的痛点。因此,本书采用这两类读者都易于接受和理解的方式,全面介绍数据库设计、实现和管理的基本理论、方法和技术。本书中文版分为“基础篇”和“进阶篇”,分别对应原书第一~五部分和第六~九部分。

02
《数据库系统实现(第2版)》

作者:(美) Hector Garcia-Molina
Jeffrey D. Ullman
Jennifer Widom
译者:杨冬青 吴愈青 包小源 唐世渭 等
推荐理由
本书是关于数据库系统实现方面内容最为全面的著作之一,是美国斯坦福大学计算机科学专业数据库系列课程第二门课程的指定教材。书中从数据库实现者的角度对数据库系统实现原理进行了深入阐述,并具体讨论了数据库管理系统的三个主要成分——存储管理器、查询处理器和事务管理器的实现技术。

03
《数据库系统基础教程(原书第3版)》

作者:(美)Jeffrey D. Ullman 、Jennifer Widom
译者:岳丽华 金培权 万寿红 等
推荐理由
本书由美国斯坦福大学知名计算机科学家Jeffrey Ullman和Jennifer Widom合作编写。书中介绍了核心DBMS概念、理论和模型,描述了如何使用抽象语言和SQL查询与更新DBMS。在介绍了SQL扩展内容(包括嵌入式SQL程序设计和对象关系特征)后,又介绍了使用XML的系统。设计语言包括XML模式,查询语言包括XPath和XQuery。

04
《数据库系统概念(原书第6版)》

作者:(美)Abraham Silberschatz,HenryF.Korth,S.Sudarshan
译者:杨冬青 李红燕 唐世渭 等
推荐理由
数据库系统概念的殿堂级作品!夯实数据库理论基础,增强数据库技术内功的必备之选!对深入理解数据库,深入研究数据库系统,深入操作数据库都具有极强的指导作用!

05
《数据库管理:大数据与小数据的存储、管理及分析实战》

作者:[比利时]维尔弗里德·勒玛肖
赛普·凡登·布鲁克
巴特·巴森斯
译者:李川 林旺群 郭立坤 龚勋 何军 等
推荐理由
全面涵盖基础理论与新兴热点,培养下一代数据管理人才的必选书目
全面覆盖知识点,从传统技术到大数据新兴趋势均有涉及,包括数据仓库、商务智能、数据集成、数据质量、数据治理、大数据和数据分析等。

06
《数据库系统内幕》

推荐理由
本书从数据库开发者角度,对现代数据库技术进行了全景式解读,完全不拘泥于任何一款数据库系统,也不偏袒任何一种数据库的类型或特性。

07
《企业数据湖》

推荐理由
企业数据平台化运营利器,赋能企业构建复杂大数据解决方案。本书旨在帮助你选择正确的大数据技术并使用Lambda架构模式来为企业构建自己的数据湖。

08
《数据仓库(原书第4版)》

推荐理由
本书被誉为数据仓库的“圣经”,第4版涵盖了数据仓库新技术,保持了在这一领域的先锋地位,详尽地讲述了数据仓库的基本概念、基本原理,以及建立数据仓库的方法和过程。


扫码关注【华章计算机】视频号
每天来听华章哥讲书

更多精彩回顾
书讯 | 6月书讯 | 初夏,正好读新书
书单 | 8本书助你零基础转行数据分析岗
干货 | 鸿蒙OS2面世,一本书了解“现代操作系统”!
收藏 | 终于有人把Scrapy爬虫框架讲明白了
上新 | 河马书来了!线上实验领域的“圣经”火热预售中
赠书 | 【第59期】架构师成长必读书








 京公网安备 11010802041100号
京公网安备 11010802041100号