在第二篇文章中,我们将在前一篇的基础上,加入落盘机制。
一台机器内存总是有限的,为了提高 mini-nsq 的服务能力,当内存使用量达到设定的上限时,我们就需要将接下来收到的 message 存到文件中。
在 nsq 的设计中,每个 topic,每个 channel 都会新起一个协程负责读写文件,并且他们都会分别存放在各自的文件中。同时,为了防止文件过大,当文件大小达到设定容量时,就会新建一个文件进行存放,当一个文件的内容都被读取之后,就会删除这个文件。
所有对于文件的操作都是借助于 diskQueue 这个结构体
type diskQueue struct {
name string
dataPath string
maxBytesPerFile int64 //一个文件能存放的最大容量,如果超过了就要再新建一个文件去存
readChan chan []byte // exposed via ReadChan()
writeChan chan []byte
writeResponseChan chan error
readPos int64
writePos int64
readFileNum int64
writeFileNum int64
// 读取文件和把读取到的内容实际发送给接收方是两个步骤,
// 下面两个变量用来记录这两个步骤的中间状态
nextReadPos int64
nextReadFileNum int64
readFile *os.File
writeFile *os.File
reader *bufio.Reader
writeBuf bytes.Buffer
}
func NewDiskQueue(name string) *diskQueue {
d := diskQueue{
name: name,
maxBytesPerFile: 24,
readChan: make(chan []byte),
writeChan: make(chan []byte),
writeResponseChan: make(chan error),
}
d.dataPath, _ = os.Getwd()
go d.ioLoop()
return &d
}
// ReadChan returns the receive-only []byte channel for reading data
func (d *diskQueue) ReadChan() <-chan []byte {
return d.readChan
}
// Put writes a []byte to the queue
func (d *diskQueue) Put(data []byte) error {
d.writeChan <- data
return <-d.writeResponseChan
}
diskQueue 的 readFileNum 和 readPos 用来标识我们读到哪个文件的哪个位置了,writeFileNum 和 writePos 用来标识我们写到哪个文件的哪个位置了。
在 NewDiskQueue 时,我们会传递一个 name ,这个 name 会作为文件名的一部分来唯一的标识文件。此处我们设置最大容量 maxBytesPerFile 为 24 字节是为了方便后面的测试,在实际的 nsq 中,这个值默认为 100M 并且支持自定义配置。
我们提供了 Put 和 ReadChan 两个 API 供外界调用。
Put 方法负责将消息存入文件,可以看到它是把 data 丢给了 writeChan 这个通道,这里使用通道是为了方便并发操作,比如对于同一个topic,可能同时有多个客户端都在发布消息,使用了通道我们就不需要考虑并发写可能产生的各种问题了,只要再起一个工作协程不停的从通道中接收消息,并且往文件里写就行了。注意在 NewDiskQueue 我们把 writeChan 的容量设置为 0,这样它默认就是阻塞的了,往上回朔调用链会发现他最终会阻塞住 protocal 的 IOLoop 方法,也就是阻塞住了从客户端接收网络消息,参考 tcp 滑动窗口协议,这样就能减轻服务端的压力了。
ReadChan 方法则是将 readChan 暴露给调用方,从文件中读取的数据都会发给 readChan,这样调用方只需要监听 readChan 就可以拿到文件中的数据了。
注意到,在 NewDiskQueue 中我们会新启一个协程调用 ioLoop 方法负责文件的实际读写,接下来我们来分析下这个方法。
func (d *diskQueue) ioLoop() {
var dataRead []byte
var err error
var r chan []byte
for {
if (d.readFileNum //这里就显示出了nextReadPos的作用了,当比较结果不一致的话,说明上一轮循环已经读取过一次文件了,
//但是下面的select分支并没有选择 r <- dataRead,所以这一轮我们就不需要再次读取了
if d.nextReadPos == d.readPos && d.nextReadFileNum==d.readFileNum {
dataRead, err = d.readOne()
if err != nil {
log.Printf("DISKQUEUE(%s) reading at %d of %s - %s",
d.name, d.readPos, d.fileName(d.readFileNum), err)
d.handleReadError()
continue
}
}
r = d.readChan
} else {
r = nil
}
select {
case r <- dataRead:
d.moveForward()
case dataWrite := <-d.writeChan:
d.writeResponseChan <- d.writeOne(dataWrite) //把错误直接抛给上层
}
}
}
在无限 for 循环中,首先如果还有消息可以读取的话,我们就会读取一条出来,然后在下面的 select 中,如果进入了 r <- dataRead 分支,表示这条读取的消息已经在某个地方被接收了,接下来就会执行 moveForward 方法更新读取的位置以及删除旧文件。如果进入了 dataWrite := <-d.writeChan 分支表示成功接收到了 Put 方法的调用方想要存入的消息,接下来就会执行 writeOne 将消息写入到文件中,并把结果发送给 writeResponseChan ,最终会返回给调用方。
这里可以发现,对于同一个文件,读操作和写操作不会同时发生。在后面的分析中,我们会发现,在读取操作中,当读取错误后,可能会修改下一次要写入的位置以及删除文件(实际是把文件重命名了)。这样一来,如果不会发生并发操作,就不需要考虑各种各样的并发问题了。
接下来我们看看实际的写入方法
func (d *diskQueue) writeOne(data []byte) error {
var err error
if d.writeFile == nil {
curFileName := d.fileName(d.writeFileNum)
d.writeFile, err = os.OpenFile(curFileName, os.O_RDWR|os.O_CREATE, 0600)
if err != nil {
return err
}
log.Printf("DISKQUEUE(%s): writeOne() opened %s", d.name, curFileName)
if d.writePos > 0 {
_, err = d.writeFile.Seek(d.writePos, 0)
if err != nil {
d.writeFile.Close()
d.writeFile = nil
return err
}
}
}
dataLen := int32(len(data))
d.writeBuf.Reset()
err = binary.Write(&d.writeBuf, binary.BigEndian, dataLen) //先把消息长度写进去
if err != nil {
return err
}
_, err = d.writeBuf.Write(data) //再把data写进去
if err != nil {
return err
}
// only write to the file once
_, err = d.writeFile.Write(d.writeBuf.Bytes())
if err != nil {
d.writeFile.Close()
d.writeFile = nil
return err
}
totalBytes := int64(4 + dataLen)
d.writePos += totalBytes
//如果该文件写满了,就换下一个文件写
if d.writePos >= d.maxBytesPerFile {
d.writeFileNum++
d.writePos = 0
if d.writeFile != nil {
d.writeFile.Close()
d.writeFile = nil
}
}
return nil
}
首先判断待写入的文件是否已经打开,如果没有的话就打开并跳转到待写入的位置。实际写入消息的过程分为两步,首先写入4个字节的消息长度,再完整写入消息。最后更新写入文件的位置。
我们再来看一下实际的读取方法
func (d *diskQueue) readOne() ([]byte, error) {
var err error
var msgSize int32
if d.readFile == nil {
curFileName := d.fileName(d.readFileNum)
d.readFile, err = os.OpenFile(curFileName, os.O_RDONLY, 0600)
if err != nil {
return nil, err
}
log.Printf("DISKQUEUE(%s): readOne() opened %s", d.name, curFileName)
if d.readPos > 0 {
_, err = d.readFile.Seek(d.readPos, 0)
if err != nil {
d.readFile.Close()
d.readFile = nil
return nil, err
}
}
d.reader = bufio.NewReader(d.readFile)
}
err = binary.Read(d.reader, binary.BigEndian, &msgSize)
if err != nil {
d.readFile.Close()
d.readFile = nil
return nil, err
}
readBuf := make([]byte, msgSize)
_, err = io.ReadFull(d.reader, readBuf)
if err != nil {
d.readFile.Close()
d.readFile = nil
return nil, err
}
totalBytes := int64(4 + msgSize)
// we only advance next* because we have not yet sent this to consumers
d.nextReadPos = d.readPos + totalBytes
d.nextReadFileNum = d.readFileNum
if d.nextReadPos >= d.maxBytesPerFile {
if d.readFile != nil {
d.readFile.Close()
d.readFile = nil
}
d.nextReadFileNum++
d.nextReadPos = 0
}
return readBuf, nil
}
read 方法和 write 方法很相似,只不过在最后并没有直接更新读取的位置,而是把下一次要读取的位置存入到 nextReadFileNum ,nextReadPos 两个变量中了,这是因为读取一条消息实际是由两个步骤组成的:1.从文件中读取 2.将读取到的消息发送给接收者。具体的更新操作是在发送给接收者之后调用的 moveForward 方法,接下来我们具体看看这个方法。
func (d *diskQueue) moveForward() {
oldReadFileNum := d.readFileNum
d.readFileNum = d.nextReadFileNum
d.readPos = d.nextReadPos
// see if we need to clean up the old file
if oldReadFileNum != d.nextReadFileNum {
fn := d.fileName(oldReadFileNum)
err := os.Remove(fn)
if err != nil {
log.Printf("DISKQUEUE(%s) failed to Remove(%s) - %s", d.name, fn, err)
}
}
}
方法很简单,在最后为了避免文件无限的增长,我们会删除已经读完的文件。
其他的一些方法
func (d *diskQueue) handleReadError() {
if d.readFileNum == d.writeFileNum {
// if you can't properly read from the current write file it's safe to
// assume that something is fucked and we should skip the current file too
if d.writeFile != nil {
d.writeFile.Close()
d.writeFile = nil
}
d.writeFileNum++
d.writePos = 0
}
badFn := d.fileName(d.readFileNum)
badRenameFn := badFn + ".bad"
log.Printf("DISKQUEUE(%s) jump to next file and saving bad file as %s",
d.name, badRenameFn)
err := os.Rename(badFn, badRenameFn)
if err != nil {
log.Printf(
"DISKQUEUE(%s) failed to rename bad diskqueue file %s to %s",
d.name, badFn, badRenameFn)
}
d.readFileNum++
d.readPos = 0
d.nextReadFileNum = d.readFileNum
d.nextReadPos = 0
}
func (d *diskQueue) fileName(fileNum int64) string {
return fmt.Sprintf(path.Join(d.dataPath, "%s.diskqueue.%06d.dat"), d.name, fileNum)
}
当读取文件发生错误后,就会调用handleReadError方法,具体做法就是放弃这个文件,直接把下一次读取位置更新为下一个文件,另外我们会将这个错误的文件重名为 "*.bad" 方便后面人工排查问题。
接下来我们看看 Topic 中是如何使用 diskQueue 的。注意以下代码并非完整代码,与上一节相同的部分可能会被省略。
type Topic struct {
memoryMsgChan: make(chan *Message, 1),
backend *diskQueue
}
func NewTopic(topicName string) *Topic {
t.backend = NewDiskQueue(topicName)
}
首先 Topic 新增了一个 diskQueue 类型的成员变量 backend 执行和文件相关的操作,这里传入的 name 就是 topic 本身的 name。此外我们此处将 memoryMsgChan 容量设为1条 message,是为了后面测试的方便。
func (t *Topic) PutMessage(m *Message) error {
log.Printf("message 进入 topic")
select {
case t.memoryMsgChan <- m: //如果内存放得下,就先放到内存中
default:
err := writeMessageToBackend(m, t.backend) //如果内存放不下,就记录到磁盘里
if err != nil {
log.Printf(
"TOPIC(%s) ERROR: failed to write message to backend - %s",
t.name, err)
return err
}
}
return nil
}
PutMessage 方法首先会尝试往内存中放,如果失败的话就会往文件中写入。
func (t *Topic) messagePump() {
var err error
var msg *Message
var buf []byte
var chans []*Channel
var memoryMsgChan chan *Message
var backendChan <-chan []byte
t.Lock()
for _, c := range t.channelMap {
chans = append(chans, c)
}
t.Unlock()
if len(chans) > 0 {
memoryMsgChan = t.memoryMsgChan
backendChan = t.backend.ReadChan()
}
// main message loop
for {
select {
case msg = <-memoryMsgChan:
case buf = <-backendChan:
msg, err = decodeMessage(buf)
if err != nil {
log.Printf("failed to decode message - %s", err)
continue
}
case <-t.channelUpdateChan:
log.Println("topic 更新 channel")
chans = chans[:0]
t.Lock()
for _, c := range t.channelMap {
chans = append(chans, c)
}
t.Unlock()
if len(chans) == 0 {
memoryMsgChan = nil
backendChan = nil
} else {
memoryMsgChan = t.memoryMsgChan
backendChan = t.backend.ReadChan()
}
continue
}
//到这里的时候chans的数量必须 >0,否则消息就丢失了,
//所以我们处理时会在chans为 0的时候将memoryMsgChan置为nil
for _, channel := range chans {
err := channel.PutMessage(msg)
if err != nil {
log.Printf(
"TOPIC(%s) ERROR: failed to put msg(%s) to channel(%s) - %s",
t.name, msg.ID, channel.name, err)
}
}
}
}
在 select 中不管 message 是从内存中读到的还是文件中读到的,接下来的处理方式都是一致的,所以我们把后续的处理放在了select 外面,这样就避免了重复代码。同时,因为我们存在文件里的是二进制数据,所以在读取之后要再解码成 Message
type Channel struct {
backend *diskQueue
}
func NewChannel(topicName string, channelName string) *Channel {
return &Channel{
memoryMsgChan: make(chan *Message, 1),
backend: NewDiskQueue(getBackendName(topicName,channelName)),
}
}
func getBackendName(topicName, channelName string) string {
// backend names, for uniqueness, automatically include the topic... :
backendName := topicName + "___" + channelName
return backendName
}
func (c *Channel) PutMessage(m *Message) error {
log.Printf("message 进入 channel,body:%s", m.Body)
select {
case c.memoryMsgChan <- m: //如果内存放得下,就先放到内存中
default:
err := writeMessageToBackend(m, c.backend) //如果内存放不下,就记录到磁盘里
if err != nil {
log.Printf(
"TOPIC(%s) ERROR: failed to write message to backend - %s",
c.name, err)
return err
}
}
return nil
}
channel 和 topic 变化基本是一致的,注意这里传入的 name 是在 channel 的 name 前拼上 topic name ,以防止同样的命名造成混乱。另外,我们在中间拼入了 "___" ,nsq 原本是拼入 ":" ,并且在一开始就限制 topic name 和 channel name 中不能有 ":",这样就杜绝了重复的可能性,但是因为 Windows 规定文件中不能存在 ":",这里为了测试时候更直观的看到数据文件,我们这里就没有使用 ":"
因为 channel 中存入的 message 最终是在 protocol.go 中取出使用的,所以我们还需要看一下protocol 文件
func (p *protocol) messagePump(client *client) {
var err error
var msg *Message
var memoryMsgChan chan *Message
var backendMsgChan <-chan []byte
var subChannel *Channel
//这里新创建subEventChan是为了在下面可以把它置为nil以实现“一个客户端只能订阅一次”的目的
subEventChan := client.SubEventChan
for {
select {
case subChannel = <-subEventChan: //表示有订阅事件发生,这里的subChannel就是消费者实际绑定的channel
log.Printf("topic:%s channel:%s 发生订阅事件",subChannel.topicName,subChannel.name)
memoryMsgChan = subChannel.memoryMsgChan
backendMsgChan = subChannel.backend.ReadChan()
// you can't SUB anymore
subEventChan = nil
continue
case msg = <-memoryMsgChan: //如果channel对应的内存通道有消息的话
case buf := <-backendMsgChan:
msg, err = decodeMessage(buf)
if err != nil {
log.Printf("failed to decode message - %s", err)
continue
}
}
time.Sleep(time.Second*3)
err = p.SendMessage(client, msg)
if err != nil {
go func() {
_=subChannel.PutMessage(msg)
}()
log.Printf("PROTOCOL(V2): [%s] messagePump error - %s", client.RemoteAddr(), err)
goto exit
}
}
exit:
log.Printf("PROTOCOL(V2): [%s] exiting messagePump", client.RemoteAddr())
}
和 topic 很类似,我们就不再具体分析了。只是注意一下在每一次for循环中,我们都强制睡眠是3s,这是为了放慢向消费者发送 message 的速度,目的是更直观的看到数据文件的变化,仅仅是为了测试。
另外 Message 中还有两个辅助方法,都不复杂
func decodeMessage(b []byte) (*Message, error) {
var msg Message
copy(msg.ID[:], b[:MsgIDLength])
msg.Body = b[MsgIDLength:]
return &msg, nil
}
func writeMessageToBackend(msg *Message, bq *diskQueue) error {
msgByte, err := msg.Bytes()
if err != nil {
return err
}
return bq.Put(msgByte)
}
client.go
func main() {
log.SetFlags(log.Lshortfile | log.Ltime)
nsqdAddr := "127.0.0.1:4150"
conn, err := net.Dial("tcp", nsqdAddr)
go readFully(conn)
if err != nil {
log.Fatal(err)
}
var cmd *Command
pubOnce(conn)
time.Sleep(time.Second*3)
cmd = Subscribe("mytopic", "mychannel")
cmd.WriteTo(conn)
select {
}
}
func pubOnce(conn net.Conn){
var cmd *Command
cmd = Publish("mytopic", []byte("one one "))
cmd.WriteTo(conn)
cmd = Publish("mytopic", []byte("two two"))
cmd.WriteTo(conn)
cmd = Publish("mytopic", []byte("three three"))
cmd.WriteTo(conn)
cmd = Publish("mytopic", []byte("four four"))
cmd.WriteTo(conn)
}
客户端先发送4条 message,然后睡眠3s,此时 mini-nsq 中因为没有消费者接收这些 message,并且我们已经将 topic 的内存存储容量设置为1条 message,这样的话有三条 message 就会存入到文件中,如下所示。
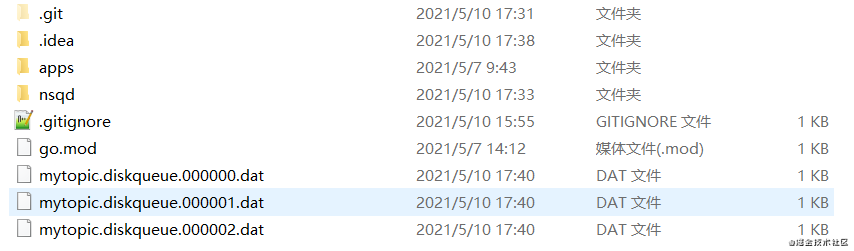
3s后,客户端订阅该 topic,mini-nsq就会从topic的数据文件中读取出数据并且传递给指定的 channel ,因为 channel 的内存容量也只有1条 message 的大小,并且我们在前面也故意放慢了向消费者发送 message 的速度,所以这时候也能短暂看到该 channel 生成的数据文件,如下
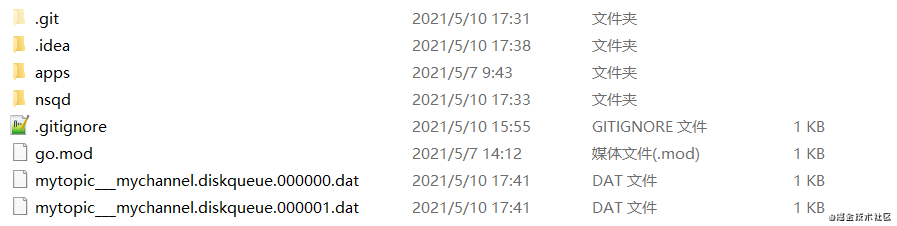
再过几s 之后,当所有 message 都已经发送给消费者,我们再查看,就会发现已经没有任何数据文件存在了。
至于具体的落盘和读盘操作读者可自行从控制台的输出中查看。
git clone https://github.com/xianxueniao150/mini-nsq.git
git checkout day02






 京公网安备 11010802041100号 | 京ICP备19059560号-4 | PHP1.CN 第一PHP社区 版权所有
京公网安备 11010802041100号 | 京ICP备19059560号-4 | PHP1.CN 第一PHP社区 版权所有 
