作者:ngdongran_638070 | 来源:互联网 | 2023-09-24 08:26
1、数据仓库逻辑分层架构
先来看数据仓库的逻辑分层架构: 分层名称可能不一样,但基本是都是这样
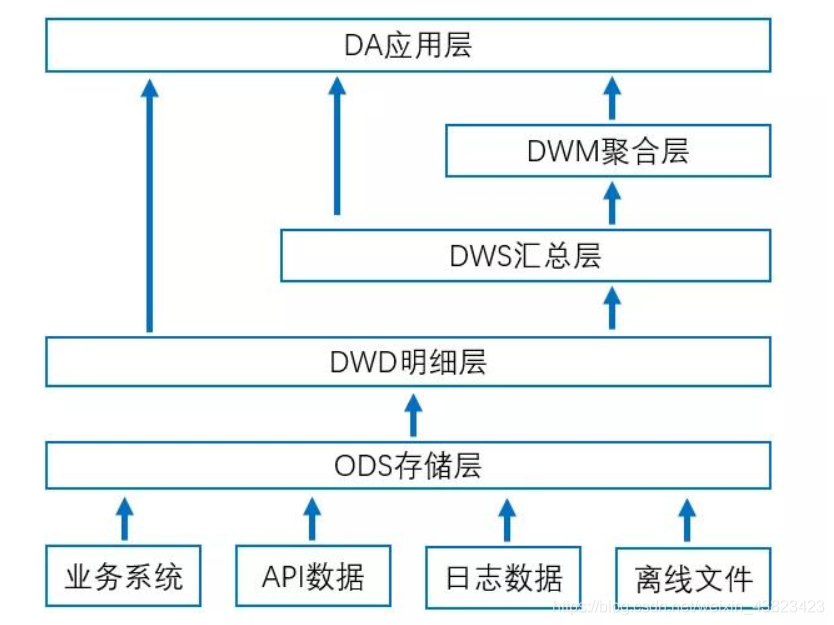
想要看懂数据仓库的逻辑分层架构,先要弄懂以下概念
- 数据源 : 数据来源,互联网公司的数据来源随着公司的规模扩张而呈递增趋势,同时自不同的业务员,比如埋点采集,客户上报,API等。
- ODS层 : 数据仓库源头系统的数据表通常会原封不动地存储一份,这称为ODS层,ODS层也经常会被称为准备层。这一层做的工作是贴源,而这些数据和源系统的数据是同构,一般对这些数据分为全量更新和增量更新,通常在贴源的过程中会做一些简单的清洗。
- DW层 : 数据仓库明细层和数据仓库汇总层是数据仓库的主题内容。将一些数据关联的日期进行拆分,使的其更具体的分类,一般拆分年,月,日,而ODS层到DW层的ETL脚本根据业务需求对数据进行清洗、设计,如果没有业务需求,则根据源系统的数据结构和未来规划去做处理,对这层的数据要求是一致,准确,尽量建立数据的完整性
- DWD层:是数据明细层,是基于业务上的数据明细,在这一步做了汇聚,去重,清洗,标准化处理
- DWS层:是汇总数据层,基于idm层的数据进行一些计算,生成一些指标报表类的数据
- DA应用层:基于 DWD/DWS 的数据做一些数据计算生成应用所需的数
- 业务产品CRM、ERP等,业务产品所使用的数据,已经存在于数据共享层,直接从数据共享层访问即可;
- 报表FineReport、业务报表,同业务产品,报表所使用的数据,一般也是已经统计汇总好的,存放于数据共享层
- 即席查询即席查询的用户有很多,有可能是数据开发人员,网站和产品运营人员,数据分析人员,甚至是部门老大,他们都有即席查询数据的需求
- OLAP:目前,很多OLAP工具不能很好的支持HDFS上直接获取数据,都是通过将需要的数据同步到关系型数据库中做OLAP,但如果数据量巨大的话,关系型数据库显然不行
- 其他数据接口:这种接口有通用的,有定制的。比如一个从Redis中获取用户属性的接口视通用的,所有的业务都可以调用这个接口来获取用户属性
2、为什么数据仓库要分层?
我们对数据进行分层的一个主要原因就是希望在管理数据的时候,能对数据有一个更加清晰的掌控,详细来讲,主要有下面几个原因:
- 清晰的数据结构:每一个数据分层都有它的作用域,这样我们在使用表的时候能更方便地定位和理解(像电信业务中的流量域,公安业务中的户籍域等,都是为了我们更快的理解和使用数据)
- 清晰的数据结构:每一个数据分层都有它的作用域,这样我们在使用表的时候能更方便地定位和理解(就是在每张加工dws/dwd的表的时候都加上 ‘来源表’这个字段,方便出现数据问题查找源头)
- 减少重复开发:规范数据分层,开发一些通用的中间层数据,能够减少极大的重复计算。比如在电信业务中流量域中,我们加工一张用户每天使用流量信息表,这样我们加工每月,近三月流量使用更加方便
- 把复杂问题简单话。讲一个复杂的任务分解成多个步骤来完成,每一层只处理单一步骤,比较简单和容易理解。
- 屏蔽原始数据的异常。就是把ods的脏数据清洗成我们需要的数据
- 屏蔽业务的影响,不必改一次业务就需要重新接入数据。
数据体系中的各个表的依赖就像是电线的流向一样,我们都希望它是很规整,便于管理的。
3、怎么进行分层
3.1 理论
我们已经知道数据仓库一般分为3个层,即:数据运营层,数据仓库层和数据产品层。
ODS层 数据运营层
‘面向主题的’,数据运营层,也叫ODS层,是最接近数据源中数据的一层,是数据源中的数据,经过抽取、洗净、传输,也就说传说中的ETL之后,装入本层。本层的数据,总体上大多是按照源头业务系统的分类系统的分类方式而分类的。
例如这一层可能包含的数据表为:人口表(包含每个人的身份证号、姓名、住址等)、机场登机记录(包含乘机人身份证号、航班号、乘机日期、起飞城市等)、银联的刷卡信息表(包含银行卡号、刷卡地点、刷卡时间、刷卡金额等)、银行账户表(包含银行卡号、持卡人身份证号等)等等一系列原始的业务数据。这里我们可以看到,这一层面的数据还具有鲜明的业务数据库的特征,甚至还具有一定的关系数据库中的数据范式的组织形式。
但是,这一层面的数据却不同于原始数据。在源数据装入这一层时,要进行诸如去噪(列如去掉明显偏离正常水平的银行刷卡信息)、去重(列如银行账户信息、公安人口信息中均含有人的姓名,但是只保留一份即可)、提脏(列如有的人的银行卡被盗取,在十分钟内同时有两笔分别再中国和日本的刷卡信息,这便是脏数据)、业务提取、单位统一、砍字段(列如用于支撑前端系统工作,但是在数据挖掘中不需要的字段)、业务判别等多项工作。
DW 数据仓库层
在这里,从ODS层中获得的数据按照主题建立各种数据模型。列如以研究人的旅游消费为主题的数据集中便可以结合航空公司的等级出现信息,以及银联系统的刷卡记录,进行结合分析,产生数据集。分为业务域和业务中心
数据产品层(APP),这一层是提供为数据产品使用能够的结果数据
在这里,主要是提供给数据产品和数据分析使用的数据,一般会存放在es,mysql等系统中供线上系统使用,也可能会存在Hive或者Druid中供数据分析和数据挖掘使用 比如我们经常说的报表数据,或者说那种打宽表,一般都放在这里 。
3.2 技术路线
这三层技术划分,相对来说比较粗粒度。这里仅仅简单介绍几个常用工具,侧重中开源界主流。
1、数据来源层 ---> ODS层
- 业务库,这里经常会使用sqoop来抽取,比如我们每天定时抽取一次,在实时方面,可以考虑用cannal监听msql的binlog,实时接入即可。
- 埋点日志,线上系统会打入各种日志,这些日志一般以文件的形式保存,我们可以选择用flume定时抽取,也可以用用spark streaming或者storm来实时接入,当然,kafka也会是一个关键角色
2.ODS、DW --> APP层
- 每天定时任务型:比如我们典型的日计算任务,每天凌晨算前一天的数据,早上起来看报表。这种任务进程使用Hive、Spark或者生撸MR程序来计算,最终结果写入Hive、Hbase、Mysql、ES或者Redis中。
- 实时数据:这部分主要是各种实时的系统使用,比如我们的实时推荐、实时用户画像、一般我们会用Spark Streaming、Storm或者Flink来计算,最后会落入Es、Hbase或者Redis中。









 京公网安备 11010802041100号
京公网安备 11010802041100号