使用RocketQA开发工具实现端到端问答系统
12.28~12.30日每晚8点,百度工程师将针对问答、检索、情感分析场景带来直播讲解,深入解读RocketQA等系统方案,并带来手把手项目实战。报名链接
问答系统(Question Answering System, QA)是信息检索系统的一种高级形式,它能用准确、简洁的自然语言回答用户用自然语言提出的问题。问答系统在搜索引擎、智能客服和智能助手等应用场景中都发挥着重要作用。检索式问答系统是问答系统的重要类别,它能从大量文本中检索出问题的答案。下图是检索式问答系统的功能示意。
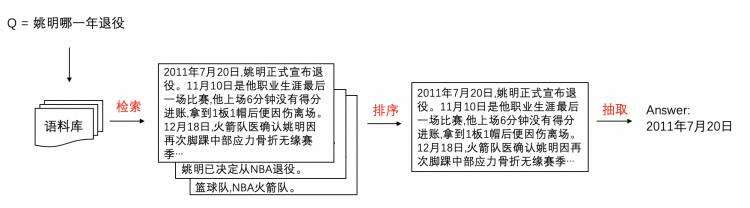
主流的检索式问答系统通常包含检索(retriever)、排序(reranker)和答案抽取(reader)等多个串行模块。随着大规模预训练模型的发展,研究人员开始探索基于深度语义表示的问答模型。得益于预训练模型生成的高质量语义表示空间和端到端的训练方法,语义模型能够提供更优质的结果,并且简化了传统问答系统的级联架构和特征工程方案,使系统的复杂性大大降低。
在此背景下,百度NLP提出了一系列基于语义的问答模型–RocketQA。RocketQA系列工作不仅被自然语言处理领域的多个国际顶级会议录取,也在百度的搜索业务中发挥了重要作用。为了使更多研发人员能够方便地获取最先进的问答语义检索与排序技术,百度NLP联合飞桨共同发布了基于RocketQA的开发工具。
本示例介绍了RocketQA开发工具的功能,演示如何基于该工具搭建一套问答系统。
RocketQA工具的基本功能
1、提供训练好的RocketQA模型和简单易用的模型预测api。
2、提供基于RocketQA模型搭建问答系统的简单方案。
项目亮点
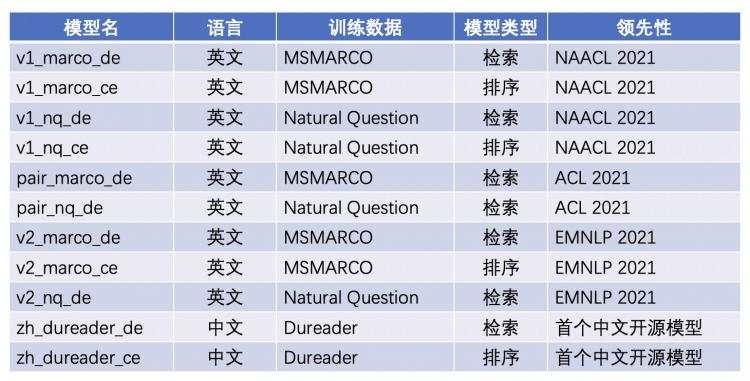
1、领先的问答模型:
RocketQA开发工具提供11个业界领先的预置模型,包括3篇***顶会论文***的共9个英文开源模型,和***首个中文***的开源语义检索、排序模型。
2、强大的中文能力:
RocketQA提供首个开源的中文端到端问答模型。模型是在强大的预训练语言模型ERNIE上,用百万量级人工标注数据集DuReader训练得到的,效果出众。
3、简单的开发接口:
RocketQA开发工具可以通过pip一键安装,同时也提供了装有所有依赖的docker镜像。
工具提供精简的开发接口和使用样例,仅需两行命令即可搭建自己的问答系统。
项目详情和源码见:
https://github.com/PaddlePaddle/RocketQA
如果您觉得本案例有帮助,欢迎点击右上角的"喜欢",或者分享给别人~
使用说明
1、安装
!pip install rocketqa
Looking in indexes: https://pypi.tuna.tsinghua.edu.cn/simple
Collecting rocketqa
[?25l Downloading https://pypi.tuna.tsinghua.edu.cn/packages/77/23/0a22aee6dd29cf35796466519f1c532be42f8331325b5cdf72e98860383f/rocketqa-1.0.0-py3-none-any.whl (43kB)
[K |████████████████████████████████| 51kB 8.6MB/s eta 0:00:011
[?25hRequirement already satisfied: tqdm in /opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages (from rocketqa) (4.27.0)
Installing collected packages: rocketqa
Successfully installed rocketqa-1.0.0
import rocketqa
rocketqa_models = rocketqa.available_models()
for m_name in rocketqa_models:print (m_name)
v1_marco_de
v1_marco_ce
v1_nq_de
v1_nq_ce
pair_marco_de
pair_nq_de
v2_marco_de
v2_marco_ce
v2_nq_de
zh_dureader_de
zh_dureader_ce
2、使用预置模型完成预测
import rocketqaquery_list = ["交叉验证的作用"]
title_list = ["交叉验证的介绍"]
para_list = ["交叉验证(Cross-validation)主要用于建模应用中,例如PCR 、PLS回归建模中。在给定的建模样本中,拿出大部分样本进行建模型,留小部分样本用刚建立的模型进行预报,并求这小部分样本的预报误差,记录它们的平方加和。"]
dual_encoder = rocketqa.load_model(model="zh_dureader_de")
q_embs = dual_encoder.encode_query(query=query_list)
p_embs = dual_encoder.encode_para(para=para_list, title=title_list)
print (q_embs.shape, q_embs.shape)
dot_products = dual_encoder.matching(query=query_list, title=title_list, para=para_list)
print (dot_products)
RocketQA model [zh_dureader_de]
Download RocketQA model [zh_dureader_de]4%|█▌ | 82.1M/1.84G [00:01<00:22, 85.1MiB/s]
3、搭建自己的检索式问答系统
A. 搭建问答系统的流程
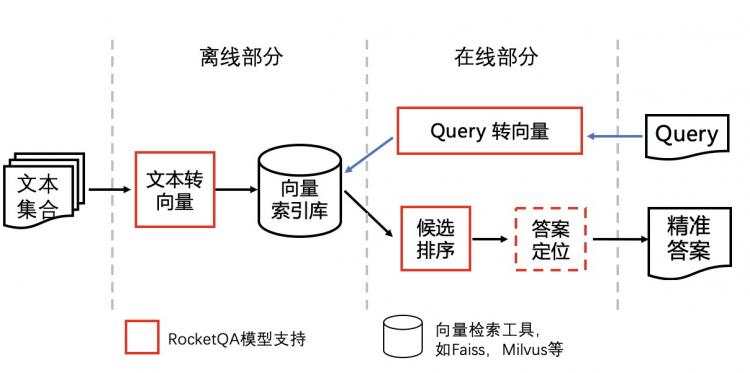
如上图&#xff0c;问答系统分为离线和在线两个部分。
离线部分&#xff0c;需要将待检索的文档转成向量&#xff0c;并建立向量索引。
在线部分&#xff0c;需要将查询语句转成向量&#xff0c;用向量从索引中检索相关内容&#xff08;通常返回不止一条结果&#xff09;&#xff0c;再对相关内容进行更精细的排序&#xff0c;得到最佳答案。
为了方便开发者使用&#xff0c;本项目提供了搭建问答系统的简单样例。
B. 使用Faiss搭建自己的问答系统
第一步&#xff1a;安装依赖
pip install faiss-cpu&#61;&#61;1.5.3
git clone https://github.com/PaddlePaddle/RocketQA.git
cd RocketQA/examples/faiss_example/
第二步&#xff1a;准备数据
按如下格式准备候选文档:
每一行是一条文档数据&#xff0c;包含文档标题和文档内容&#xff0c;标题与内容用\t分隔。如果没有标题&#xff0c;可用空字符串或’-&#39;代替
例如&#xff1a;
广西壮族自治区新型冠状病毒感染的肺炎 \t 感谢社会各界对我区抗击新型冠状病毒感染的肺炎疫情所给予的关心和大力支持&#xff01;...
第三步&#xff1a;建索引并启动检索服务
# 建立索引库
python index.py zh ${your_data} ${index_name}# 启动检索服务
!python rocketqa_service.py zh ${your_data} ${index_name} &
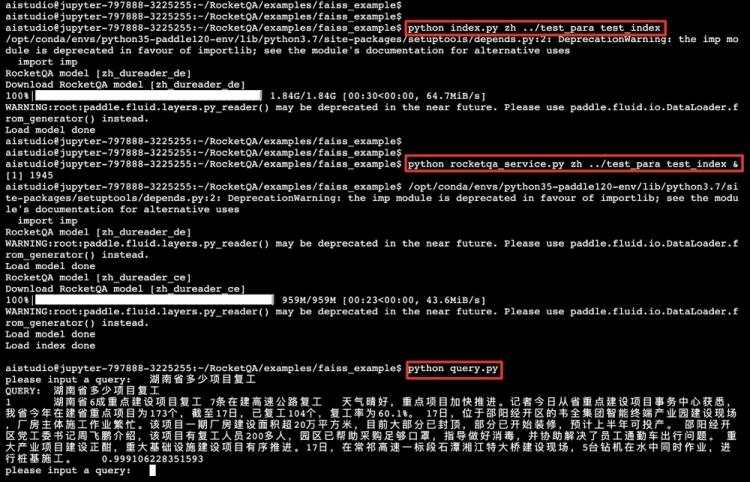
第四步&#xff1a;检索
python request.py
运行结果见下图&#xff1a;
C. 使用Jina搭建自己的问答系统
Jina是基于深度学习模型搭建搜索引擎的开源框架&#xff0c;将RocketQA模型嵌入Jina框架能快速搭建检索式问答系统。具体步骤如下&#xff1a;
第一步&#xff1a;安装依赖
git clone https://github.com/PaddlePaddle/RocketQA.git
cd examples/jina_example
pip install -r requirements.txt
第二步&#xff1a;准备数据
按如下格式准备候选文档:
每一行是一条文档数据&#xff0c;包含文档标题和文档内容&#xff0c;标题与内容用\t分隔。如果没有标题&#xff0c;可用空字符串或’-&#39;代替
例如&#xff1a;
广西壮族自治区新型冠状病毒感染的肺炎 \t 感谢社会各界对我区抗击新型冠状病毒感染的肺炎疫情所给予的关心和大力支持&#xff01;...
第三步&#xff1a;建索引并启动检索服务
python rocketqa_jina.py index ${your_data}
第四步&#xff1a;检索
python app.py query_cli
想了解详情可访问RocketQA开源项目



 京公网安备 11010802041100号
京公网安备 11010802041100号