前言 本文将分享从0开始编写自己的bcc程序。那么开始编写bcc之前,自己一定要明确,我们要用bcc提取什么数据。本文的实例是统计内核网络中的流量,我要提取的数据关键字段为进程的PID,进程的名字,进程的收包实时流量、发包实时流量,收包流量总和,发包流量总和,总的收发流量等。
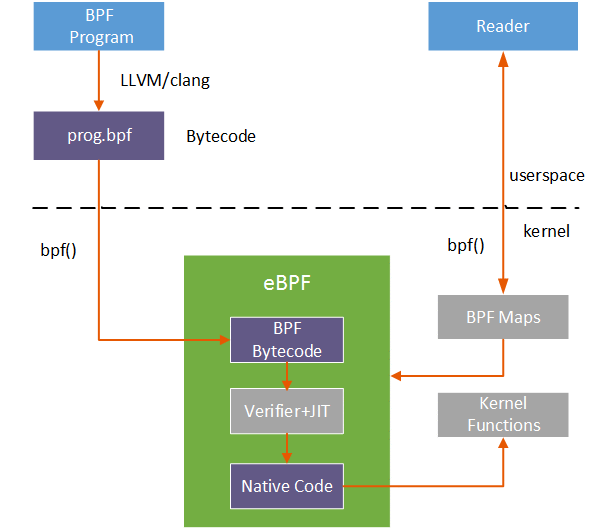
我们知道bcc是eBPF的一个工具集,是eBPF提取数据的上层封装,它的形式是python中嵌套bpf程序。python部分的作用是为用户提供友好的使用eBPF的上层接口,也用于数据处理。bpf程序会注入内核,提取数据。当bpf程序运行时,通过LLVM将bpf程序编译得到bpf指令集的elf文件,从elf文件中解析出可以注入内核的部分,用bpf_load_program方法完成注入。注入程序bpf_load_program()加入了更复杂的verifier 机制,在运行注入程序之前,先进行一系列的安全检查,最大限度的保证系统的安全。经过安全检查的bpf字节码使用内核JIT进行编译,生成本机汇编指令,附加到内核特定挂钩的程序。最终内核态与用户态通过高效的map机制进行通信,bcc在用户态是使用python进行数据处理的,一图胜千言。
开始编程 了解了bcc工具的工作方式,下面开始写代码,先写python部分,下面是python引入的模块和包,这部分可以在写程序过程中逐步引入,也就是在写python的过程中用到了某个函数就引入相应的模块和包。
from __future__ import print_functionfrom bcc import BPFfrom time import sleepimport argparsefrom collections import namedtuple, defaultdictfrom threading import Thread, currentThread, Lock
下面是程序选项,可以使用–help来查看可用的选项,效果是这样的:
def range_check ( string) : value &#61; int ( string) if value < 1 : msg &#61; "value must be stricly positive, got %d" % ( value, ) raise argparse. ArgumentTypeError( msg) return value&#61; """examples:./flow # trace send/recv flow by host ./flow -p 100 # only trace PID 100 &#61; argparse. ArgumentParser( description &#61; "Summarize send and recv flow by host" , formatter_class &#61; argparse. RawDescriptionHelpFormatter, epilog &#61; examples) . add_argument( "-p" , "--pid" , help &#61; "Trace this pid only" ) . add_argument( "interval" , nargs&#61; "?" , default&#61; 1 , type &#61; range_check, help &#61; "output interval, in second (default 1)" ) . add_argument( "count" , nargs&#61; "?" , default&#61; - 1 , type &#61; range_check, help &#61; "number of outputs" ) &#61; parser. parse_args( )
接下来是bcc程序中的bpf代码&#xff0c;在python中以这样的形式引入&#xff1a;
bpf_program &#61; """
BPF代码 本实例中用到的BPF代码如下&#xff0c;使用了kprobe来探测内核中与网络流量相关的tcp_sendmsg函数和tcp_cleanup_rbuf函数&#xff0c;代码详细作用请看注释&#xff1a;
#include #include #include struct ipv4_key_t { u32 pid; } ; BPF_HASH ( ipv4_send_bytes, struct ipv4_key_t) ; BPF_HASH ( ipv4_recv_bytes, struct ipv4_key_t) ; int kprobe__tcp_sendmsg ( struct pt_regs * ctx, struct sock * sk, struct msghdr * msg, size_t size) { u32 pid &#61; bpf_get_current_pid_tgid ( ) >> 32 ; FILTER_PIDu16 family &#61; sk-> __sk_common. skc_family; if ( family &#61;&#61; AF_INET) { struct ipv4_key_t ipv4_key &#61; { . pid &#61; pid} ; ipv4_send_bytes. increment ( ipv4_key, size) ; } return 0 ; } int kprobe__tcp_cleanup_rbuf ( struct pt_regs * ctx, struct sock * sk, int copied) { u32 pid &#61; bpf_get_current_pid_tgid ( ) >> 32 ; FILTER_PIDu16 family &#61; sk-> __sk_common. skc_family; u64 * val, zero &#61; 0 ; if ( copied <&#61; 0 ) return 0 ; if ( family &#61;&#61; AF_INET) { struct ipv4_key_t ipv4_key &#61; { . pid &#61; pid} ; ipv4_recv_bytes. increment ( ipv4_key, copied) ; } return 0 ; }
几点说明&#xff1a;
Syntax: BPF_HASH(name [, key_type [, leaf_type [, size]]]) Creates a hash map (associative array) named name, with optional parameters. Defaults: BPF_HASH(name, key_type&#61;u64, leaf_type&#61;u64, size&#61;10240) For example: BPF_HASH(start, struct request *); This creates a hash named start where the key is a struct request *, and the value defaults to u64. This hash is used by the disksnoop.py example for saving timestamps for each I/O request, where the key is the pointer to struct request, and the value is the timestamp. Methods (covered later): map.lookup(), map.lookup_or_try_init(), map.delete(), map.update(), map.insert(), map.increment(). FILTER_PIDbpf_program.replace来进行语句替换的&#xff0c;具体作用在下文中python部分会介绍到。
ipv4_send_bytes.incrementmap.increment()的方法&#xff0c;本实例中是在哈希表ipv4_send_bytes中以ipv4_key为关键字将size作为值进行累加。
Syntax: map.increment(key[, increment_amount]) Increments the key’s value by increment_amount, which defaults to 1. Used for histograms. 数据处理 刚刚提到FILTER_PID无实际意义&#xff0c;是在python中使用bpf_program.replace来进行语句替换的&#xff0c;现在看下它在python中的处理&#xff1a;
if args. pid: bpf_program &#61; bpf_program. replace( &#39;FILTER_PID&#39; , &#39;if (pid !&#61; %s) { return 0; }&#39; % args. pid) else : bpf_program &#61; bpf_program. replace( &#39;FILTER_PID&#39; , &#39;&#39; )
如果使用选项 -p 指定了pid&#xff0c;那么bpf程序中的FILTER_PID会被替换为if (pid !&#61; %s) { return 0; }&#xff0c;最终在bpf程序中起到过滤指定pid数据的作用。如果没有使用选项 -p 指定 pid&#xff0c;那么就会删除FILTER_PID。也就是说bpf程序中的FILTER_PID不会直接执行&#xff0c;直接执行了会出错&#xff0c;而是经过python处理后才执行。
自定义python函数 def pid_to_comm ( pid) : try : comm &#61; open ( "/proc/%s/comm" % pid, "r" ) . read( ) . rstrip( ) return commexcept IOError: return str ( pid) &#61; namedtuple( &#39;Session&#39; , [ &#39;pid&#39; ] ) def get_ipv4_session_key ( k) : return SessionKey( pid&#61; k. pid)
初始化bpf &#61; BPF( text&#61; bpf_program) &#61; b[ "ipv4_send_bytes" ] &#61; b[ "ipv4_recv_bytes" ]
打印标题 print ( "%-10s %-12s %-10s %-10s %-10s %-10s %-10s" % ( "PID" , "COMM" , "RX_KB" , "TX_KB" , "RXSUM_KB" , "TXSUM_KB" , "SUM_KB" ) )
输出数据 &#61; 0 &#61; 0 &#61; 0 &#61; 0 &#61; False while i !&#61; args. count and not exiting: try : sleep( args. interval) except KeyboardInterrupt: exiting &#61; True ipv4_throughput &#61; defaultdict( lambda : [ 0 , 0 ] ) for k, v in ipv4_send_bytes. items( ) : key&#61; get_ipv4_session_key( k) ipv4_throughput[ key] [ 0 ] &#61; v. valueipv4_send_bytes. clear( ) for k, v in ipv4_recv_bytes. items( ) : key &#61; get_ipv4_session_key( k) ipv4_throughput[ key] [ 1 ] &#61; v. valueipv4_recv_bytes. clear( ) if ipv4_throughput: for k, ( send_bytes, recv_bytes) in sorted ( ipv4_throughput. items( ) , key&#61; lambda kv: sum ( kv[ 1 ] ) , reverse&#61; True ) : recv_bytes &#61; int ( recv_bytes / 1024 ) send_bytes &#61; int ( send_bytes / 1024 ) sumrecv &#43;&#61; recv_bytessumsend &#43;&#61; send_bytessum_kb &#61; sumrecv &#43; sumsendprint ( "%-10d %-12.12s %-10d %-10d %-10d %-10d %-10d" % ( k. pid, pid_to_comm( k. pid) , recv_bytes, send_bytes, sumrecv, sumsend, sum_kb) ) i &#43;&#61; 1
这部分是python处理数据的过程&#xff0c;需要注意的是&#xff1a;ipv4_throughput &#61; defaultdict(lambda:[0,0])这里创建了一个名为ipv4_throughput的字典&#xff0c;将名为ipv4_send_bytes和ipv4_recv_bytes两个哈希表中的数据分别放到了名为ipv4_throughput的字典中&#xff0c;这样使得后续的数据处理更加统一。
for k, v in ipv4_send_bytes.items():这里将哈希表ipv4_send_bytes中的关键字和值使用.items的方法分别存放在了k和v中。
key&#61;get_ipv4_session_key(k)这里调用了get_ipv4_session_key(k)函数获取到了关键字&#xff0c;也就是pid。
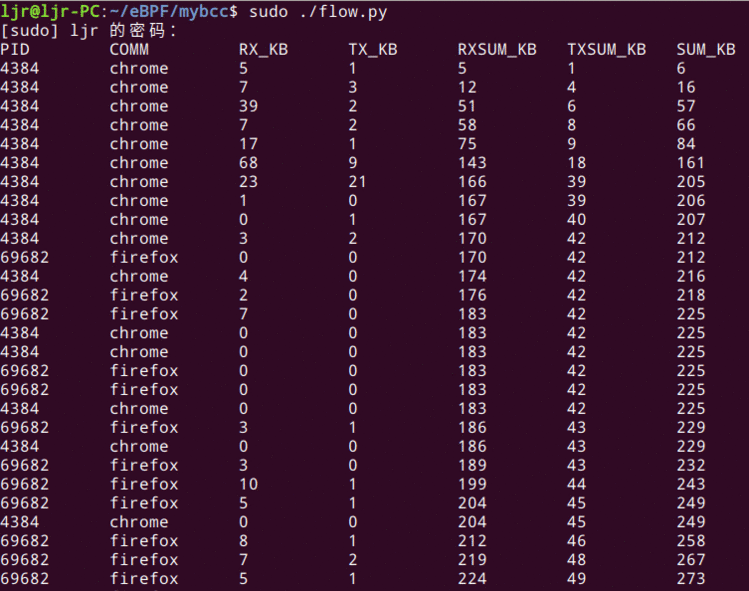
到此&#xff0c;一个基本的MVP就写好了&#xff0c;可以先跑一下&#xff0c;运行结果如下&#xff1a;
本实例只统计IPv4的流量&#xff0c;还可以加入统计IPv6的流量 可以添加更多的字段&#xff0c;如源地址&#xff0c;源端口&#xff0c;目标地址&#xff0c;目标端口 可以加入更多的选项参数等 目前介绍到这里&#xff0c;我还会继续优化程序的&#xff0c;感谢阅读。







 京公网安备 11010802041100号
京公网安备 11010802041100号