文章导览
数据集简介
解决依赖
读取观察数据
提出问题
数据清洗建议
数据清洗
数据分析
1、数据集链接
数据来源于链家2019年在售房源项目,共3万+数据量,14个字段。
字段分别是:产权、关注、区域、单价、小区、年限、总价、户型、房屋编码、挂牌时间、朝向、楼层、装修情况、面积。
数据集地址链接:杭州链家2019 在售房源数据集 - Heywhale.com
2、解决依赖
## 解决依赖
# 解决pyplot的社死配色问题
!pip install brewer2mpl
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
plt.rcParams['font.sans-serif'] = ['SimHei']
plt.rcParams['axes.unicode_minus'] = False
import seaborn as sns
import warnings
warnings.filterwarnings('ignore')
import brewer2mpl
3、读取观察数据
## 读取数据
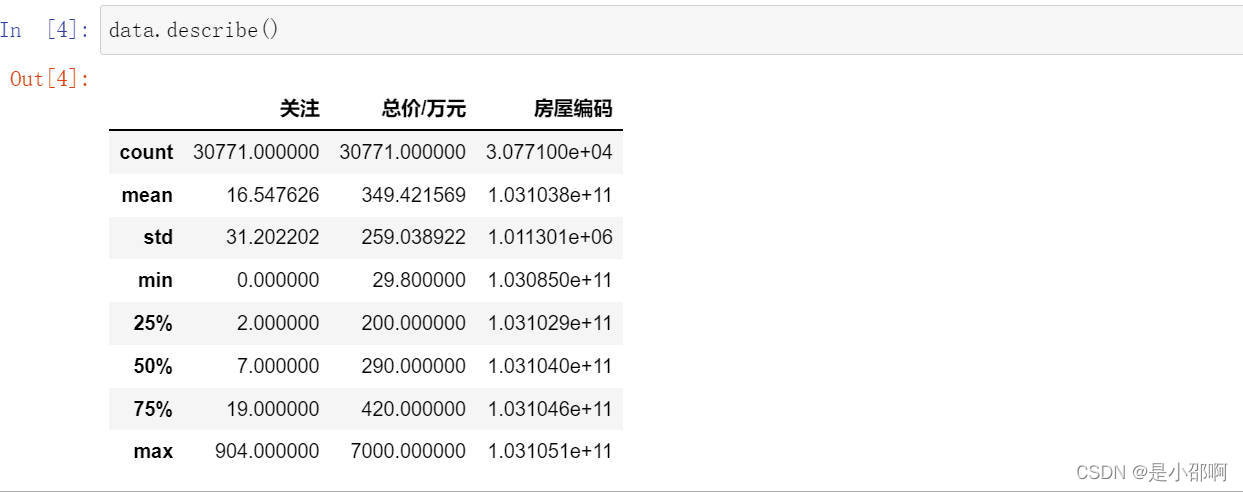
data = pd.read_csv("./house.csv")## 观察数据
data.head()
data.describe()
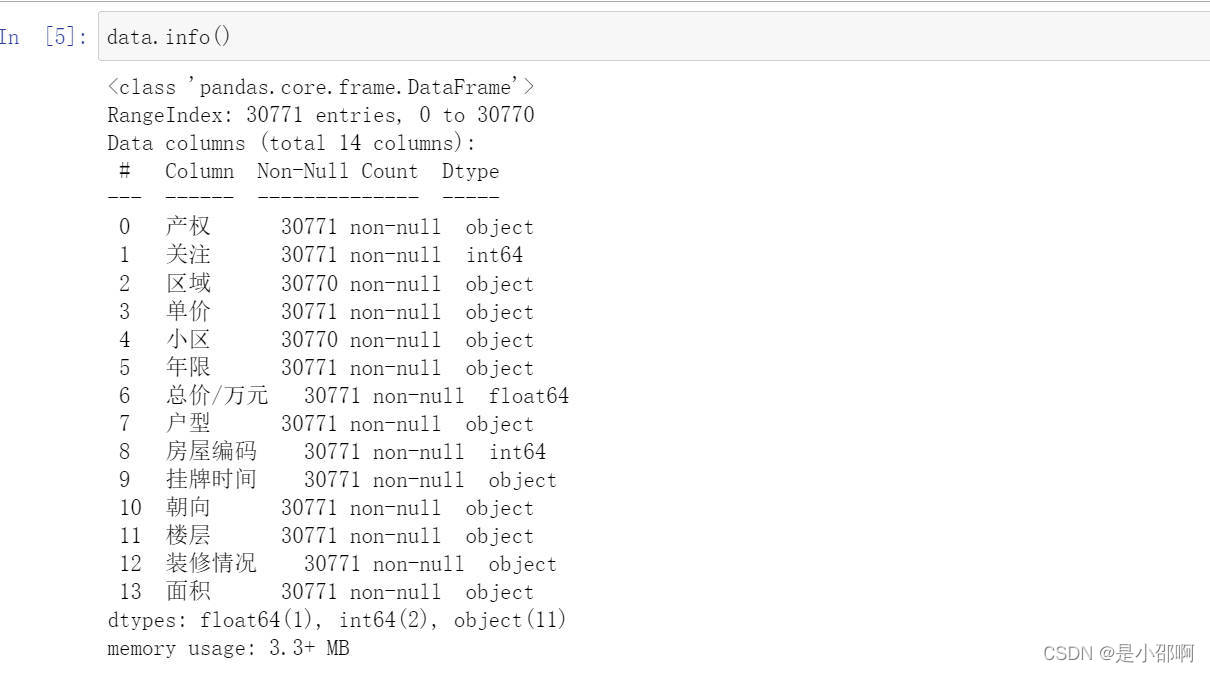
data.info()

4、提出问题
1)探索个数据之间的相关性
2)各区房源数量对比
3)各区平均总价对比
4)各区每平米单价对比
5)房源关注热度对比
6)不同户型关注热度对比
7)不同朝向关注热度对比
8)不同产权关注热度对比
9)不同楼层关注热度热度对比
10)装修程度对关注度的影响
11)全杭州关注度最高小区TOP10
由于数据集没有给出成交量,所以关注重点围绕关注度。
5、数据清洗建议
产权未知的删除
区域一列改成某某区形式
单价一列改成int64型
年限变成整数型,添加楼龄一列
挂牌时间无用,删掉列
户型拆分成室数、厅数两列
房屋编码无用删掉
表中67种朝向(看无语了。。)精简为6种
楼层改为楼层未知和层数两列
装修情况简单分为3种和其他
面积改成整数型
6、数据清洗
## 数据清洗#查看缺失
data.isnull().sum()
# 删除缺失
data.dropna(how="any",inplace=True)
# 处理产权特征-删除未知
data = data.loc[data["产权"]!="未知"]
# 处理区域特征-封装一个函数识别属于哪个区,将函数应用于该列
def location(x):if "临安" in x: return "临安市"elif "上城" in x: return "上城区"elif "下城" in x: return "下城区"elif "江干" in x: return "江干区"elif "拱墅" in x: return "拱墅区"elif "西湖" in x: return "西湖区"elif "滨江" in x: return "滨江区"elif "萧山" in x: return "萧山区"elif "余杭" in x: return "余杭区"elif "富阳" in x: return "富阳区"elif "钱塘" in x: return "钱塘新区"else: return "其他"data["区域"] = data["区域"].apply(location)
# 处理单价特征
data["单价"] = data["单价"].str.split("元").str[0]
data["单价"] = data["单价"].astype("int64")
# 处理年限特征
data["年限"] = data["年限"].str.split("年").str[0]
data = data.loc[data["年限"]!="未知"]
data["年限"] = data["年限"].astype("int64")
data.rename(columns={"年限":"建筑时间"},inplace=True)
data["建筑年龄"] = 2019-data["建筑时间"]
# 处理挂牌时间和房屋编码两特征
data.drop(["挂牌时间","房屋编码"],axis=1,inplace=True)
# 处理朝向特征
def windows(x):if "东南" in x:if x.count("南") > 1:if ("西南" in x) & ("南" not in x):return "东南"else:return "南"else:return "东南"elif "西南" in x:if x.count("南") >1:return "南"else:return "西南"elif "南" in x:return "南"elif "东" in x:return "东"elif "西" in x:return "西" else:return "北"data["朝向"] = data["朝向"].apply(windows)
data.rename(columns={"朝向":"窗户朝向"},inplace=True)
# 处理楼层特征
data["楼层位置"] = data["楼层"].str.split("/").str[0]
data["层数"] = data["楼层"].str.split("/").str[1]
del data["楼层"]
data = data.loc[data["楼层位置"].isin(["高楼层","中楼层","低楼层"])]
data["层数"] = data["层数"].str.extract("(\d+)").astype("int64")
# 处理装修程度特征
def fixtures(x):if "精装" in x: return "精装"elif "简装" in x: return "简装"elif "毛坯" in x: return "毛坯"else: return "其他"data["装修情况"] = data["装修情况"].apply(fixtures)
# 处理面积特征
data["面积"] = data["面积"].str.extract("([\d,.]+)").astype("float")
# 过滤异常值
data = data.loc[(data["总价/万元"] > 50) & (data["总价/万元"] <3000)]
data = data.loc[data["户型"] != "0室0厅"]
# 对列表重置索引
data.reset_index(drop=True,inplace=True)
7、数据分析
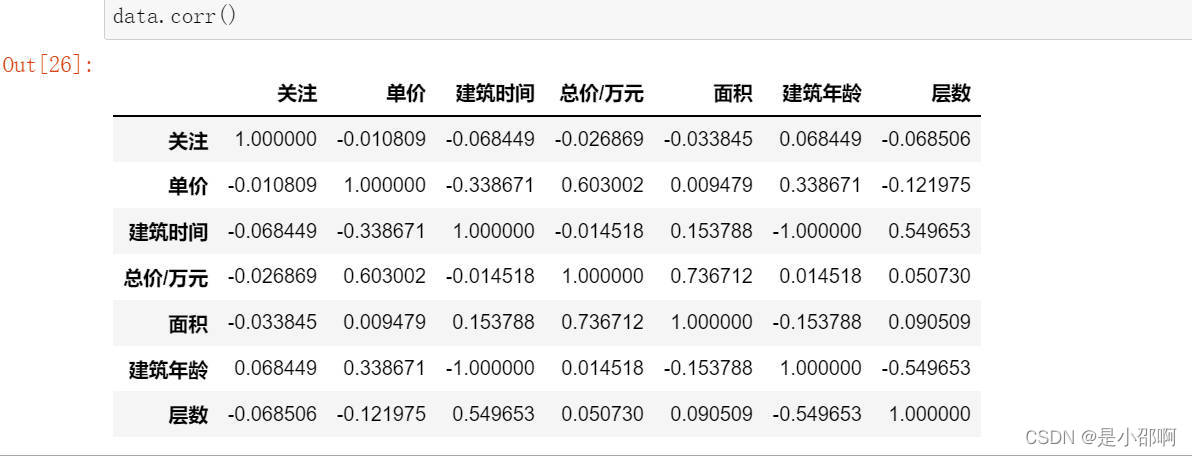
## 数据分析# 1各数据相关性分析
data.corr()
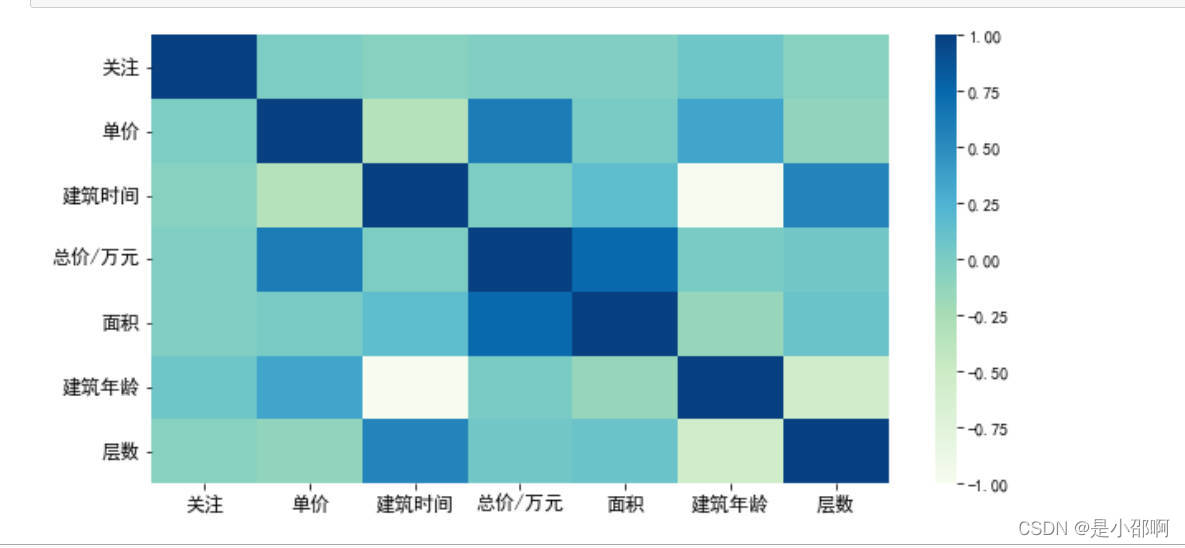
# 相关性图表的可视化
plt.figure(figsize=(10,5))
sns.heatmap(data.corr(),cmap="GnBu")
plt.xticks(fOntsize=12)
plt.yticks(fOntsize=12)
plt.show()
# 2各区房源数量对比
count_house = data.groupby("区域")["关注"].count().sort_values(ascending=False)
plt.figure(figsize=(10,5))
sns.barplot(count_house.index,count_house)
plt.title("各区域房源",fOntsize=14)
plt.ylabel("房源数量",fOntsize=12)
plt.xlabel("区域",fOntsize=12)
plt.xticks(rotation=30,fOntsize=12)
plt.show()
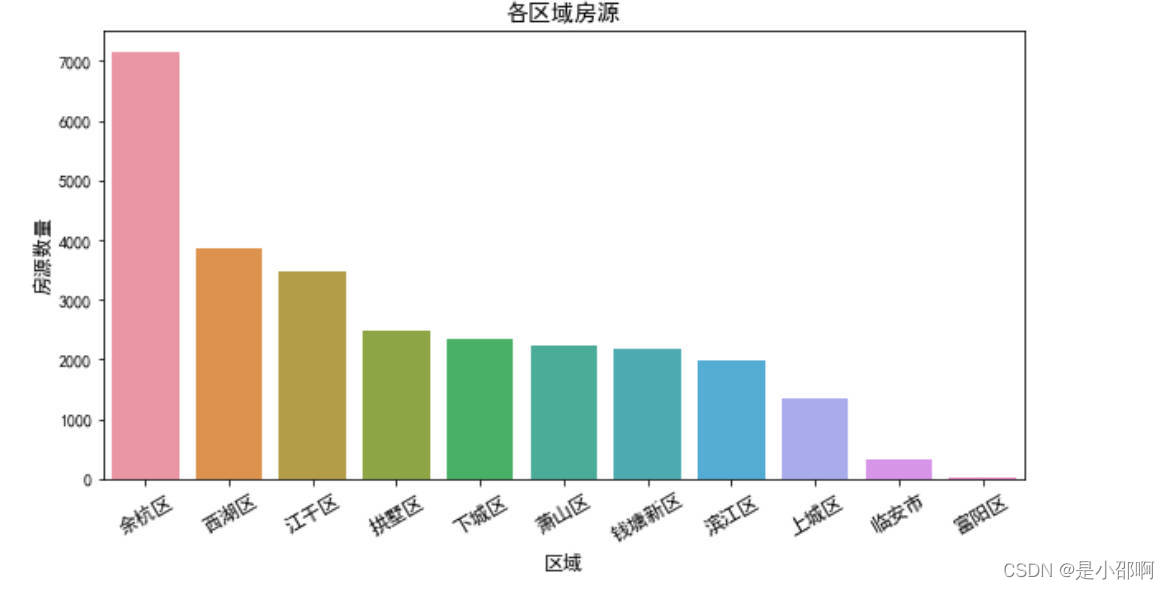
# 3各区平均总价对比
total_price = data.groupby("区域")["总价/万元"].mean().sort_values(ascending=False)
plt.figure(figsize=(10,5))
sns.barplot(total_price.index,total_price)
plt.title("各区总价对比",fOntsize=14)
plt.ylabel("总价格/万元",fOntsize=12)
plt.xlabel("区域",fOntsize=12)
plt.xticks(rotation=30,fOntsize=12)
plt.show()
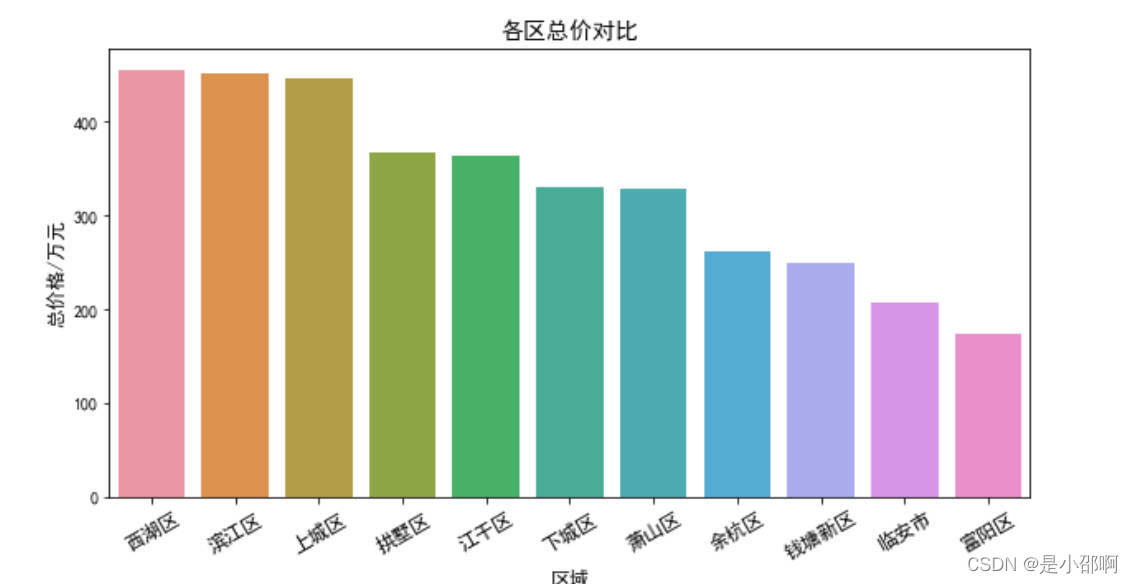
# 4各区每平米单价对比
price = data.groupby("区域")["单价"].mean().sort_values(ascending=False)
plt.figure(figsize=(10,5))
sns.barplot(price.index,price)
plt.title("各区平均单价对比",fOntsize=14)
plt.ylabel("每平米单价",fOntsize=12)
plt.xlabel("区域",fOntsize=12)
plt.xticks(rotation=30,fOntsize=12)
plt.show()
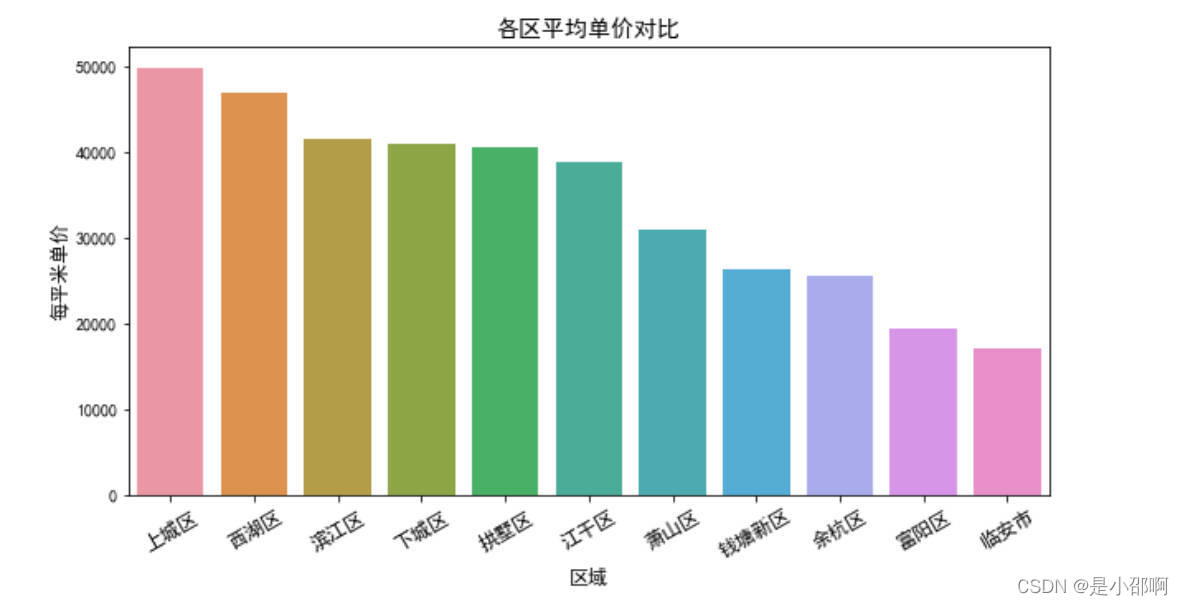
# 5各区房源关注热度对比
Attention = data.groupby("区域")["关注"].sum().sort_values(ascending=False)
plt.figure(figsize=(10,5))
sns.barplot(Attention.index,Attention)
plt.title("各区房源关注",fOntsize=14)
plt.ylabel("总关注度",fOntsize=12)
plt.xlabel("区域",fOntsize=12)
plt.xticks(rotation=30,fOntsize=12)
plt.show()
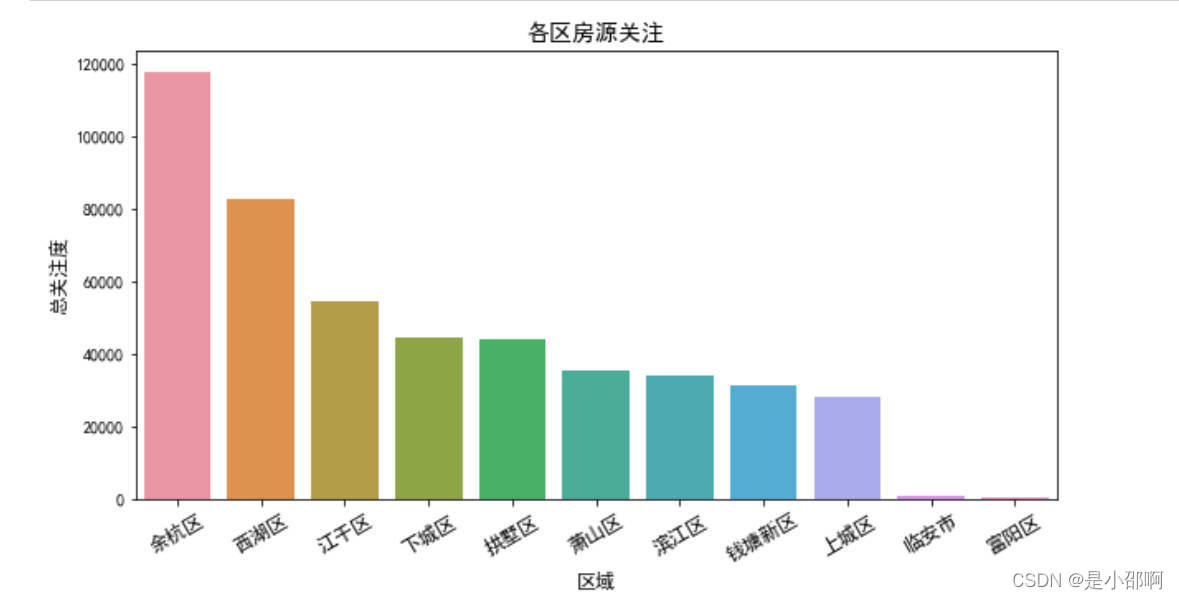
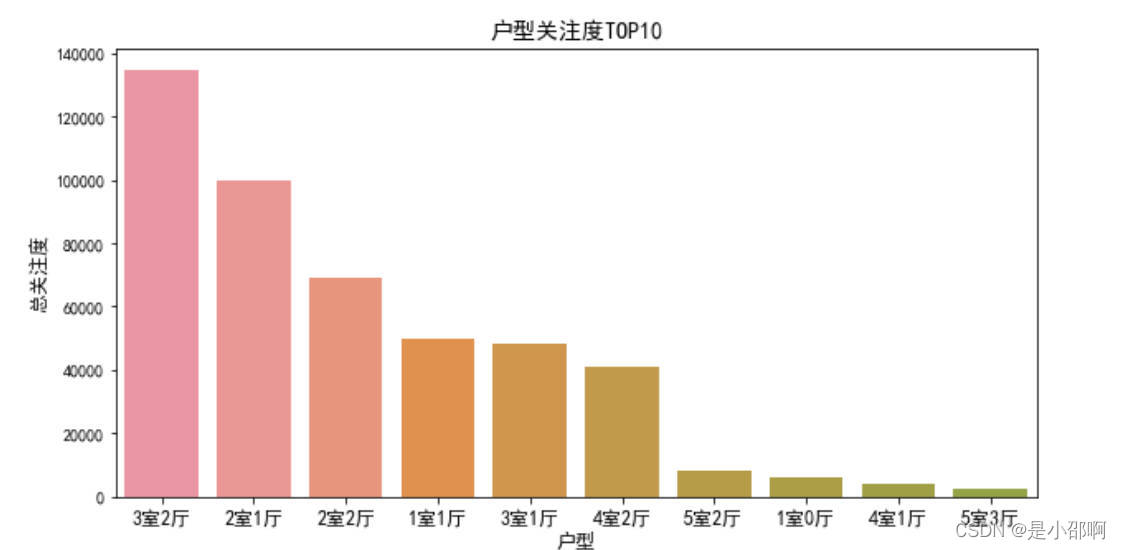
# 6不同户型关注热度对比
shape_att = data.groupby("户型")["关注"].sum().sort_values(ascending=False)
plt.figure(figsize=(10,5))
sns.barplot(shape_att.index,shape_att)
plt.title("户型关注度TOP10",fOntsize=14)
plt.ylabel("总关注度",fOntsize=12)
plt.xlabel("户型",fOntsize=12)
plt.xlim(-0.5,9.5)
plt.xticks(fOntsize=12)
plt.show()
# 7不同朝向关注热度对比
direction_att = data.groupby("窗户朝向")["关注"].sum().sort_values(ascending=False)
explode01 = np.array([0.1]*6)
colors01 = brewer2mpl.get_map(&#39;Set3&#39;, &#39;qualitative&#39;, 6).mpl_colors # 解决配色问题关键
# 忍不住吐槽,pyplot默认的配色真丑。。。
plt.figure(figsize=(8,8))
plt.pie(direction_att,explode=explode01,labels=direction_att.index,autopct="%.2f%%",textprops={&#39;fontsize&#39;:14,&#39;color&#39;:&#39;k&#39;},colors=colors01)
plt.title("不同朝向关注度占比",fOntsize=14)
plt.show()

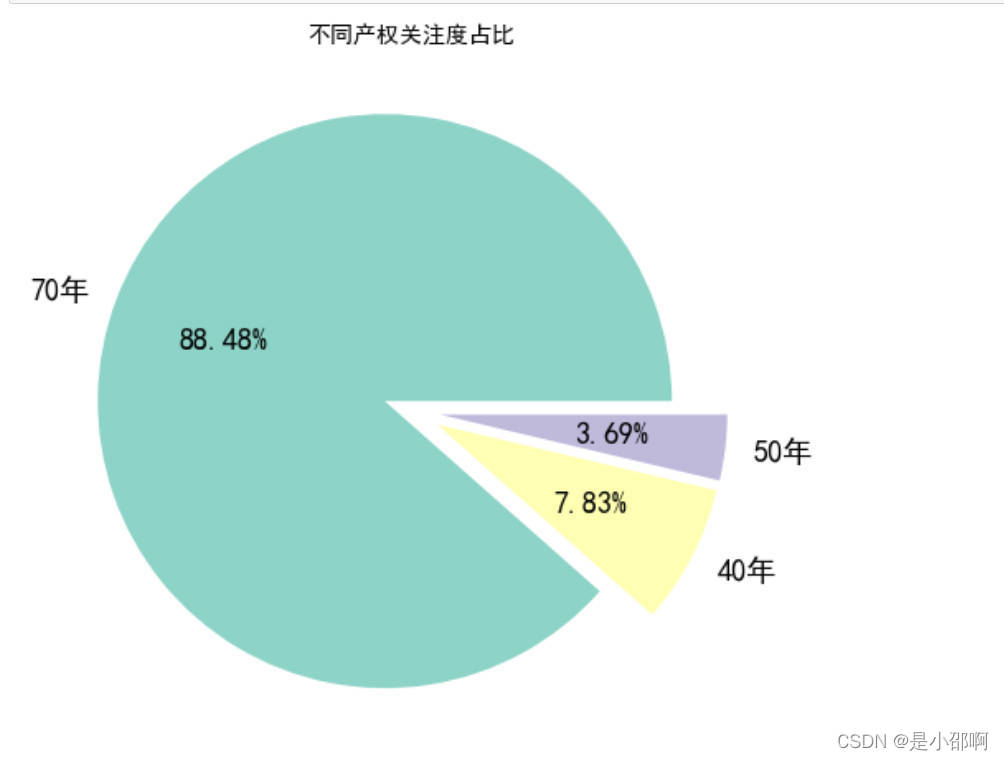
# 8不同产权关注热度对比
property_att = data.groupby("产权")["关注"].sum().sort_values(ascending=False)
explode02 = np.array([0.1]*3)
colors02 = brewer2mpl.get_map("Set3","qualitative",3).mpl_colors
plt.figure(figsize=(8,8))
plt.pie(property_att,explode=explode02,labels=property_att.index,autopct="%.2f%%",textprops={&#39;fontsize&#39;:18,&#39;color&#39;:&#39;k&#39;},colors=colors02)
plt.title("不同产权关注度占比",fOntsize=14)
plt.show()
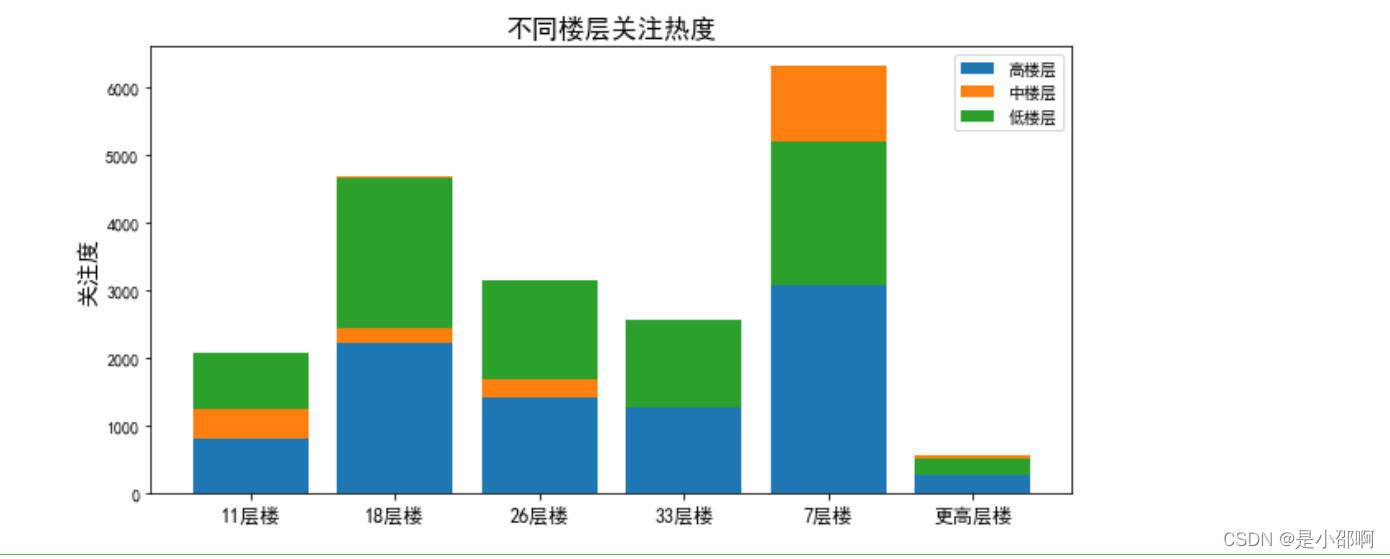
# 9不同楼层关注热度热度对比
# 根据一般常见楼层层数,划分为1-7,7-11,11-18,18-26,26-33,33以上六个阶段,查看每一阶段那个层高受欢迎
def height_range(x):if x in range(0,8):return "7层楼"elif x in range(8,12):return "11层楼"elif x in range(12,19):return "18层楼"elif x in range(19,27):return "26层楼"elif x in range(27,34):return "33层楼"elif x in range(34,100):return "更高层楼"data["层高类型"] = data["层数"].apply(height_range)
pice_data = data.groupby("层高类型")["楼层位置"].value_counts()
pd1 = pice_data.loc[:,"高楼层"]
pd2 = pice_data.loc[:,"中楼层"]
pd3 = pice_data.loc[:,"低楼层"]
plt.figure(figsize=(10,5))
plt.bar(pd1.index,pd1,label="高楼层")
plt.bar(pd2.index,pd2,bottom=pd1,label="中楼层")
plt.bar(pd3.index,pd3,bottom=pd2,label="低楼层")
plt.ylabel("关注度",fOntsize=14)
plt.title("不同楼层关注热度",fOntsize=16)
plt.xticks(fOntsize=12)
plt.legend()
plt.show()
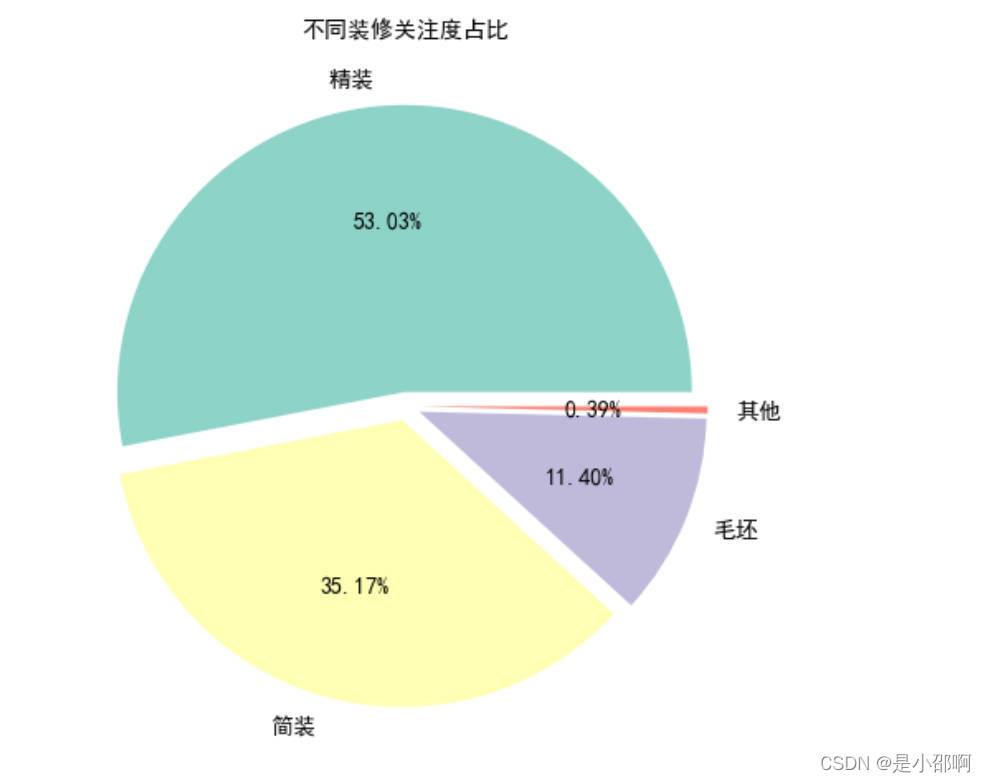
# 10装修程度对关注度的影响
fix_att = data.groupby("装修情况")["关注"].sum().sort_values(ascending=False)
explode03 = np.array([0.05]*4)
colors03 = brewer2mpl.get_map("Set3","qualitative",4).mpl_colors
plt.figure(figsize=(8,8))
plt.pie(fix_att,explode=explode03,labels=fix_att.index,autopct="%.2f%%",textprops={&#39;fontsize&#39;:14,&#39;color&#39;:&#39;k&#39;},colors=colors03)
plt.title("不同装修关注度占比",fOntsize=14)
plt.show()






 京公网安备 11010802041100号
京公网安备 11010802041100号