目录
数据库就是一个以某种有组织的方式存储的数据集合。
简单的说,数据库(database)就是一个存放数据的仓库,这个仓库是按照一定的数据结构(数据结构是指数据的组织形式或数据之间的联系)来组织、存储的,我们可以通过数据提供的多种方法来管理数据库里的数据。
好处:
我们可以理解为,数据库就是一种特殊的文件,其中存储着需要的数据。
rdbms即关系数据库管理系统(relational database management system)
oracle、mysql、ms sql server、sqlite
关系型数据库:数据库里面的数据全部存在数据表中,而这些表在存储的过程中,各自之间有内在联系。因为这种联系,我们称这样的数据库叫"关系型数据库"
容易理解,二维表结构
使用方便,通用的sql语言使得操作关系型数据库非常方便,便于复杂的查询
支持事务等复杂的数据操作功能
nosql(nosql = not only sql ),意即"不仅仅是sql"。
mongodb,redis
数据之间无关系,容扩展
结构简单,具有非常高的读写性能,在大数据量下,同样表现优秀
无需事先建立字段,随时可以存储自定义的数据格式
例: 一个学生表,(表、字段、列、行)
| 学号 | 姓名 | 性别 |
|---|---|---|
| 1 | 小明 | 男 |
| 2 | 小红 | 女 |
| 3 | 大白 | 男 |
| 4 | 小白 | 男 |
mysql 是一个关系型数据库管理系统,由瑞典 mysql ab 公司开发,目前属于 oracle 旗下公司。mysql 最流行的关系型数据库管理系统,在 web 应用方面 mysql 是最好的 rdbms (relational database management system,关系数据库管理系统) 应用软件之一。
mysql 软件采用了双授权政策(本词条“授权政策”),它分为社区版和商业版,由于其体积小、速度快、总体拥有成本低,尤其是开放源码这一特点,一般网站软件的开发都选择 mysql 作为网站数据库。
mysql是一种客户端/服务器端(c/s)的软件,我们要学会如何如何安装服务器端的mysql,还需要学会如何利用客户端工具操作mysql数据,常用的客服端工具有: 命令行、pycharm-database、navicat等
官网:
下载:
所用mysql文件下载
链接: https://pan.baidu.com/s/1fpr0ips-xhccf6dquubkxg 提取码: yzmj
mysql -uroot -p密码 命令行链接 mysql status; 查看数据状态信息 exit、quit 退出数据库连接 show databases; 显示所有的数据库 create database data charset=utf8; 新创建一个数据库 use 数据库名; 选择要编辑的数据库,例如是data,则语句就是 use data; select database(); 查看当前在哪个数据库下 show tables; 展示数据库下所有的表 c 当你输入有误,想重打的时候可以试试加个 c 取消 source 数据库文件名.sql; 导入数据库到mysql中 可以把别人事先创建好的数据库文件导入到当前电脑的mysql中 desc `表名`; 查看表结构信息
键盘的上下键,可以快速滚回我们之前输入的代码。
sql,指结构化查询语言,全称是 structured query language,是一种 ansi(american national
standards institute 美国国家标准化组织)标准的计算机语言,可以让我们可以处理数据库。
sql语句主要分为:
1、每一条语句都要以 " ; " 英文分号结尾 2、sql语句不区分关键字的大小写,但是建议属于sql语句的语法规则用大写,自建的表、字段小写。 3、字符串跟日期类型的值都要以 单引号括起来 4、单词之间需要使用半角的空格隔开 5、我们可以通过使用 `` 反引号来括起表名跟字段名,避免跟关键字冲突,但是应该数据库设计就已经避免这个问题了。
select 字段1,字段2 from 表名 从指定表中查询所有数据的字段1和字段2信息
select 字段1,字段2 from 表名 where 字段名 = 字段值;
1、查找学生表的姓名跟年龄 select name,age from student; 查找课程表中的id,课程名称和教室编号 select id,course,address from course; 2、查找学生表所有的信息 selet * from student; 3、为字段名设置别名,简化字段名 select name as n,age as a from student; 4、使用条件查询想要的数据,查学号为14的学生姓名 select name from student where id = 14; 使用条件查询名字叫'吴杰'的学生姓名和年龄 select name,age from student where name='吴杰'; 注意:应该根据你的实际需求查询所要的字段值,而不是使用 * ,使用这个效率很低。
| 运算符 | 含义 |
|---|---|
| and | 并列,如果组合的条件都是true,返回true |
| or | 或者,如果组合的条件其一是true,返回true |
| not | 取反,如果条件是false,返回true |
1、查询年龄大于10岁小于18岁的学生 select * from student where age<18 adn age>10; 查询年龄小于18岁 或者性别是女的学生 select name,age,description as des from student where age<18 or sex=2; 查询年龄在18-22之间的女生信息(班级、姓名、年龄和性别) select class,name,age,sex from student where age>=18 and age<=22 and sex=2; 查询309班的所有男生信息(姓名、年龄、个性签名) select name,age,description from student where class=309 and sex=1; 查询306班、305班、304班的学生信息(姓名、年龄、个性签名) select name,age,description from student where class=304 or class=305 or class=306;
判断字段值是否在指定区间内
1、 查询年龄在18-22之间的学生(班级、姓名、年龄和性别) select class,name,age,sex from student where age between 18 and 22; 2、 当然,反过来查的话,查询18-22岁以外的学生 select class,name,age,sex from student where not age between 18 and 22;
| 运算符 | 含义 |
|---|---|
| = | 等于,判断字段名的值是否等于指定值 |
| <>、!= | 不等于 |
| <= | 小于或等于 |
| >= | 大于或等于 |
| < | 小于 |
| > | 大于 |
1、查询小于等于19岁的学生 select * from student where age<=18;
in 运算符 允许在 where 子句中规定多个值。
1、查询304,305和306班级的学生信息 select name,class,age from student where class in (304,305,306) 2、查询学号为 1、3、5的学生信息 select * from student where id in(1,3,5);
like 运算符 允许我们针对只知道部分字符串的情况下,查找所有的字符串,进行模糊查找
% 匹配任意多个字符 陈%
_ 匹配任意一个字符 陈__
1、查询姓陈的学生 select * from student where name like &#39;陈%&#39;; 查找名字以风字结尾的学生 select * from student where name like &#39;%风&#39;; 2、查询姓名中带林的学生 select * from student where name like &#39;%林%&#39;; 查询姓名是2个文字组成的学生 select * from student where name like &#39;__&#39;;
avg 返回指定列的平均值
count 返回指定列中非null值的个数
min 返回指定列的最小值
max 返回指定列的最大值
sum 返回指定列的所有值之和
聚合运算都是写在select 后面
select count("字段") from 表名 where 条件;
1、查询305班所有的学生数量 select count(id) from student where class=305; # 上面查询结果中,字段会变成count(&#39;id&#39;),可以使用as别名来处理一下。 select count(id) as c from student where class=305; 2、查询所有学生中最小的年龄 select min(age) from student; 3、查询302班中所有学生的平均年龄。 select avg(age) from student where class=302;
group by子句, 可以对表进行分组,常常与聚合函数一起使用
group by 字段名,当前这个字段名在表中出现多少个不同的字段值,那么查询结果就会有多少个组。
1、查询表中有多少男女学生 select sex,count(sex) from student group by sex; 2、查询学生表中各个年龄段的学生数量 select age,count(name) from student group by age; 3、查询各个班级的人数各是多少 select class,count(id) from student group by class;
order by 子句,对查询结果排序
asc表示升序(从小到大),为默认值,
desc为降序(从大到小)
1、对309班级的学生的年龄进行倒叙排序 select name,age,sex from student where class=309 order by age desc;
补充:
结果排序可以多个字段排序
例如:对学生的年龄进行降序排列。
select id,name,sex from student order by age desc,id asc limit 10; # 上面就有2个排序的字段, # 系统会优先针对 age 进行降序排列, # 当age的值一致的时候,系统会按照id进行升序排列。
limit 子句,可以对查询出的结果进行数量限制,往往我们不想一次取出所有的数据
limit有两个使用方式:
limit后面跟着 一个参数 表示限制结果的数量
limit后面跟诊 两个参数,第一个参数表示取数据的开始下标[在表中下标从0开始],第二个参数表示限制结果的数量。
select * from student limit 3; // 等同于 limit 0,3 # 下标 0,1,2 select * from student limit 3,3; // 等同于 limit 3,3 # 下标 3,4,5 select * from student limit 6,3; // 等同于 limit 6,3 # 下标 6,7,8
1、查询出年级最大的10个学生 select * from student order by age desc,id asc limit 10; 2、从所有学生中,查询年级最大的下标从10-19的学生出来。 select id,name,age from student order by age desc,id asc limit 10,10;
limit 主要用于在项目开发中的分页功能实现。
添加一名记录
insert into 表名 (字段1,字段2,字段3,....) values (字段值1,字段值2,字段值3,....); # 也可以省略不写字段名,但是数据的数据项必须和表结构的字段数量保持一致,查询表结构使用 desc 表名; insert into 表名 values (字段值1,字段值2,字段值3,....);
insert into student (id,name,sex,class,age,description) values (101,&#39;刘德华&#39;,1,508,17,&#39;给我一杯忘情水~&#39;); # 上面的字段,如果是全部字段,那么字段这一块内容可以省略不写。 # 例如,我们再次添加一个学生,如果省略了字段名,那么填写数据的数据项必须和表结构的字段数量保持一致。 insert into student values (102,&#39;张学友&#39;,1,508,17,&#39;爱就像头饿狼~&#39;,0,0,0); 添加多名学生 insert into student(name,sex,class,age,description) values (&#39;周润发&#39;,1,508,17,&#39;5个a~&#39;),(&#39;周杰伦&#39;,1,508,17,&#39;给我一首歌的时间~&#39;); 注: 自动增长跟有默认值的字段可以不写。
update 表名 set 字段1=字段值1,字段2=字段值2 where 条件 # 更新操作会影响数据的不可逆操作,所以更新的时候,一定要谨慎,添加条件。如果没有条件, # 或者条件的判断结果一直是true,则整个表所有的记录都会被更新。
修改学生的姓名,年龄 update student set age=8 where id=104;
delete from 表名 where 条件
删除一个学生 delete from student where id=104; 注: 修改跟删除数据都要记得加条件。
delete from table 删除整个表的内容[没有条件则表示删除整个表所有数据]
drop tbale 表名 删除整个表 删除学生表 drop table student; 删除学生表的数据 delete from student; truncate table 清空/重置表[表还在数据被清空了] create database 数据库名 charset=utf8; 创建数据库 drop database 数据库名 删除数据库[一定要谨慎操作]
create table 表名( 字段名1 数据类型 约束规则, 字段名2 数据类型, 字段名3 数据类型, ..... 字段名n 数据类型, primary key(一个 或 多个 字段名) ); # 上面语句中,最后一个小句子后面不能有英文逗号出现,前面的小句子必须加上英文逗号。
定义字段名,表名、数据库名、规范:
在64个字符以内,建议简短,如果不够清晰,可以使用前缀。
不能是关键字或者保留字
采用变量命名方式[ 由字母、数字、下划线组成,不能以数字开头 ]
数据库里面的数据在保存时,也要通过数据类型来告诉系统,这些数据的用途,所以也会有对应的数据类型:
数值类型[整数和浮点数]、字符串 和 日期
是否唯一[数据在同一个表中的同一列中是否可以出现多个]
是否无符号[约束当前是否可以填写负数,有符号可以填写,无符号不能填写。]
是否设置为当前表的主键[主键是一个表记录不同行数据之间的唯一字段,这个字段必须是唯一的]
是否自动增长[添加数据的时候,如果不填写这个字段,那么这个字段会自动在之前已有的值基础上+1填充]
设置默认值[ 添加/修改数据时,如果值没有填写或者被清空了,采用指定的值作为字段值 ]
是否可以填写空(null,等同于python里面的none)值
创建班级表
create table classes( id int unsigned auto_increment primary key not null, name varchar(10) );
例如:创建学生表[原来的数据库中已经存在了一张表,所以练习案例的时候注意,建议新建一个数据库来创建]
mysql> create table student( -> id int unsigned auto_increment not null, # 字段名 整型 无符号 自动增长 不能是空, -> name char(10), # 字段名 字符串(长度:10) -> sex int default 1, # 字段名 整型 默认值为 1, -> class int, # 字段名 整型 -> age int, # 字段名 整型 -> description text, # 字段名 文本[可以填写65535个字符] -> primary key(id) # 设置主键(id) 每个表必须都有主键 -> ) engine=innodb charset=utf8; # 表引擎=innodb 编码=utf8;[后面学习,先用] query ok, 0 rows affected (0.02 sec) # 出现这句话,表示创建表成功 mysql> desc student; # 显示表结构 +-------------+------------------+------+-----+---------+----------------+ | field | type | null | key | default | extra | +-------------+------------------+------+-----+---------+----------------+ | id | int(10) unsigned | no | pri | null | auto_increment | | name | char(10) | yes | | null | | | sex | int(11) | yes | | 1 | | | class | int(11) | yes | | null | | | age | int(11) | yes | | null | | | description | text | yes | | null | | +-------------+------------------+------+-----+---------+----------------+ 6 rows in set (0.00 sec)
自己动手创建一个课程表
create table `course`( id int unsigned not null auto_increment, course char(20) not null, lecturer int unsigned, address int unsigned, primary key(id) ) engine=innodb charset=utf8;
数据库操作记录:
mysql> create table `course`( -> id int unsigned not null auto_increment, -> course char(20) not null, -> lecturer int unsigned, -> address int unsigned, -> primary key(id) -> ) engine=innodb charset=utf8; query ok, 0 rows affected (0.01 sec)
show create table 表名 g;
mysql> show create table course g; *************************** 1. row *************************** table: course create table: create table `course` ( `id` int(10) unsigned not null auto_increment, `course` char(20) not null, `lecturer` int(10) unsigned default null, `address` int(10) unsigned default null, primary key (`id`) ) engine=innodb default charset=utf8 1 row in set (0.00 sec)
修改表-添加字段
alter table 表名 add 列名 类型; 例: alter table students add birthday datetime;
修改表-修改字段:重命名版
alter table 表名 change 原名 新名 类型及约束; 例: alter table students change birthday birth datetime not null;
修改表-修改字段:不重命名版
alter table 表名 modify 列名 类型及约束; 例: alter table students modify birth date not null;
修改表-删除字段
alter table 表名 drop 列名; 例: alter table students drop birthday;
删除表
drop table 表名; 例: drop table students;
查看表的创建语句
show create table 表名g; 例: show create table studentg;
了解数据的数据类型可以通过以下语句来查看和使用帮助:
mysql> ? 查询关键词 # 如果,我们希望了解关于int的可以填值范围 mysql> ? int
使用数据类型的原则:够用就行,尽量使用取值范围小的,而不用大的,这样可以更多的节省存储空间
'ab '| 类型 | 字节大小 | 有符号范围(signed) | 无符号范围(unsigned) |
|---|---|---|---|
| tinyint | 1 | -128 ~ 127 | 0 ~ 255 |
| smallint | 2 | -32768 ~ 32767 | 0 ~ 65535 |
| mediumint | 3 | -8388608 ~ 8388607 | 0 ~ 16777215 |
| int/integer | 4 | -2147483648 ~2147483647 | 0 ~ 4294967295 |
| bigint | 8 | -9223372036854775808 ~ 9223372036854775807 | 0 ~ 18446744073709551615 |
| 类型 | 使用 | 描述 |
|---|---|---|
| decimal(m,d) | decimal(5,2),表示只能有5个数字, 其中最多设置2个数字在小数点后面 可以存储的数值:1000.5,123.56 不可以存储的数值:1000.51,100000, 1.345 |
十进制小数,用于表示商品的价格 |
开发中,一般qq号或者手机号都是使用字符串来保存的
| 类型 | 字节大小 | 示例 |
|---|---|---|
| char | 0-255 | 定长字符串,类型:char(3) 输入 ‘ab’, 实际存储为’ab ‘, 输入’abcd’ 实际存储为 ‘abc’ |
| varchar | 0-255 | 不定长字符串,类型:varchar(3) 输 ‘ab’,实际存储为’ab’, 输入’abcd’,实际存储为’abc’ |
| text | 0-65535 | 大文本 |
在5.5版本的mysql以后,varchar类型可以存储的数据,可以达到65535个字符。
| 类型 | 字节大小 | 示例 | 场景 |
|---|---|---|---|
| date | 4 | ‘2020-01-01’ | 日期记录,会员过期时间,活动时间范围 |
| time | 3 | ’12:29:59′ | 餐厅的餐牌 |
| datetime | 8 | ‘2020-01-01 12:29:59’ | 会员登录时间 |
| year | 1 | ‘2017’ | 电影的年份…. |
| timestamp | 4 | ‘1970-01-01 00:00:01’ utc ~ ‘2038-01-01 00:00:01’ utc | 基本用不上 |
datetime 和 timestamp,很多时候,我们会使用程序中的时间戳来代替,后面在数据库中保存时设置字段的类型是数值型,这样的话,可以节省存储空间,同时还可以提高数据的读取速度。
说明:虽然外键约束可以保证数据的有效性,但是在进行数据的crud(create增加、update修改、delete删除、read查询)时,都会降低数据库的性能,所以不推荐使用,那么数据的有效性怎么保证呢?答:可以在python的逻辑层进行判断控制[用代码控制]
现阶段不需要独立完成数据库设计,但是要注意积累一些这方面的经验
就是我们根据开发需求,要保存到数据库中作为一张表存在的事物。实体的名称最终会变成表名
实体会有属性,实体的属性就是描述这个事物的内容,实体的属性最终会在表中作为字段存在。
实体与实体之间会存在关系,这种关系一般就是根据三范式提取出来的主外键。
范式理论【在总结了经验以后,得出规范我们数据库设计的一些理论】
三范式: 1. 数据要保证不可分割. 2. 数据不能冗余(多余). 3. 数据不能重复.重复的数据,新建一张表存储.
经过研究和对使用中问题的总结,对于设计数据库提出了一些规范,这些规范被称为范式(normal form)
目前有迹可寻的共有8种范式,一般需要遵守3范式即可
◆ 第一范式(1nf):强调的是列的原子性,即列不能够再分成其他几列。
考虑这样一个表:【联系人】(姓名,性别,电话) 如果在实际场景中,一个联系人有家庭电话和公司电话,那么这种表结构设计就没有达到 1nf。要符合 1nf 我们只需把列(电话)拆分,即:【联系人】(姓名,性别,家庭电话,公司电话)。1nf 很好辨别,但是 2nf 和 3nf 就容易搞混淆。
◆ 第二范式(2nf):首先是 1nf,另外包含两部分内容,一是表必须有一个主键;二是没有包含在主键中的列必须完全依赖于主键,而不能只依赖于主键的一部分。
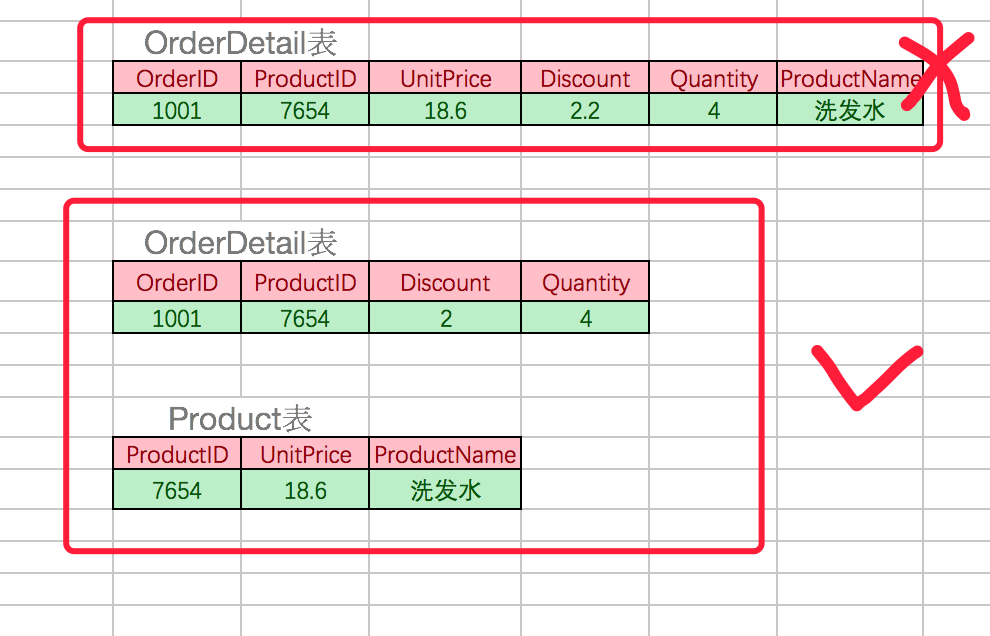
考虑一个订单明细表:【orderdetail】(orderid,productid,unitprice,discount,quantity,productname)。 因为我们知道在一个订单中可以订购多种产品,所以单单一个 orderid 是不足以成为主键的,主键应该是(orderid,productid)。显而易见 discount(折扣),quantity(数量)完全依赖(取决)于主键(oderid,productid),而 unitprice,productname 只依赖于 productid。所以 orderdetail 表不符合 2nf。不符合 2nf 的设计容易产生冗余数据。
可以把【orderdetail】表拆分为【orderdetail】(orderid,productid,discount,quantity)和【product】(productid,unitprice,productname)来消除原订单表中unitprice,productname多次重复的情况。
◆ 第三范式(3nf):首先是 2nf,另外非主键列必须直接依赖于主键,不能存在传递依赖。即不能存在:非主键列 a 依赖于非主键列 b,非主键列 b 依赖于主键的情况。
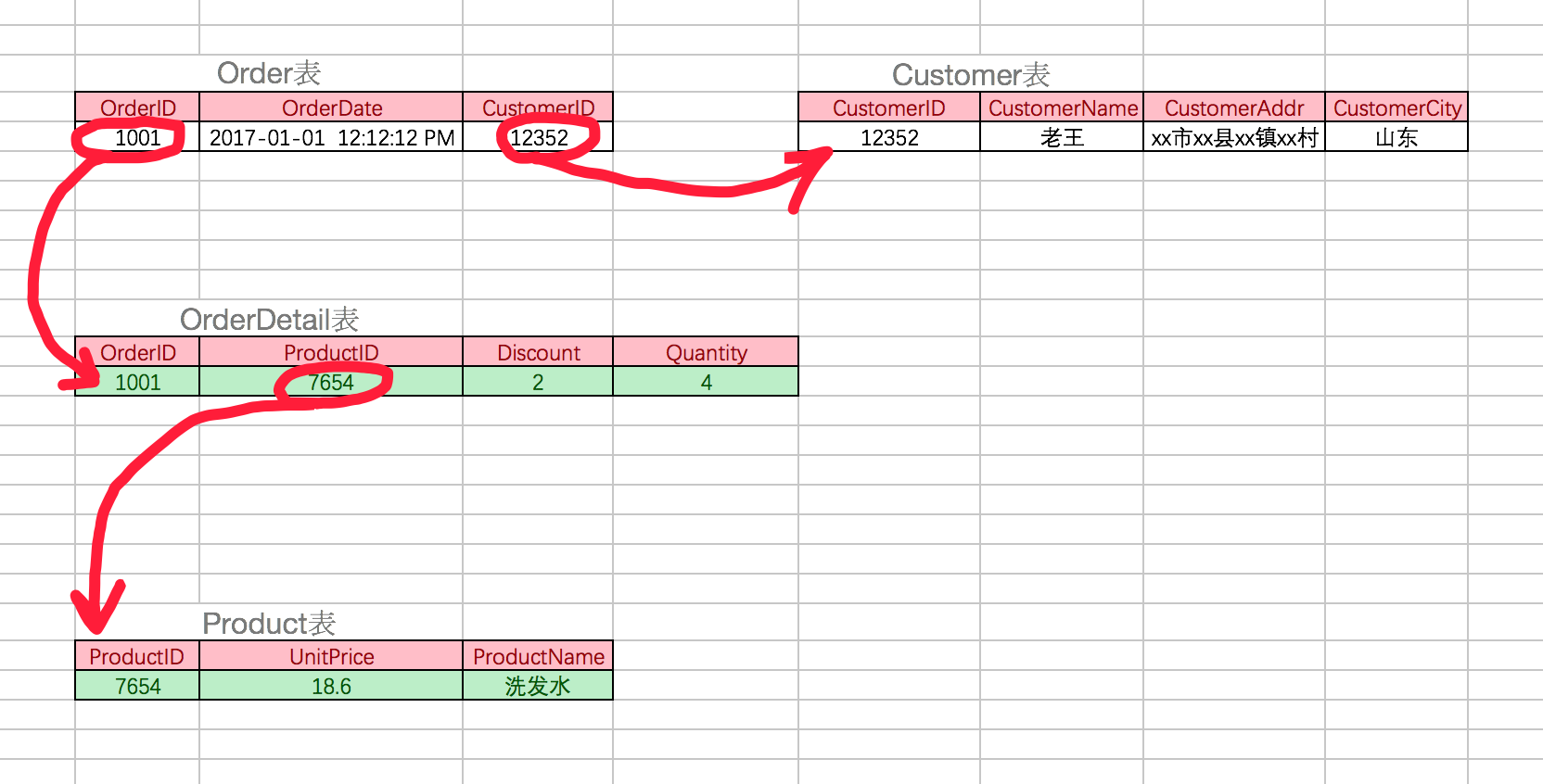
考虑一个订单表【order】(orderid,orderdate,customerid,customername,customeraddr,customercity)主键是(orderid)。 其中 orderdate,customerid,customername,customeraddr,customercity 等非主键列都完全依赖于主键(orderid),所以符合 2nf。不过问题是 customername,customeraddr,customercity 直接依赖的是 customerid(非主键列),而不是直接依赖于主键,它是通过传递才依赖于主键,所以不符合 3nf。 通过拆分【order】为【order】(orderid,orderdate,customerid)和【customer】(customerid,customername,customeraddr,customercity)从而达到 3nf。 *第二范式(2nf)和第三范式(3nf)的概念很容易混淆,区分它们的关键点在于,2nf:非主键列是否完全依赖于主键,还是依赖于主键的一部分;3nf:非主键列是直接依赖于主键,还是直接依赖于非主键列。


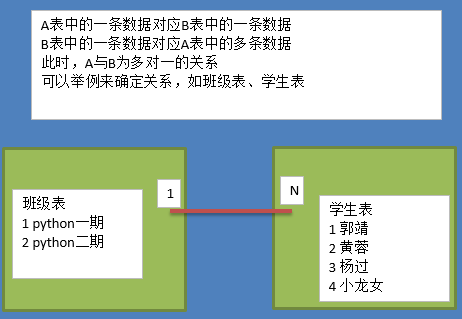
实体之间会因为引用相互引用字段而存在关系,这种关系一般有三种:
1-1
1-n
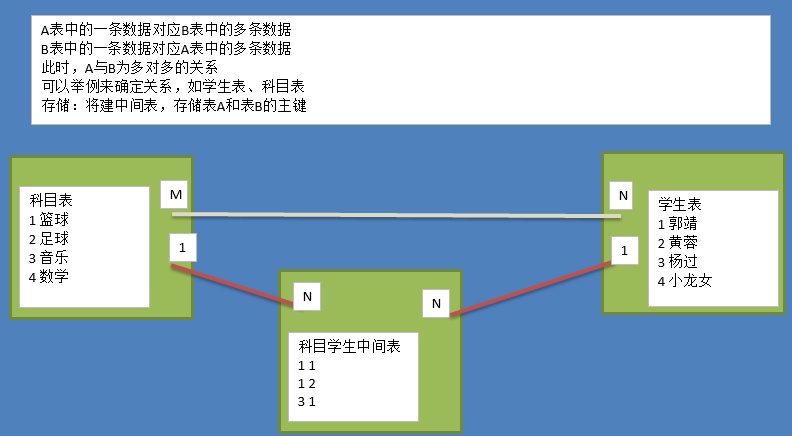
n-m[ 多对多一般表现为2个 1对多 ]
实体a对实体b为1对1,则在表a或表b中创建一个字段,存储另一个表的主键值

实体a对实体b为1对多:在表b中创建一个字段,存储表a的主键值
实体a对实体b为多对多:新建一张表c,这个表只有两个字段,一个用于存储a的主键值,一个用于存储b的主键值
想一想:举些例子,满足一对一、一对多、多对多的对应关系
“`
mysqldump –uroot –p 数据库名 > python.sql; # 按提示输入mysql的密码
mysql -uroot –p 新数据库名11 消除重复行
- 在select后面列前使用distinct可以消除重复的行
- distinct的使用需要放在第一个字段的位置,针对第一个字段进行去重。
select distinct 列1,... from 表名; 例: select distinct gender from students;例如,统计下在学生表的所有的学生班级
select distinct class from student;12 where条件的运算符进阶
空判断
注意:null与”是不同的
判空is null
例1:查询没有填写个性签名的学生
select * from student where description is null;
- 判非空is not null
例2:查询填写了个性签名的学生
select * from student where description is not null;例3:查询填写了身高的男生
select * from student where description is not null and sex=1;运算符优先级
- 优先级由高到低的顺序为:小括号,not,比较运算符,逻辑运算符
- and比or先运算,如果同时出现并希望先算or,需要结合()使用
13 连接查询[连表查询、多表查询]
当查询结果的列来源于多张表时,需要将多张表连接成一个大的数据集,再选择合适的列返回
mysql支持三种类型的连接查询,分别为:
内连接查询(inner join)
查询的结果为两个表匹配到的数据
使用内连接,必须保证两个表都会对应id的数据才会被查询出来。
select 字段1,字段2... from 主表 inner join 从表 on 主表.主键=从表.外键例如:查询学生的信息[ 成绩、名字、班级 ]
我们给学生表添加一个学生信息,然后使用该学生的主键id来连表查询成绩、名字和班级。
insert into student (name,sex,age,class,description) values (&#39;刘德华&#39;,1,17,406,&#39;&#39;); select achievement,name,class from student as a inner join achievement as b on a.id=b.sid where id=101; # 上面语句因位该学生只在学生表student中有数据,而成绩表中没有数据,所以使用内连接,连表查询的结果是 empty set (0.00 sec)同样,如果从表有数据,而主表没有数据,则使用内连接查询一样无法查询到结果。
#例如,添加一个成绩记录,是不存在学生 insert into achievement (sid,cid,achievement) values (102,10,85); select achievement,name,class from student as a inner join achievement as b on a.id=b.sid where id=102;右连接查询(right join)
只要从表有数据,不管主表是否有数据,都会查询到结果。[以从表的结果为主]
查询的结果为两个表匹配到的数据,右表特有的数据,对于左表中不存在的数据使用null填充
select 字段1,字段2... from 主表 right join 从表 on 主表.主键=从表.外键例如,上面的成绩id为102的学生, 我们使用右连接查询。
select achievement,name,class from student as a right join achievement as b on a.id=b.sid;左连接查询(left join)
只要主表有数据,不管从表是否有数据都会被查询出来。
查询的结果为两个表匹配到的数据,左表特有的数据,对于右表中不存在的数据使用null填充
语法
select * from 表1 left join 表2 on 表1.列 = 表2.列例如,使用左连接查询学生表与成绩表,查询学生姓名及分数
select achievement,name,class from student as a left join achievement as b on a.id=b.sid; 等同于 select achievement,name,class from achievement as b right join student as a on a.id=b.sid;总结:
三种连表查询,最常用的是 left join,然后inner join保证数据的一致性。右连接基本上都是使用左连接代替。多表关联
select 表.字段1,表.字段2,表.字段3..... from 主表 left join 从表1 on 主表.主键=从表1.外键 left join 从表2 on 主表.主键=从表2.外键 # 这里和从表2连接的on条件看实际情况,也会出现从表1.主键=从表2.外键的情况 left join 从表3 on 主表.主键=从表3.外键 # 这里可以是(从表1或从表2).主键=从表2.外键的情况 left join ...多表查询的缺点
多表查询的效率,性能比单表要差。
多表查询以后,还会带来字段多了会引起字段覆盖的情况、
主表student 从表1 achievement 从表2 course
name xxx name
上面三张表如果连表,则出现主表的name覆盖从表2的name这种情况。
上面两个问题:
- 把多表查询语句可以替换成单表查询语句【需要优化的情况】
- 把重复的字段名,分别使用as来设置成别的名称。
例如,查询白杨的班级、id、年龄和课程名称以及对应课程的成绩
select a.id,a.class,a.age,c.course,b.achievement from student as a left join achievement as b on a.id=b.sid left join course as c on c.id=b.cid where a.name=&#39;白杨&#39;;练习:
查询id为20的学生的考试总分.
```sqlselect sum(b.achievement) sum # 有时候as可以不写
from student as a
left join achievement as b on a.id=b.sid
where a.id=20;
“`查询305班级所有学生的课程名称、课程成绩、以及对应课程的授课老师。
1. 先查305的学生信息 2. 再查305的学生成绩 3. 再查305的学生成绩对应的课程 4. 最后查305的学生成绩对应的课程的老师select a.name,b.achievement,course,d.name from student as a left join achievement as b on a.id=b.sid left join course as c on b.cid=c.id left join lecturer as d on d.id=c.lecturer_id where a.class=305;上面代码的效果: +--------+-------------+----------------+--------+ | name | achievement | course | name | +--------+-------------+----------------+--------+ | 谭季同 | 100.0 | photoshop | 唐老师 | | 谭季同 | 79.0 | 负载均衡 | 杜老师 | | 谭季同 | 78.5 | flask项目 | 白老师 | | 白瀚文 | 73.0 | go | 陈老师 | | 白瀚文 | 65.0 | webpy | 林老师 | | 白瀚文 | 86.0 | 数据分析 | 郑老师 | | 白瀚文 | 60.0 | api接口 | 宋老师 | | 晁然 | 0.0 | flask | 陈老师 | | 晁然 | 78.0 | python网络编程 | 江老师 | | 晁然 | 78.0 | html5 | 丘老师 | | 白素欣 | 81.0 | django项目 | 易老师 | | 白素欣 | 90.0 | python | 黄老师 | | 白素欣 | 39.0 | nginx | 曹老师 | | 庄晓敏 | 82.5 | nginx | 曹老师 | | 庄晓敏 | 68.0 | python | 黄老师 | | 庄晓敏 | 100.0 | api接口 | 宋老师 | +--------+-------------+----------------+--------+14 单表的连表查询[自关联查询]
核心就是把一张表看做2张表来操作
# 建表: create table area( id smallint not null auto_increment comment &#39;主键id&#39;, name char(30) not null comment &#39;地区名称&#39;, pid smallint not null default 0 comment &#39;父级地区id&#39;, primary key (id) ) engine=innodb charset=utf8; insert into area (name,pid) values (&#39;广东&#39;,0),(&#39;深圳&#39;,1),(&#39;龙岗&#39;,2),(&#39;福田&#39;,2),(&#39;宝安&#39;,2);格式:
select 字段1,字段2... from 主表(当前表) as a left join 从表(当前表) as b on a.主键=b.外键查找深圳地区的子地区,sql代码:
# 主表看成保存深圳的表, # 从表看成保存深圳子地区的表 select b.id,b.name from area as a left join area as b on a.id=b.pid where a.name=&#39;深圳&#39;;15 子查询
在一个 select 语句中,嵌入了另外一个 select 语句, 那么被嵌入的 select 语句称之为子查询语句
格式:
select 字段 from 表名 where 条件(另一条查询语句)主查询
主要查询的对象,第一条 select 语句
主查询和子查询的关系
- 子查询是嵌入到主查询中
- 子查询是辅助主查询的,要么充当条件,要么充当数据源
- 子查询是可以独立存在的语句,是一条完整的 select 语句
例如:查询406班上大于平均年龄的学生
使用 子查询:
- 查询406班学生平均年龄
- 查询大于平均年龄的学生
查询406班级学生的平均身高
select name,age from student where age > (select avg(age) as avg from student where class=406) and class=406;16 having
group by 字段 having 条件;过滤筛选,主要作用类似于where关键字,用于在sql语句中进行条件判断,过滤结果的。
但是与where不同的地方在于having只能跟在group by 之后使用。
练习:查询301班级大于班上平均成绩的学生成绩信息(name,平均分,班级)。
# 先求301班的平均成绩 select avg(achievement) as achi from student as a left join achievement as b on a.id=b.sid where class=301; # 判断301中的每个人平均成绩大于上面的到的平均成绩 select name,avg(achievement) from student as a left join achievement as b on a.id=b.sid where class=301 group by name having avg(achievement) > (select avg(achievement) as achi from student as a left join achievement as b on a.id=b.sid where class=301);17 select查询语句的完整格式
select distinct 字段1,字段2.... from 表名 as 表别名 left join 从表1 on 表名.主键=从表1.外键 left join .... where .... group by ... having ... order by ... limit start,count
- 执行顺序为:
- from 表名[包括连表]
- where ….
- group by …
- select distinct *
- having …
- order by …
- limit start,count
- 实际使用中,只是语句中某些部分的组合,而不是全部
我们之前学习的source也是一种恢复方式,但是两种使用有一个区别。就是
mysql 命令这种方式,可以远程 恢复,而source这种只能本地电脑恢复。
mysql -hip地址 -uroot -p密码
18 python操作mysql
pymysql 一般使用这个
mysqldb
需要了解更多数据库技术:MySQL入门,都可以关注数据库技术分享栏目—编程笔记
安装pymysql模块
pip install pymysql使用pymysql模块操作数据库
import pymysql # from pymysql import * # 创建和数据库服务器的连接 connection cOnn= pymysql.connect(host=&#39;localhost&#39;,port=3306,user=&#39;root&#39;,password=&#39;root123456&#39;, db=&#39;student&#39;,charset=&#39;utf8&#39;) # 创建游标对象 cursor = conn.cursor() # 中间可以使用游标完成对数据库的操作 sql = "select * from student;" # 执行sql语句的函数 返回值是该sql语句影响的行数 count = cursor.execute(sql) print("操作影响的行数%d" % count) # print(cursor.fetchone()) # 返回值类型是元祖,表示一条记录 # 获取本次操作的所有数据 for line in cursor.fetchall(): print("数据是%s" % str(line)) # 关闭资源 先关游标 cursor.close() # 再关连接 conn.close()执行语句
#执行sql,更新单条数据,并返回受影响行数 result = cursor.execute("sql语句") #插入多条,并返回受影响的函数,例如批量添加 result2 = cursor.executemany("多条数据") #获取最新自增id new_id = cursor.lastrowid获取结果
#获取一行 result1 = cursor.fetchone() #获取多行[参数可以设置指定返回数量] result2 = cursor.fetchmany(整型) #获取所有 result3 = cursor.fetchall()操作数据
#提交,保存新建或修改的数据,如果是查询则不需要 conn.commit() # 写在execute()之后






 京公网安备 11010802041100号 | 京ICP备19059560号-4 | PHP1.CN 第一PHP社区 版权所有
京公网安备 11010802041100号 | 京ICP备19059560号-4 | PHP1.CN 第一PHP社区 版权所有 

