作者:gengjiang3_946 | 来源:互联网 | 2023-07-05 15:15
前言 使用百度开源的paddleX工具,我们可以很容易快速训练出使用我们自己标注的数据的目标检测,图像分类,实例分割,语义分割的深度网络模型,本文,主要记录如何全流程使用pddleX来训练一个简单用于检测猫狗ppyolo_tiny模型。
(一)数据准备 这里的图片,我们直接在百度图片上搜索“猫狗”,随机下载10张图片,存到“JPEGImages文件夹 ”里。
(二)使用labelme标注工具进行标注 (1)labelme安装&启动 #前提时安装了anaconda
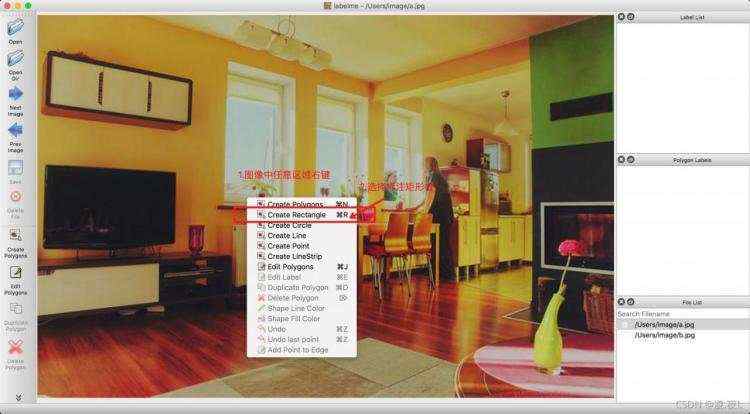
(2)目标框标注 打开矩形框标注工具(右键菜单->Create Rectangle),具体如下图所示
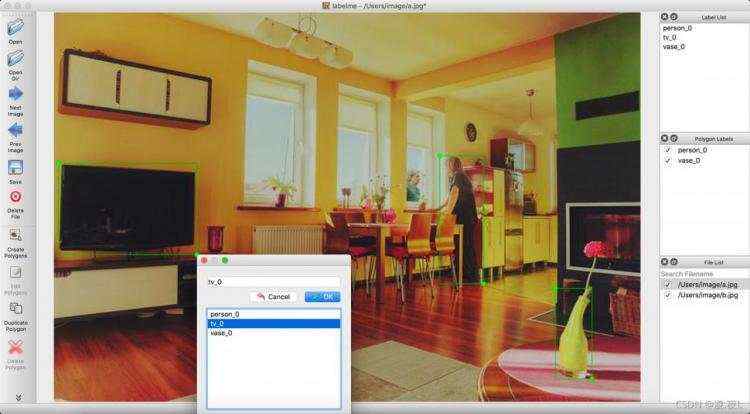
使用拖拉的方式对目标物体进行标识,并在弹出的对话框中写明对应label(当label已存在时点击即可, 此处请注意label勿使用中文),具体如下图所示,当框标注错误时,可点击左侧的“Edit Polygons”再点击标注框,通过拖拉进行修改,也可再点击“Delete Polygon”进行删除。
点击右侧”Save“,将标注结果保存到中创建的文件夹Annotations目录中
(3)更多类型的标注 这部分直接复制了paddleX里的文档 数据标注。
详见文档图像分类数据标注
详见文档目标检测数据标注
详见文档实例分割数据标注
详见文档语义分割数据标注
(三)使用paddlex提供的工具将labelme标注的数据转转换成VOC格式的数据 LabelMe标注后的数据还需要进行转换为PascalVOC或MSCOCO格式,才可以用于目标检测任务的训练,创建D:\dataset_voc目录,在python环境中安装paddlex后,使用如下命令即可
paddlex --data_conversion --source labelme --to PascalVOC \
详细用法,参考官方文档
(四)数据切分 目标检测
paddlex --split_dataset --format VOC --dataset_dir D:\MyDataset --val_value 0.2 --test_value 0.1
执行上面命令行,会在D:\MyDataset下生成labels.txt, train_list.txt, val_list.txt和test_list.txt,分别存储类别信息,训练样本列表,验证样本列表,测试样本列表
(五)数据加载 这里介绍的是PascalVOC格式的检测数据集的读取,参考代码在后面的完整代码中,MSCOCO格式的检测数据集与语义分割任务数据集的读取,参考官方文档
(六)数据增强 参考官方文档
(七)模型导入 paddlex.det中的模型 = cv. models. YOLOv3= cv. models. FasterRCNN= cv. models. PPYOLO= cv. models. PPYOLOTiny= cv. models. PPYOLOv2= cv. models. MaskRCNN
paddlex.det中的模型 UNet = cv. models. UNet= cv. models. DeepLabV3P= cv. models. FastSCNN= cv. models. HRNet= cv. models. BiSeNetV2
paddlex.cls中的模型 ResNet18 = cv. models. ResNet18= cv. models. ResNet34= cv. models. ResNet50= cv. models. ResNet101= cv. models. ResNet152= cv. models. ResNet18_vd= cv. models. ResNet34_vd= cv. models. ResNet50_vd= cv. models. ResNet50_vd_ssld= cv. models. ResNet101_vd= cv. models. ResNet101_vd_ssld= cv. models. ResNet152_vd= cv. models. ResNet200_vd= cv. models. MobileNetV1= cv. models. MobileNetV2= cv. models. MobileNetV3_small= cv. models. MobileNetV3_small_ssld= cv. models. MobileNetV3_large= cv. models. MobileNetV3_large_ssld= cv. models. AlexNet= cv. models. DarkNet53= cv. models. DenseNet121= cv. models. DenseNet161= cv. models. DenseNet169= cv. models. DenseNet201= cv. models. DenseNet264= cv. models. HRNet_W18_C= cv. models. HRNet_W30_C= cv. models. HRNet_W32_C= cv. models. HRNet_W40_C= cv. models. HRNet_W44_C= cv. models. HRNet_W48_C= cv. models. HRNet_W64_C= cv. models. Xception41= cv. models. Xception65= cv. models. Xception71= cv. models. ShuffleNetV2= cv. models. ShuffleNetV2_swish
下面是各类模型的官方文档,后面完整代码中,实例代码
(八)模型训练与参数调整 模型训练
(九)完整代码 import paddlex as pdxfrom paddlex import transforms as T= T. Compose( [ . MixupImage( mixup_epoch= - 1 ) , T. RandomDistort( ) , . RandomExpand( im_padding_value= [ 123.675 , 116.28 , 103.53 ] ) , T. RandomCrop( ) , . RandomHorizontalFlip( ) , T. BatchRandomResize( = [ 192 , 224 , 256 , 288 , 320 , 352 , 384 , 416 , 448 , 480 , 512 ] , = 'RANDOM' ) , T. Normalize( = [ 0.485 , 0.456 , 0.406 ] , std= [ 0.229 , 0.224 , 0.225 ] ) ] ) = T. Compose( [ . Resize( = 320 , interp= 'CUBIC' ) , T. Normalize( = [ 0.485 , 0.456 , 0.406 ] , std= [ 0.229 , 0.224 , 0.225 ] ) ] ) = pdx. datasets. VOCDetection( = '/home/libufan/桌面/catDog/voc' , = '/home/libufan/桌面/catDog/voc/train_list.txt' , = '/home/libufan/桌面/catDog/voc/labels.txt' , = train_transforms, = True ) = pdx. datasets. VOCDetection( = '/home/libufan/桌面/catDog/voc' , = '/home/libufan/桌面/catDog/voc/val_list.txt' , = '/home/libufan/桌面/catDog/voc/labels.txt' , = eval_transforms) = len ( train_dataset. labels) = pdx. det. PPYOLOTiny( num_classes= num_classes) . train( = 100 , = train_dataset, = 1 , = eval_dataset, = 'COCO' , = 0.005 , = 1000 , = 0.0 , = [ 130 , 540 ] , = .5 , = 20 , = 'output/ppyolotiny' , = True ) = pdx. load_model( 'output/ppyolotiny/best_model' ) = 'insect_det/JPEGImages/0217.jpg' = model. predict( image_name) . det. visualize( image_name, result, threshold= 0.5 , save_dir= './output/ppyolotiny' ) '' '








 京公网安备 11010802041100号
京公网安备 11010802041100号