作者:手机用户2502857731 | 来源:互联网 | 2023-10-12 13:39
堆的结构,我们可以分为物理中的真实结构和脑海中的逻辑结构,换句话来说,堆其实在实现上是一种结构,但是我们分析的时候是另一种结构。
好了,不卖关子了。
堆在实现的时候其实是数组结构,但是我们在分析的时候在脑海中应该是完全二叉树结构。
那我们先说一下什么是完全二叉树。
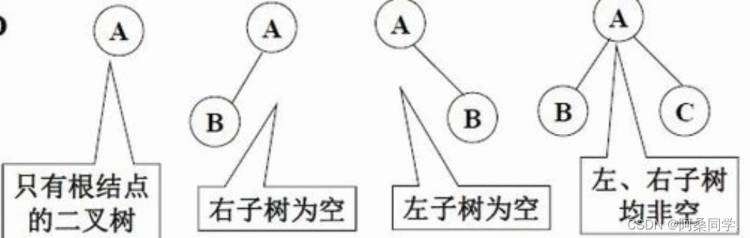
完全二叉树
对于完全二叉树,就是二叉树的节点要么是满的,要么二叉树是不满的,但是它也是从左到右依次变满的状态。
举个例子来说:
如果它是孤零零的一个节点,那它也是完全二叉树,因为它只有一层,并且在这一层中是满的。 如果它是两个节点,那么第二层的节点处在第一层节点的左节点上,右子树为空(从左到右依次变满),这样的也叫作完全二叉树。 如果它是两个节点,那么第二层的节点处在第一层节点的右节点上,左子树为空,这样的就不能叫做完全二叉树结构。 堆
堆在实现的时候,并没有用二叉树的结构,这只是我们脑海中堆应该有的一个概念。
那堆到底是怎么实现的呢?我们脑海中的树是如何具体实现的呢?
堆其实可以用一个从0出发的连续数组来描述的。
那问题又来了,从一段连续的数组到二叉树它又有什么对应的关系呢?
首先,二叉树中某个节点下标为 i ,它的左子节点下标为 2i+1 ,右子节点下标是 2i + 2 ,它的父节点下标为( i - 1 )/ 2 那当然,数组默认是从下标 0 开始使用的,上面的对应关系也只是适用于从下标0 开始。 如果数组从下标1 开始使用呢?二叉树中某个节点下标为 i ,它的左子节点下标就变成了 2i ,右子节点下标变成 2i +1 ,它的父节点下标变为 i / 2 举个例子 堆的分类
堆分为大根堆和小根堆 大根堆:在这个完全二叉树中,以某个节点起始的整棵树,树中的最大值就是该节点 小根堆:在这个完全二叉树中,以某个节点起始的整棵树,树中的最小值就是该节点 heapInsert操作(插入)和heapify操作(删除) 大根堆为例
两个思考问题
1. 当用户给了一个数组时,用户逐渐向数组中添加数字,我们该如何调整使其变成大根堆呢?
逐渐向数组添加数字,当添加的数字( i 位置),小于它的父节点(( i - 1 )/ 2)时,直接添加就可以了。 当添加的数字( i 位置),大于它的父节点(( i - 1 )/ 2)时,就需要进行交换了。将 i 位置的新添加的数字与它的父节点(( i - 1 )/ 2)的数字进行交换。 通过上述方法,就能保证在数组的成长过程中,是成长出的每一步都是大根堆。 这个向数组中逐步添加数字调整形成大根堆的过程就叫做heapInsert 代码如下: public void heapInsert ( int [ ] arr , int index) { while ( arr[ index] > arr[ ( index- 1 ) / 2 ] ) { swap ( arr, index, ( index- 1 ) / 2 ) ; = ( index- 1 ) / 2 ; } }
2. 调整为大根堆后,进行popmax()操作(减堆操作,减去最大值)后,我们又该如何调整使其变成大根堆呢?
开辟一个临时变量max,将该大根堆中的最大值赋值给max,交换最后一位与最大值的位置(将最末尾的数字写入下标为0 的位置) 注意:这里最末尾的数字不一定是最小值。只是最后一个数字 代码如下: public void heapify ( int [ ] arr, int index , int heapsize) { int left = index * 2 + 1 ; while ( left< heapsize) { int largest = left+ 1 < heapsize && arr[ left+ 1 ] > arr[ left] ? left+ 1 : left; = arr[ largest] > arr[ index] ? largest : index; if ( largest== index) { break ; } swap ( arr, largest, index) ; = largest; = index * 2 + 1 ; } }
关于堆,关键的也就是这两个操作heapInsert和heapify。清楚堆的这两个操作,对于堆排序就很容易理解了
堆排序
堆排序,简单来说,就是重复的heapify操作。再简单点,就是popmax操作。
举个例子来说。
假如用户给了一个数组[ 3 4 0 2 7 ],怎么进行堆排序呢?
我们上面讲到,当用户一个一个向数组中添加新的数字,我们可以使用heapInsert操作将其排成大根堆
现在用户给了我们数组中全部的数字,让我们排成大根堆,怎么做呢?
其实方法是一样的。我们自己一个一个加进堆中不就可以了!
对,这就是堆排序的第一步。
1. 先将整个数组变成大根堆结构 有效size = 1。先看第 0 位 - 第 0 位上是不是大根堆?[ 3 4 0 2 7 ]
此时 i = 0;只有 3 自己,当然,是大根堆。 有效size = 2。再看第 0 位到第 1 位呢?
不是大根堆,此时 i = 1;因为4的父节点(i-1)/2 =0 ,第 0 位为3 <4 小了怎么办? 我们就用 heapify 调整不就可以了 经过调整之后,数组就变为了[ 4 3 0 2 7 ] 有效size = 3。再往下,第 0 位到第 2 位呢?
是大根堆,此时 i = 2;因为 0 的父节点(i-1)/2 =0 ,第 0 位为 4 > 0 此时,数组为[ 4 3 0 2 7 ] 有效size = 4。第 0 位到第 3 位呢?
是大根堆,此时 i = 3;因为 2 的父节点(i-1)/2 =1 ,第 1 位为 3 > 2 此时,数组为[ 4 3 0 2 7 ] 有效size = 5。第 0 位到第 4 位呢?
是大根堆,此时 i = 4;因为 7 的父节点(i-1)/2 =1 ,第 1 位为 3 <7 用 heapify 调整, 子节点与父节点交换,交换完之后,数组为[ 4 7 0 2 3 ],此时是大根堆了吗? 当然还不是,我们在进行调整,子节点与父节点交换,交换完之后,数组为[ 7 4 0 2 3 ],OK,此时调整为了大根堆 2. 到这里,我们的堆排序第一步就完成了。我们的第二步就相当于做popmax操作 将最后一位与第 0 位进行交换,有效size=5-1=4 。 即切断树的最后一个分支[ 3 4 0 2 7 ],这里7并没有消失,仍在这里,只是7处于无效区中。[ 4 3 0 2 7 ] 继续让最后一位与0位置的数进行交换,有效size=4-1=3 。 即切断树的最后一个分支[ 2 3 0 4 7 ],这里4 7并没有消失,仍在这里,只是4 7处于无效区中。[ 3 2 0 4 7 ] 继续让最后一位与0位置的数进行交换,有效size=3-1=2 。 即切断树的最后一个分支[ 0 2 3 4 7 ],这里3 4 7并没有消失,仍在这里,只是3 4 7处于无效区中。[ 2 0 3 4 7 ] 继续让最后一位与0位置的数进行交换,有效size=2-1=1 。 即切断树的最后一个分支[ 0 2 3 4 7 ],这里2 3 4 7并没有消失,仍在这里,只是2 3 4 7处于无效区中。[ 0 2 3 4 7 ] 继续让最后一位与0位置的数进行交换,有效size=1-1=0 。此时停止,再看此时数组为[ 0 2 3 4 7 ],这就排好序了,结束。 这整个过程就是堆排序,先排成大根堆,然后popmax,当有效区为0时,顺序就排好了,这整个过程就叫做heapSort()
代码如下:
public void heapSort ( ) { if ( arr== null || arr. length< 2 ) { } for ( int i= 0 ; i< arr. length; i++ ) { heapInsert ( arr, i) ; } int heapSize= arr. length; swap ( arr, 0 , -- heapSize) ; while ( heapSize> 0 ) { heapify ( arr, 0 , heapSize) ; swap ( arr, 0 , -- heapSize) ; } } 堆排序的优化
上述代码中,我们使用heapInsert()操作,将用户所提供的数组排成大根堆。
这个时候,我先看最后一层以最后一层节点为头结点的树是不是大根堆?
因为只有一个数,所以,是大根堆。这一步,时间复杂度为O(N/2)
倒数第二层,以倒数第二层节点为头结点的树是不是大根堆?
这个时候,最糟糕的情况,我需要看的同时进行一步调整,这一步,时间复杂度为O(N/4)*2
倒数第三层,以倒数第三层节点为头结点的树是不是大根堆?
这个时候,最糟糕的情况,我需要看的同时进行两步调整,这一步,时间复杂度为O(N/8)*3T(N)=O(N/2)+O(N/4)*2+O(N/8)*3+。。。。T(N)=C*O(N)。 C=2
所以,当用户给出我们数组中全部的数时,我们完完全全的从底开始进行heapify操作要比一个一个的heapInsert操作要快
public void heapSort ( ) { if ( arr== null || arr. length< 2 ) { } for ( int i= arr. length; i>= 0 ; i-- ) { heapify ( arr, i, arr. length) ; } int heapSize= arr. length; swap ( arr, 0 , -- heapSize) ; while ( heapSize> 0 ) { heapify ( arr, 0 , heapSize) ; swap ( arr, 0 , -- heapSize) ; } } 综上
堆排序的整个过程为:























 京公网安备 11010802041100号
京公网安备 11010802041100号