实现系统调用
一、实验环境
本次操作还是基于上次编译Linux0.11内核的实验环境进行操作。环境如下:

二、实验目标
通过对上述实验原理的认识,相信你对系统调用有一定的了解。那本次实验是的目标是在Linux 0.11上添加两个系统调用,并编写两个简单的应用程序测试它们。第一个系统调用是iam(),其原型为:
int iam(const char * name);
完成的功能是将字符串参数name的内容拷贝到内核中保存下来。要求name的长度不能超过23个字符。返回值是拷贝的字符数。如果name的字符个数超过了23,则返回“-1”,并置errno为EINVAL。
第二个系统调用是whoami(),其原型为:
int whoami(char* name, unsigned int size);
它将内核中由iam()保存的名字拷贝到name指向的用户地址空间中,同时确保不会对name越界访存(name的大小由size说明)。返回值是拷贝的字符数。如果size小于需要的空间,则返回“-1”,并置errno为EINVAL。
在kernal/who.c中实现以上两个系统调用。
三、实验原理
1、系统调用(system call)
通过对操作系统课程的学习,我们知道操作系统的进程空间可分为用户空间和内核空间,它们需要不同的执行权限。其中系统调用运行在内核空间。在电脑中,系统调用,指运行在用户空间的程序向操作系统内核请求需要更高权限运行的服务。系统调用提供用户程序与操作系统之间的接口。大多数系统交互式操作需求在内核态运行。如设备IO操作或者进程间通信。
通俗一点的说,系统调用就是我们在写C语言代码的时候对各种库的调用,在写JAVA代码中对各种包的调用。只不过系统调用的代码由操作系统内核提供,运行于内核核心态,而普通的库函数和包调用由函数库或用户自己提供,运行于用户态。
在Linux0.11中应用程序、库函数和内核系统调用之间的关系如下图所示:
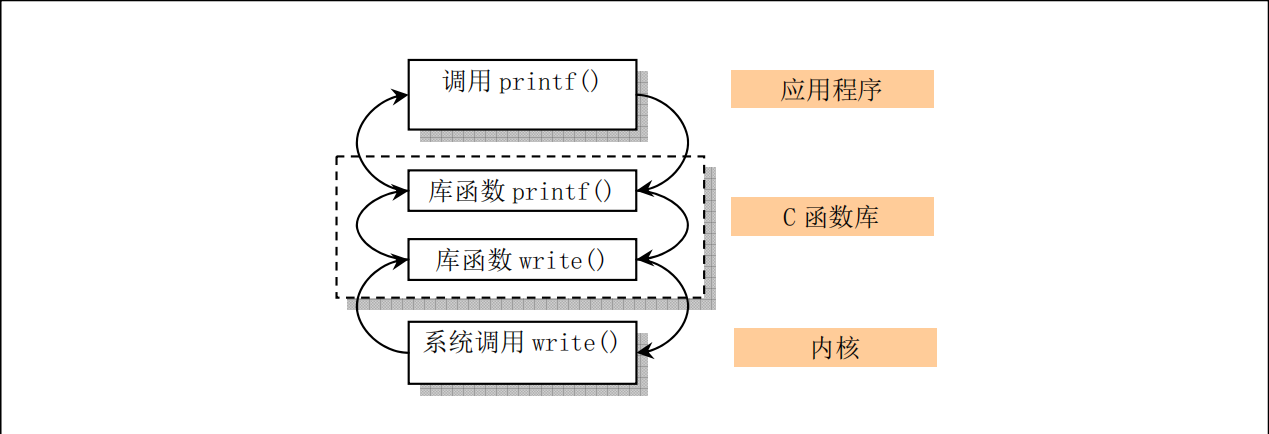
2、系统调用的实现过程
在通常情况下,调用系统调用和调用一个普通的自定义函数在代码上并没有什么区别,但调用后发生的事情有很大不同。调用自定义函数是通过call指令直接跳转到该函数的地址,继续运行。而调用系统调用,是调用系统库中为该系统调用编写的一个接口函数,叫API(Application Programming Interface)。API并不能完成系统调用的真正功能,它要做的是去调用真正的系统调用,过程是:
- 把系统调用的编号存入EAX寄存器中
- 把函数参数存入EBX,ECX等通用寄存器中
- 触发0x80号中断(int 0x80)
- 中断内核处理
- 系统调用
①解释
-
在Linux 内核中,每一个系统调用都是具有唯一的一个系统调用编号。这些编号定义在文件include/unistd.h中第60行开始处。这些系统调用编号实际上对应于include/linux/sys.h中定义的系统调用处理程序指针数组表sys_call_table[]中项的索引值。内核通过索引值启动对应的系统调用
-
EAX、EBX,ECX … 这些都是通用寄存器:AX、BX、CX 的扩展寄存器,前面的E就是extend。AX之类的寄存器是16位,而EAX之类的寄存器是32位。
-
0x80中断: 在计算机组成原理和操作系统的课程中,我们知道中断是指由于接收到来自外围硬件(相对于中央处理器和内存)的异步信号或来自软件的同步信号,而进行相应的硬件/软件处理。系统调用中断是用户程序使用操作系统资源的唯一界面接口。其在中断向量表当中的中断号为int 128(既0x80)。
-
中断内核处理过程:在内核初始化时,主函数(在init/main.c中,Linux实验环境下是main(),Windows下因编译器兼容性问题被换名为start())调用了sched_init()初始化函数:
void main(void)
{……time_init();sched_init();buffer_init(buffer_memory_end);……
}
sched_init()在kernel/sched.c中定义为:
void sched_init(void)
{……set_system_gate(0x80,&system_call);
}
set_system_gate是个宏,在include/asm/system.h中定义为:
#define set_system_gate(n,addr) \_set_gate(&idt[n],15,3,addr)
_set_gate的定义是:
#define _set_gate(gate_addr,type,dpl,addr) \
__asm__ ("movw %%dx,%%ax\n\t" \"movw %0,%%dx\n\t" \"movl %%eax,%1\n\t" \"movl %%edx,%2" \: \: "i" ((short) (0x8000+(dpl<<13)+(type<<8))), \"o" (*((char *) (gate_addr))), \"o" (*(4+(char *) (gate_addr))), \"d" ((char *) (addr)),"a" (0x00080000))
虽然看起来挺麻烦,但实际上很简单,就是填写IDT(中断描述符表),将system_call函数地址写到0x80对应的中断描述符中,也就是在中断0x80发生后,自动调用函数system_call。
-
系统调用过程:通过system_call函数进行系统调用。该函数纯汇编打造,定义在kernel/system_call.s中:
……
nr_system_calls = 72 # 这是系统调用总数。如果增删了系统调用,必须做相应修改
……
.globl system_call
.align 2
system_call:cmpl $nr_system_calls-1,%eax # 检查系统调用编号是否在合法范围内ja bad_sys_callpush %dspush %espush %fspushl %edxpushl %ecxpushl %ebx # push %ebx,%ecx,%edx,是传递给系统调用的参数movl $0x10,%edx # 让ds,es指向GDT,内核地址空间mov %dx,%dsmov %dx,%esmovl $0x17,%edx # 让fs指向LDT,用户地址空间mov %dx,%fscall sys_call_table(,%eax,4)pushl %eaxmovl current,%eaxcmpl $0,state(%eax)jne reschedulecmpl $0,counter(%eax)je reschedule
system_call用.globl修饰为其他函数可见。Windows实验环境下会看到它有一个下划线前缀,这是不同版本编译器的特质决定的,没有实质区别。call sys_call_table(,%eax,4)之前是一些压栈保护,修改段选择子为内核段,call sys_call_table(,%eax,4)之后是看看是否需要重新调度,这些都与本实验没有直接关系,此处只关心call sys_call_table(,%eax,4)这一句。根据汇编寻址方法它实际上是:
call sys_call_table + 4 * %eax # 其中eax中放的是系统调用号,即__NR_xxxxxx
显然,sys_call_table一定是一个函数指针数组的起始地址,它定义在include/linux/sys.h中:
fn_ptr sys_call_table[] = { sys_setup, sys_exit, sys_fork, sys_read,……
增加新的系统调用,需要在这个函数表中增加其对应函数引用——sys_xxx当然该函数在sys_call_table数组中的位置必须和__NR_xxxxxx的值对应上。
②案例
Linux0.11的lib目录下有一些已经实现的API。Linus编写它们的原因是在内核加载完毕后,会切换到用户模式下,做一些初始化工作,然后启动shell。而用户模式下的很多工作需要依赖一些系统调用才能完成,因此在内核中实现了这些系统调用的API。我们不妨看看lib/close.c,研究一下close()的API:
#define __LIBRARY__
#include
_syscall1(int,close,int,fd)
其中_syscall1是一个宏,在include/unistd.h中定义。将_syscall1(int,close,int,fd)进行宏展开,可以得到:
int close(int fd)
{long __res;__asm__ volatile ("int $0x80": "=a" (__res): "0" (__NR_close),"b" ((long)(fd)));if (__res >= 0)return (int) __res;errno = -__res;return -1;
}
这就是API的定义。它先将宏__NR_close存入EAX,将参数fd存入EBX,然后进行0x80中断调用。调用返回后,从EAX取出返回值,存入__res,再通过对__res的判断决定传给API的调用者什么样的返回值。其中__NR_close就是系统调用的编号,在include/unistd.h中定义:
#define __NR_close 6
所以添加系统调用时需要修改include/unistd.h文件,使其包含新添加的__NR_xxx。而在应用程序中,要有添加对应的接口空间,既_syscall 函数。如下所示:
#define __LIBRARY__ /* 有它,_syscall1等才有效。详见unistd.h */
#include /* 有它,编译器才能获知自定义的系统调用的编号 */_syscall0(type,name);
_syscall1(type,name,type1,arg1);
_syscall2(type,name,type1,arg1,type2,arg2);
/*其中,type表示所生成系统调用的返回值类型,name表示该系统调用的名称,typeN、argN分别表示第N个参数的类型和名称,它们的数目和_syscall后面的数字一样大。这些宏的作用是创建名为name的函数,_syscall后面跟的数字指明了该函数的参数的个数。
*/
四、实验过程
1、添加系统调用号
根据实验原理的内容,现在要新添加两个系统调用程序,就要在unistd.h给其分配对应的系统调用号。
过程如下:
cd oslab/linux-0.11/include/unistd.h

vim unistd.h
Vim的安装和使用方法请自行学习。
在132行和133行分别添加#define __NR_iam 72 和 #define __NR_whoami 73
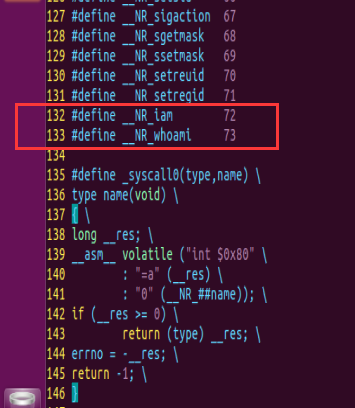
2、在系统调用函数表中添加新的系统调用函数
在include/linux/sys.h文件进行添加
cd oslab/linux0.11/include/linux

vim sys.h
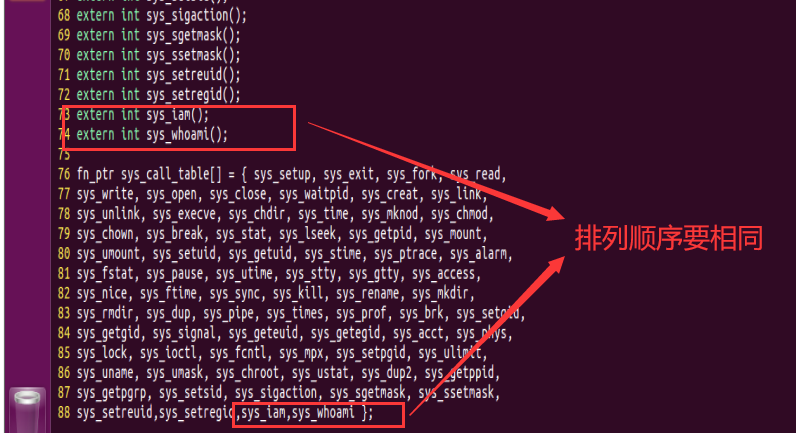
从73行开始,分别添加extern int sys_aim();和extern int sys_whoami();。
在最后一行的括号的末尾添加,sys_iam,sys_whoami。
注意:添加顺序要相同,不然最后程序运行时会报segmentation fault 错误,找不到运行程序。
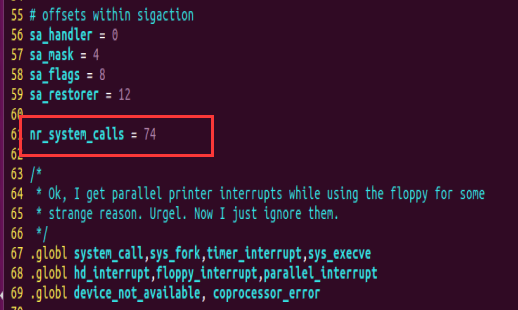
3、修改系统调用总数
因为新添加了两个系统调用函数,所以要在kernel/system_call.s把系统调用总数修改为74
cd oblab/linux0.11/kernel

vim system_call.s
在第61行中修改
4、实现系统调用服务例程
在kernel目录下创建who.c文件。
vim who.c
#include
#include
#include
#include static char str[24];
static unsigned long len;int sys_iam(const char* name) {int i;char tmp[24];for(i = 0; i < 24; i++) {tmp[i] = get_fs_byte(name + i);if(tmp[i] == 0) break;}if(i == 24) {return -(EINVAL);}for(i = 0; i < 24; i++) {str[i] = 0;}for(i = 0; tmp[i] != 0; i++) {str[i] = tmp[i];}len = i;return len;
}int sys_whoami(char* name, unsigned int size) {int i;if(size < len) {return -(EINVAL);}for(i = 0; i < size && str[i] != 0; i++) {put_fs_byte(str[i], name + i);}put_fs_byte(0, name + i);return len;
}
写好who.c文件后,要通过编译写入系统内核当中。所以要在kernel/Makefile文件中添加who.c的编译信息。
需要添加两处。一处是:
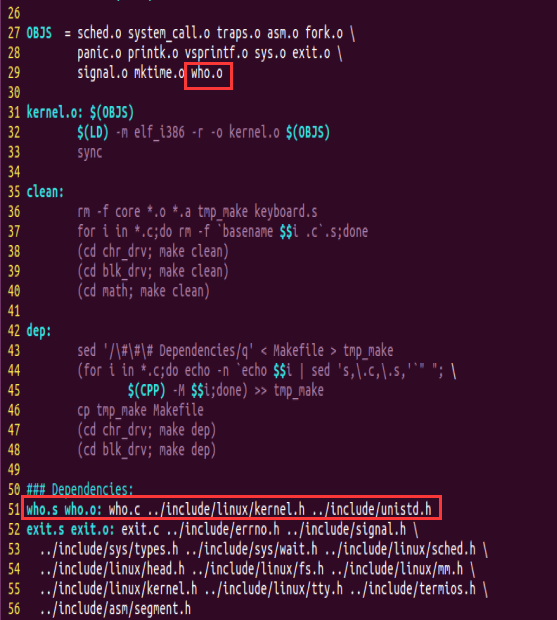
OBJS = sched.o system_call.o traps.o asm.o fork.o \panic.o printk.o vsprintf.o sys.o exit.o \signal.o mktime.o
改为:
OBJS = sched.o system_call.o traps.o asm.o fork.o \panic.o printk.o vsprintf.o sys.o exit.o \signal.o mktime.o who.o
另一处:
### Dependencies:
exit.s exit.o: exit.c ../include/errno.h ../include/signal.h \../include/sys/types.h ../include/sys/wait.h ../include/linux/sched.h \../include/linux/head.h ../include/linux/fs.h ../include/linux/mm.h \../include/linux/kernel.h ../include/linux/tty.h ../include/termios.h \../include/asm/segment.h
改为:
### Dependencies:
who.s who.o: who.c ../include/linux/kernel.h ../include/unistd.h
exit.s exit.o: exit.c ../include/errno.h ../include/signal.h \../include/sys/types.h ../include/sys/wait.h ../include/linux/sched.h \../include/linux/head.h ../include/linux/fs.h ../include/linux/mm.h \../include/linux/kernel.h ../include/linux/tty.h ../include/termios.h \../include/asm/segment.h
vim Makefile
6、编译
在linux0.11目录下进行编译
make all

最后一行是snyc,既编译成功
7、挂载虚拟硬盘
进入oslab目录
cd oslab

我们是通过mount-hdc文件挂载虚拟硬盘,既bochs虚拟机中的文件都是在oslab/hdc文件夹中
chmod 777 mount-hdc 提高运行权限
./mount-hdc 运行程序
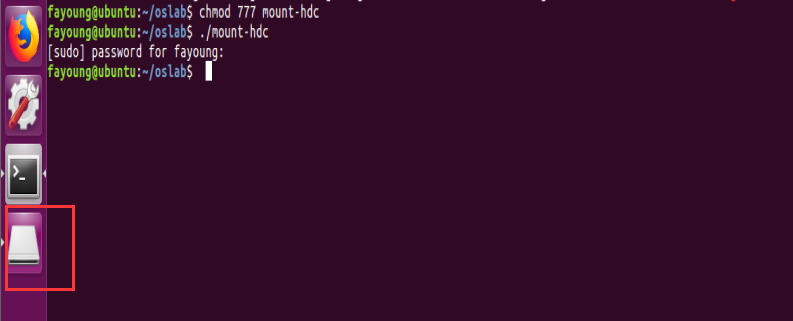
可以看到侧边出现了硬盘图标,说明挂载成功。
8、编写iam.c和whoami.c
进入到urs/root目录中编写程序
cd hdc/usr/root

vim iam.c
#define __LIBRARY__
#include
#include _syscall1(int, iam, char*, name)int main(int argc, char* argv[]) {if(argc <= 1){printf("input error\n");return -1;}iam(argv[1]);return 0;
}
vim whoami.c
#define __LIBRARY__
#include
#include _syscall2(int, whoami, char*, name, unsigned int, size)char name[25] = {};
int main(int argc, char* argv[]) {whoami(name, 25);printf("%s\n", name);return 0;
}

9、修改hdc/usr目录下的unistd.h和sys.h
虽然我们在linux0.11目录下修改了unistd.h和sys.h,但是在hdc/usr目录下的unistd.h和sys.h并没有被修改。修改内容也是跟之前一样。
cd oslab/hdc/usr/include

vim unistd.h
cd oslab/hdc/usr/include/linux

vim sys.h
10、测试程序
在oslab目录下进入bochs虚拟机

./run
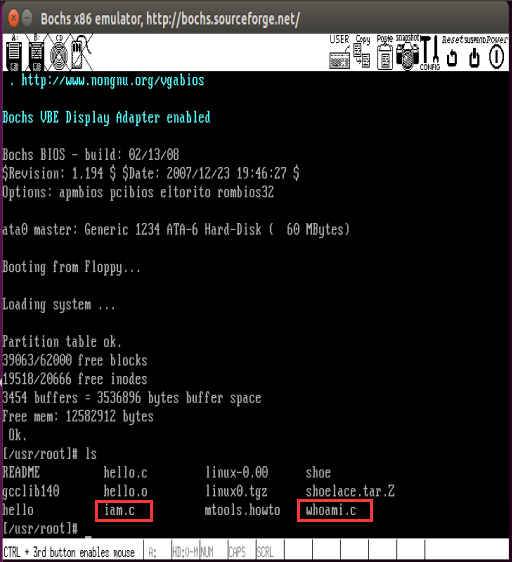
可见在当前源目录下,已经存在iam.c和whoai.c文件,直接编译即可。
gcc -o iam iam.c
gcc -o whoami whoami.c
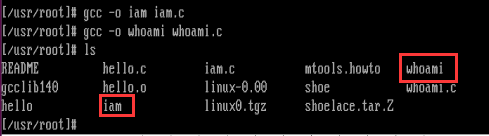
在编译之后,记得输入sync,保存编译文件
运行测试
./iam fayoung
./whoami

测试成功!






 京公网安备 11010802041100号
京公网安备 11010802041100号