
©PaperWeekly 原创 · 作者|俞雨
单位|瑞士洛桑联邦理工学院博士
研究方向|视线估计、头部姿态估计
本文七个篇章总计涵盖 29 篇论文,总结了自深度学习以来,视线估计领域近五年的发展。

概述
1.1 问题定义
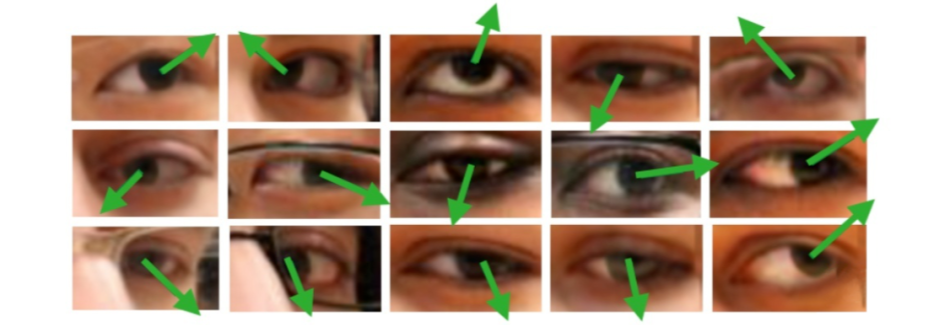
广义的 Gaze Estimation 泛指与眼球、眼动、视线等相关的研究,因此我看到有不少做 saliency 和 egocentric 的论文也以 gaze 为关键词。而本文介绍的 Gaze Estimation 主要以眼睛图像或人脸图像为处理对象,估算人的视线方向或注视点位置, 如下图所示。
与人脸相关的领域比,gaze 其实一直算一个小众的方向。这一点从顶会接收的论文数量就可以看出来。然而近些年随着数据和技术的发展,对 gaze 的需求渐渐浮出水面,这方面的研究也开始进入主流的视野。
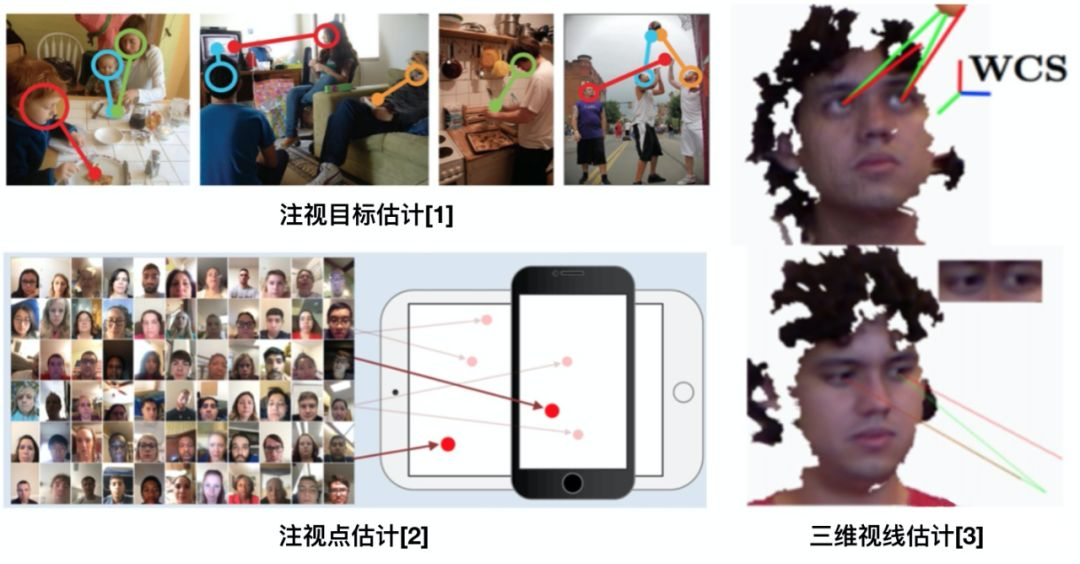
据我在 ECCV bidding 阶段的不完全统计,今年 gaze 相关的论文投稿达到了两位数(做大领域的大佬勿取笑)。目前,该领域的研究根据不同的场景与应用大致可分为三类,注视点估计、注视目标估计以及三维视线估计。这一部分内容会在以后的文章中展开介绍。
1.2 主要应用
gaze 作为反映人类注意力的行为,主要有如下应用。
游戏:通过估计 gaze 进行游戏的交互。这里有一个用 Tobii 眼动仪玩游戏的Demo:
https://v.youku.com/v_show/id_XNDAzNzc3MjEzNg==.html?spm=a2h0k.11417342.soresults.dtitle
VR:我去年在 CVPR 会场体验了 Facebook 的 VR 头盔,不得不感叹他们已将渲染效果做的如此科幻,不禁让人憧憬 VR 大规模应用的那天。然而现阶段 VR 的问题是全场景精细渲染对硬件要求较高导致硬件成本居高不下。
如果能够通过头盔内置摄像头准确估计人的视线方向,则可以对场景做局部精细渲染,即仅对人注视范围内的场景精细渲染,从而大大降低硬件成本。
医疗:gaze 在医疗方面的应用主要是两类。一类是用于检测和诊断精神类或心理类的疾病。一个典型例子是自闭症儿童往往表现出与正常儿童不同的 gaze 行为与模式。
另一类是通过基于 gaze 的交互系统来为一些病人提供便利。如渐冻症患者可以使用眼动仪来完成一些日常活动:
https://www.guancha.cn/society/2017_10_25_432195.shtml
辅助驾驶(智能座舱):gaze 在辅助驾驶上有两方面应用。一是检测驾驶员是否疲劳驾驶以及注意力是否集中。二是提供一些交互从而解放双手。
线下零售:我一直认为 gaze 在零售或者无人超市等领域大有可为,毕竟人的注意力某种程度上反映了其兴趣,可以提供大量的信息。但是我目前并没有看到相关的应用,包括 Amazon Go。
或许现阶段精度难以达到要求。我导师的公司倒是接过一个超市的项目,通过 gaze 行为做市场调研。但欧洲公司保密性较高,具体情况不得而知。
其他交互类应用如手机解锁、短视频特效等。
1.3 相关学术团队与公司
先列一下近些年在 gaze 领域较为活跃的几个团队,欢迎补充。其中 ETH 的 Otmar Hilliges 教授和东京大学的 Yusuke Sugano 教授也是我博士答辩的专家组成员。
EPFL 与 Idiap 的感知组:
https://www.idiap.ch/~odobez/
首先安利下我们团队,同时安利下我们最近两年的一些工作:
Improving Few-Shot User-Specific Gaze Adaptation via Gaze Redirection Synthesis, CVPR 2019
Unsupervised Representation Learning for Gaze Estimation, CVPR 2020
A Differential Approach for Gaze Estimation, PAMI accepted 2019
ETH 交互组:
https://ait.ethz.ch/people/hilliges/
德国马普所交互组(好像老大跳槽了?):
https://perceptualui.org/people/bulling/
微软剑桥研究院的 Erroll Wood:
http://www.errollw.com/
MIT Antonio Torralba 组:
http://web.mit.edu/torralba/www/
伦斯勒理工 Qiang Ji 组:
https://www.ecse.rpi.edu/~qji/
东京大学 Sugano 组:
https://www.yusuke-sugano.info/
北航 Feng Lu 组:
http://phi-ai.org/default.htm
工业界方面,据我所知目前主力依旧在欧美。大公司,如 Facebook Reality Lab(去年他们组织举办了第一届 gaze 相关的 challenge:https://research.fb.com/programs/openeds-challenge/,我们组在眼睛图片合成 track 中获得第二), 微软 Hololens,谷歌广告,NVIDIA 自动驾驶等团队都在致力于 gaze 方面的研究。
而专注于 gaze 的中小型公司,龙头老大当属瑞典公司 Tobii,其眼动仪已臻物美价廉之境。另外也可以关注下瑞士创业公司 eyeware(给导师打一波广告):https://eyeware.tech/ ,专注于提供解决方案,跟国内一些大厂已开展合作。
国内做 gaze 的公司应该较少,我只了解到华为与商汤在做这方面的工作。

注视目标估计

2.1 注视目标估计 [1]
注视目标估计英文关键词为 gaze following,即检测给定人物所注视的目标。MIT Antonio Torralba 组最先提出了这一问题并公开了相关数据集 [1]。
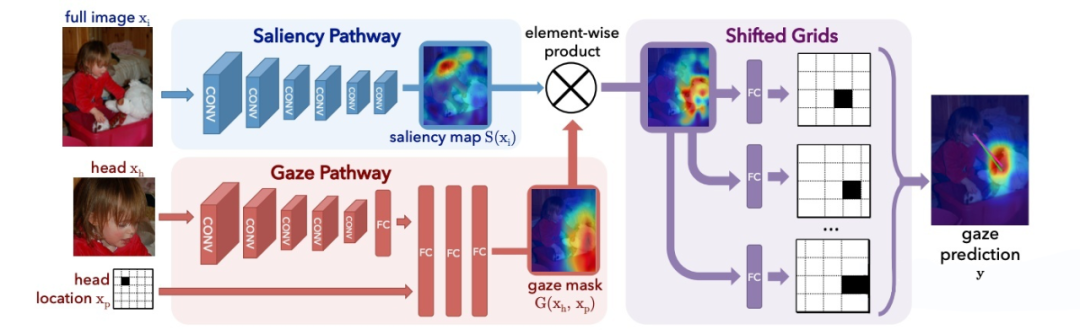
他们解决这一问题的主要思想简单而合理。如图所示,网络主要由两个支路组成,一个支路(Saliency Pathway)以原始图片为输入,用于显著性检测,输出为反映显著性的 heat map。
另一个支路(Gaze Pathway)以某一个人的头部图片和头部位置为输入,用于检测这个人可能的注视区域,输出同样是一个 heat map。
这两个 heat map 的乘积反映了目标显著性与可能的注视区域的交集,即可能的注视目标。整个网络以端对端的方式训练。以 AUC 为指标,文章最后得到了 0.878 的精度。
值得一提的是,这种结构设计也适用于多人注视目标的检测。只需要将 Gaze Pathway 中的头部图片与位置更换为另一个人的即可。然而这种方案的一大局限是,人与其注视的目标必须同时出现在同一张图片中。
这大大限制了其应用范围。为解决这一问题,作者们在 ICCV 2017 提出了针对视频的跨帧注视目标检测 [4],即人与注视目标可出现在不同视频帧中,如下图所示。

2.2 跨帧注视目标估计 [4]
这一问题显然更棘手,所以作者提出的解决方案也复杂了许多。
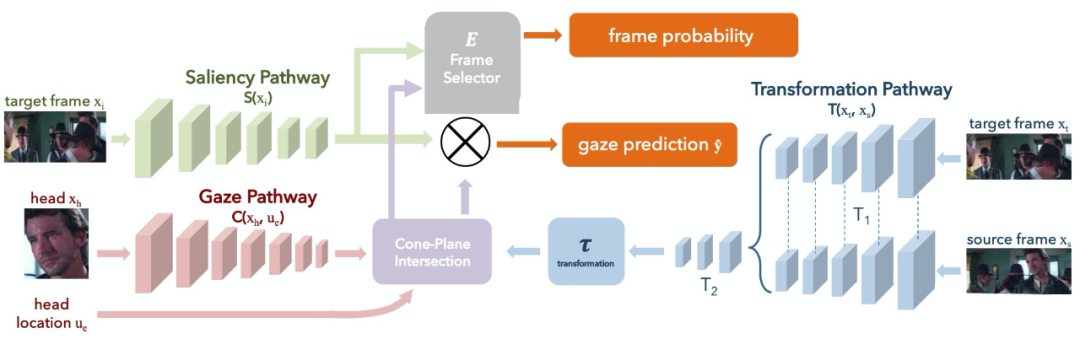
如图,整个框架由三条支路构成。与之前框架相比,现在的方案增加了一个 Transformation Pathway,用于估计 source frame(人所在帧)与 target frame(目标所在帧)的几何变换。而现在的 Gaze Pathway 则用于估计一个视锥的参数。
这两路网络的输出表示 source frame 中的人可能注视的 target frame 区域。下面的图更为直观。
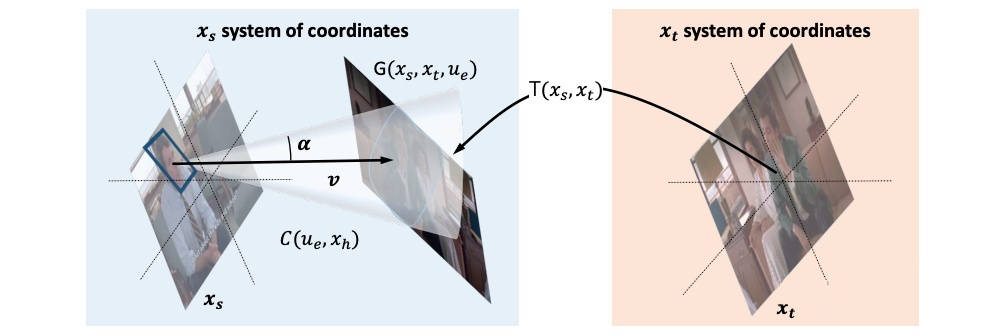
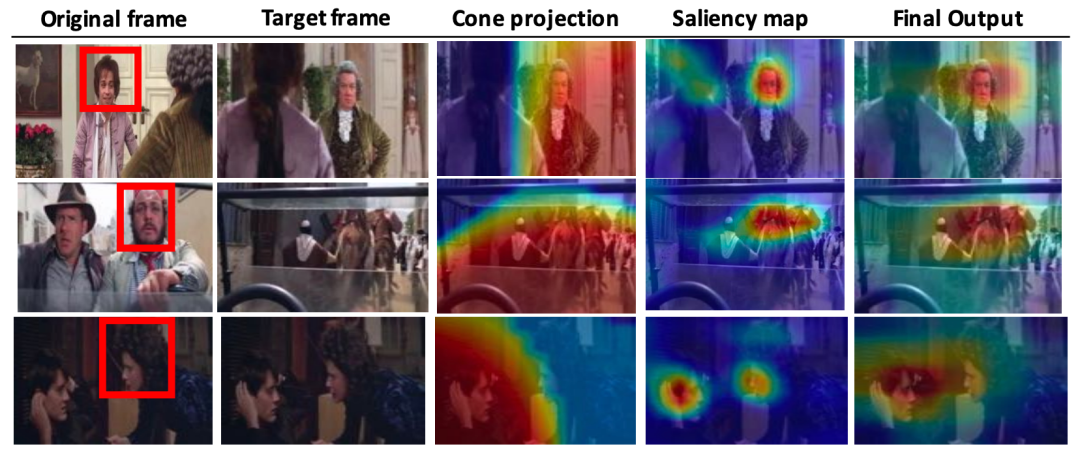
Saliency Pathway 的作用和之前的工作类似,用于估算目标显著性。三路网络的输出经融合后最终表示 source frame 中的人注视的 target frame 中的目标。下图清晰展示了整个推理过程。
小结:注视目标估计的相关论文目前较少。我这里先选两篇代表性的论文做简要介绍,具体细节请阅读原文。这两篇论文都公开了数据集和代码,参考链接:
http://gazefollow.csail.mit.edu/
https://github.com/recasens/Gaze-Following
下一小节会介绍下注视点估计的相关工作(这个方向的论文同样不多),然后再介绍 gaze 领域的重点研究对象,三维视线估计。

注视点估计
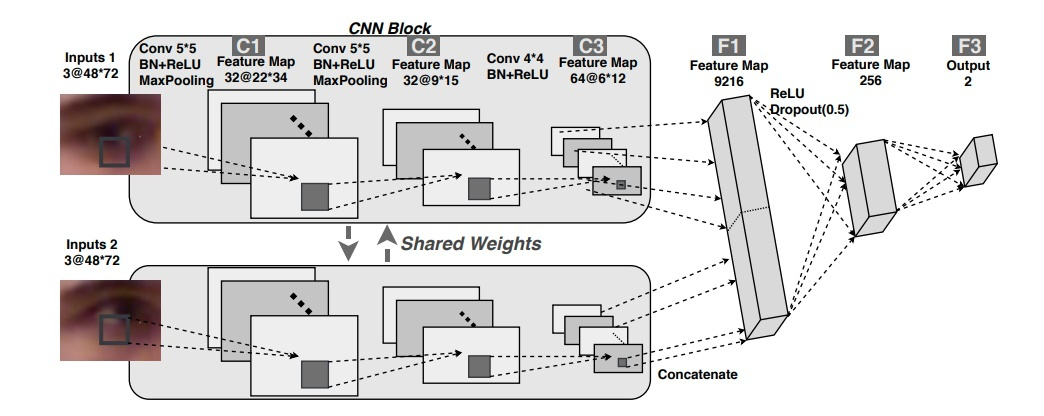
注视点估计即估算人双目视线聚焦的落点。其一般场景是估计人在一个二维平面上的注视点。这个二维平面可以是手机屏幕,pad 屏幕和电视屏幕等,而模型输入的图像则是这些设备的前置摄像头。下图是一个估计手机屏幕注视点的工作 [2]。
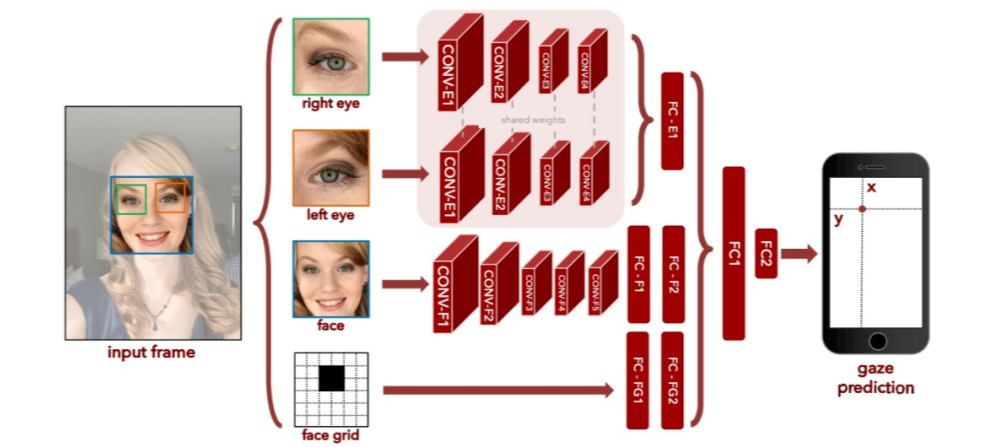
这个工作同样来自 MIT Antonio Torralba 组。网络结构一目了然,他有四个输入,左眼图像、右眼图像、人脸图像(由 iPhone 拍照软件检测)以及人脸位置。四种输入由四条支路(眼睛图像的支路参数共享)分别处理,融合后输出得到一个二维坐标位置。
实验表明,模型在 iPhone 上的误差是 1.71cm,而在平板上的误差是 2.53cm(误差为标注点与估计点之间的欧式距离)。该工作收集并公布了一个涵盖 1400 多人、240 多万样本的数据集,GazeCapture。
在上述模型中,人脸主要提供头部姿态信息(head pose),而人脸位置主要提供眼睛位置信息。这里存在一定的信息冗余。基于这一观察,Google 对上述模型做了进一步压缩 [5],即将人脸和人脸位置这两个输入替换为四个眼角的位置坐标,如下图所示。
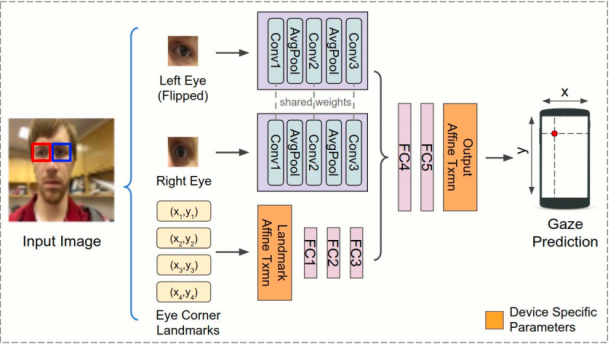
眼角位置坐标不仅直接提供了眼睛位置信息,同时又暗含 head pose 信息(眼角间距越小,head pose越大,反之头部越正)。
实验结果表明,这个精简后的模型在 iPhone 上的误差为 1.78cm,与原始模型的精度相差无几。同时,该模型在 Google Pixel 2 Phone 的处理速度达到 10ms/帧。
也许是看到了注视点估计在智能手机上的应用前景,三星在 2019 年也公开了相关研究 [6]。他们采取的网络架构与 [2] 类似,不同点是在网络训练过程中加入了 distillation 与 pruning 等技巧,来防止过拟合并获得更鲁棒的结果。
事实上,在 GazeCapture 之前,2015 年莱斯大学已公开了一篇针对平板的注视点估计论文 TabletGaze [7]。但当时的深度学习还不像今天这样盛行,作者使用了传统特征(LBP、HOG等)+ 统计模型的方式来解决这一问题(见下图)。
最后取得的结果与 [2] 相比有比较明显的差距。这里就不展开了。

最后放一张我 2017 年参加 FG(International Conference on Automatic Face and Gesture Recognition)时看到的 poster(应该是 demo session,没有文章)。作者将注视点估计应用到了智能座舱场景下。

小结:总的来讲,MIT 的工作 [2] 基本为注视点估计这几年的发展奠定了基础。在屏幕注视点这一场景下,我目前没有看到跳出他们框架与数据的论文。他们的数据、代码与模型都已公开,请参考他们的项目网页:
https://gazecapture.csail.mit.edu/
下一篇开始将进入这一系列文章的重头戏,三维视线估计。由于涉及到的内容会比较多,我计划分成三到四个篇章来讲解,每个篇章的内容也可能会比之前多很多。

三维视线估计(通用方法)
4.1 目标
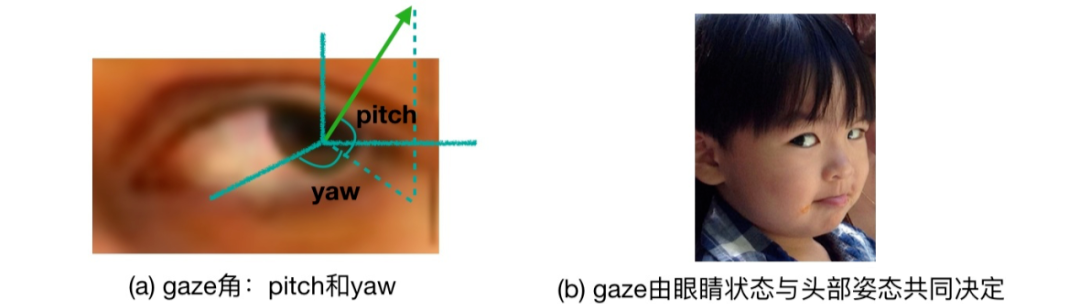
三维视线估计的目标是从眼睛图片或人脸图片中推导出人的视线方向。通常,这个视线方向是由两个角度,pitch(垂直方向)和 yaw(水平方向)来表示的,见下图a。
需要注意的是,在相机坐标系下,视线的方向不仅取决于眼睛的状态(眼珠位置,眼睛开合程度等),还取决于头部姿态(见图b:虽然眼睛相对头部是斜视,但在相机坐标系下,他看的是正前方)。
4.2 评价指标
在模型估计出 pitch 角和 yaw 角之后,可以计算出代表视线方向的三维向量,该向量与真实的方向向量(ground truth)之间的夹角即是 gaze 领域最常用的评价指标。
4.3 传统方法
一般来说,视线估计方法可以分为基于几何的方法(Geometry Based Methods)和基于外观的方法(Appearance Based Methods)两大类。基于几何的方法的基本思想是检测眼睛的一些特征(例如眼角、瞳孔位置等关键点),然后根据这些特征来计算 gaze。
而基于外观的方法则是直接学习一个将外观映射到 gaze 的模型。两类方法各有长短:几何方法相对更准确,且对不同的 domain 表现稳定,然而这类方法对图片的质量和分辨率有很高的要求。
基于外观的方法对低分辨和高噪声的图像表现更好,但模型的训练需要大量数据,并且容易对 domain overfitting。随着深度学习的崛起以及大量数据集的公开,基于外观的方法越来越受到关注。
本文主要介绍近五年来利用深度学习研究 gaze 的工作,对之前的传统方法可能会有所提及,但不会专门介绍。
在这一篇章中,我将主要介绍通用(person independent)的视线估计方法,即模型的训练数据与测试数据采集自不同的人(与之相对的是个性化视线估计,即训练数据与测试数据采集自相同的人)。
按照方法所依赖的信息,我将他们分类为单眼/双眼视线估计,基于语义信息的视线估计和全脸视线估计 三类。对每一类我将会筛选两到三篇具有代表性的论文进行介绍。
4.4 单眼/双眼视线估计
就我所知,德国马普所 Xucong Zhang 博士等最早尝试使用神经网络来做视线估计 [8],其成果发表在 CVPR 2015 上。这个工作以单眼图像为输入,所使用的网络架构如下图所示。
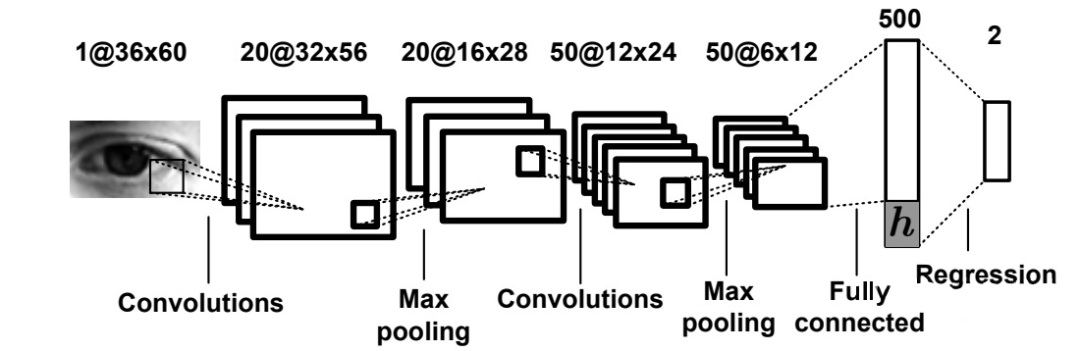
可以看到,他们当时使用的是一个类似于 LeNet 的浅层架构,还称不上“深度”学习。而其中一个有启发性的贡献是,他们将头部姿态(head pose)信息与提取出的眼睛特征拼接,用以学习相机坐标系下的 gaze。
该工作的另一个重要贡献是提出并公开了 gaze 领域目前最常用的数据集之一:MPIIGaze。在 MPIIGaze 数据集上,该工作的误差为 6.3 度。
接下来,Xucong Zhang 在他 2017 年的工作中 [9],用 VGG16 代替了这个浅层网络,大幅提升了模型精度,将误差缩小到了 5.4 度。
上面两个工作都以单眼图像为输入,没有充分利用双眼的互补信息。北航博士 Yihua Cheng 在 ECCV 2018 上提出了一个基于双眼的非对称回归方法 [10]。其方法框图如下:
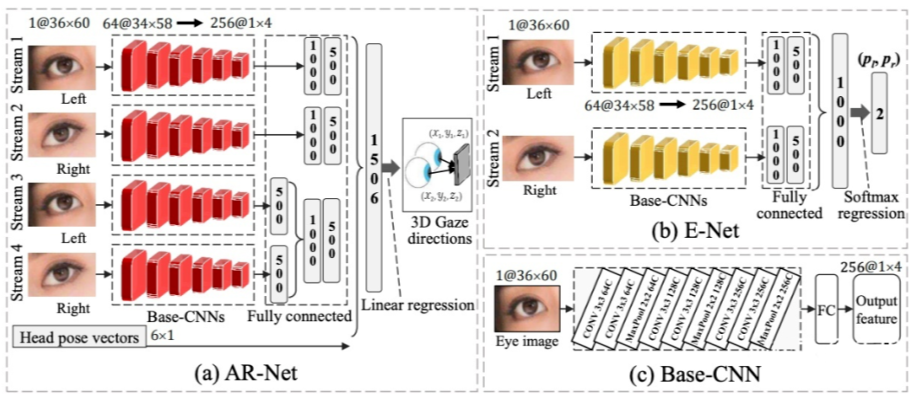
该工作由两个模块构成:AR-Net(非对称回归网络),以双眼为输入,经四个支路处理后得到两只眼睛的不同视线方向;E-Net(评价网络),同样以双眼为输入,输出是两个权重,用于加权 AR-Net 训练过程中两只眼睛视线的 loss。
其基本思想是,双眼中某一只眼睛可能因为一些原因(如光照原因等),更容易得到精准的视线估计,因此在 AR-Net 训练中应该赋予这只眼睛对应的 loss 更大的权重。该工作在 MPIIGaze 数据集上取得了 5.0 度的误差。
4.5 基于语义信息的视线估计
前面提到过,基于几何的方法是通过检测眼睛特征,如关键点位置,来估计视线的。这启发了一部分工作使用额外的语义信息来帮助提升视线估计的精度。ETH 博士 Park 等在 ECCV 2018 上提出了一种基于眼睛图形表示的视线估计方法 [11]。
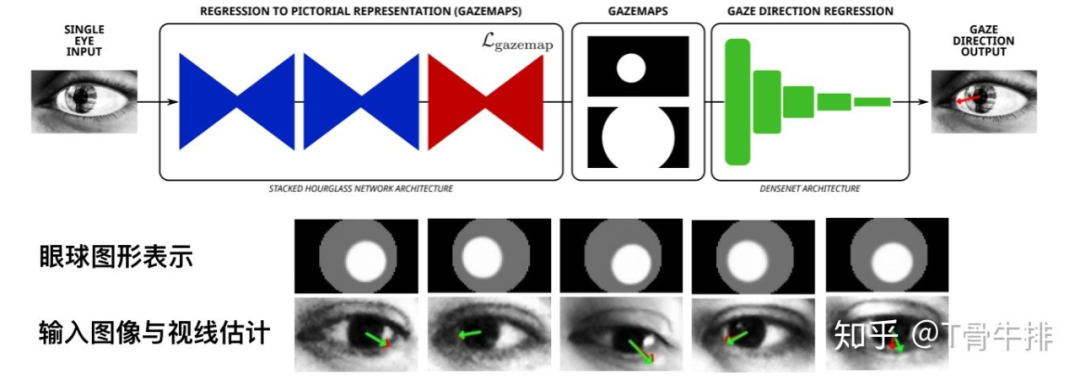
如图所示,他们通过深度网络将眼睛抽象为一个眼球图形表示来提升视线估计(这一表示相对 gaze 来说更具象也更易学习)。其中,眼球图形表示这一监督信号是由视线的 ground truth 经几何方法反推生成的。这一工作目前为止取得了在 MPIIGaze 上的最佳精度 4.56 度。
另外,感兴趣的同学也可以阅读他们在 ETRA 2018 上的工作 [12],利用眼睛关键点的 heat map 估计视线。方法框架如下图所示,其中眼睛关键点这一监督信息由合成数据集 UnityEyes 提供,这里不展开了。

我们组在 2018 年提出了一种基于约束模型的视线估计方法 [13],其基本出发点是多任务学习的思想,即在估计 gaze 的同时检测眼睛关键点位置,两个任务同时学习,信息互补,可以在一定程度上得到共同提升。
在我们的方法中,我们首先对眼睛关键点与视线的关系进行了统计建模。
具体地,对于合成数据集 UnityEyes 中的一个样本,我们抽取其 17 个眼睛关键点与两个 gaze 角度,将他们展开并拼接为一个 36 维(17*2 + 2)的向量。
然后将 n 个样本对应的 n 个向量堆叠生成一个 n*36 大小的矩阵,对该矩阵做 PCA 分解后可以得到一个 mean shape 和一系列 deformation basis。
这两个部分共同构成了一个约束模型。其中 mean shape 代表眼睛的平均形状以及对应的 gaze 平均值,而 deformation basis 则包含了眼睛形状与 gaze 的协同变化信息。约束模型的建立过程如下图所示。
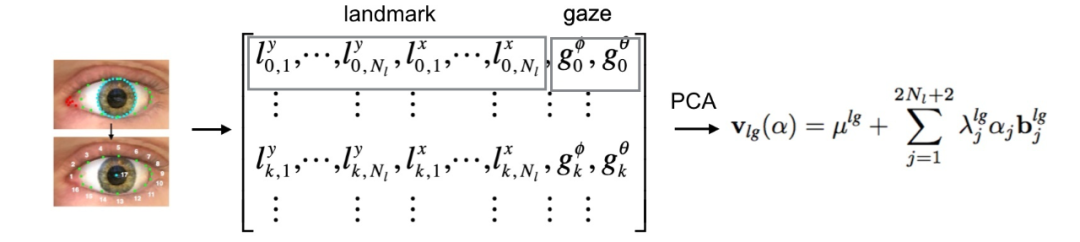
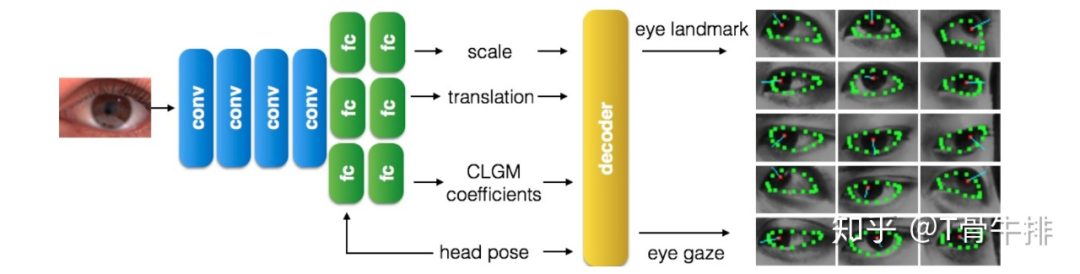
对于一个输入样本,如果能学习出这个约束模型中的 deformation basis 系数,并与 mean shape 组合,就可以重建出这个样本的眼睛形状和 gaze。因此我们使用的网络架构如下,网络的主要输出即约束模型的系数,用以重建眼睛的形状和 gaze。
另外,由于约束模型表示的眼睛形状是经过归一化操作的,网络同时学习一个缩放系数,和一个平移向量,通过几何变换(decoder)得到正确的眼睛关键点位置。网络通过优化关键点位置loss与视线 loss 实现 end to end training。
实验结果表明,我们的模型取得了比直接回归更精准的结果。
4.6 全脸视线估计
以上视线估计方法都要求单眼/双眼图像为输入,有两个缺陷:1)需要额外的模块检测眼睛;2)需要额外的模块估计头部姿态。基于此,Xucong Zhang 等于 2017 年提出了基于注意力机制的全脸视线估计方法 [14]。
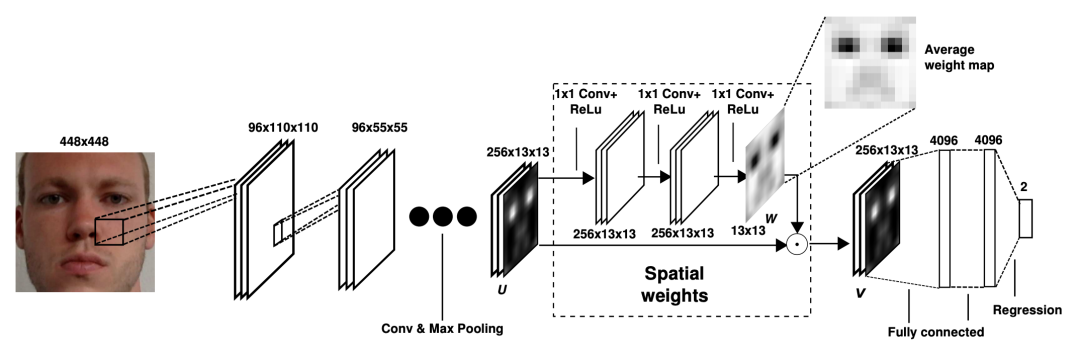
可以看到,这里注意力机制的主要思想是通过一个支路学习人脸区域各位置的权重,其目标是增大眼睛区域的权重,抑制其他与 gaze 无关的区域的权重。网络的输入为人脸图像并采用 end to end 的学习策略,直接学习出最终相机坐标系下的 gaze。
这一工作同时公开了全脸视线数据集 MPIIFaceGaze。需要注意的是,虽然 MPIIGaze 与 MPIIFaceGaze 使用的是同一批数据,但并不是同一个数据集(许多论文把这两个数据集混淆)。
首先 MPIIGaze 数据集并不包含全脸图片,其次 MPIIFaceGaze 的 ground truth 定义方式与 MPIIGaze 不同。该工作最终在 MPIIFaceGaze 数据集上取得了 4.8 度的精度。
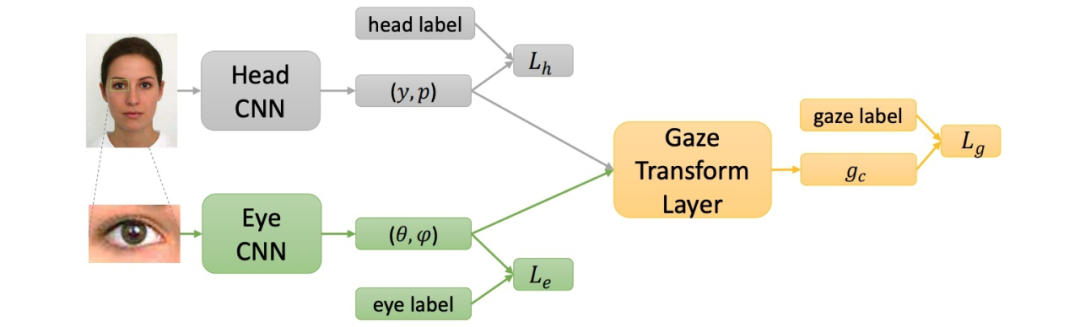
商汤在 ICCV 2017 上也发表了一个全脸视线估计的工作 [15]。与上面工作不同的是,除人脸输入外,该工作同时要求输入眼睛图片,如图所示。该工作主要认为工作 [8] 中 gaze 特征与 head pose 拼接的方式并不能准确地反映两者的的几何关系。
因此,该工作提出了一个 gaze 的几何变换层,用于将 head pose(人脸支路学习得到)与人脸坐标系下的 gaze(眼睛支路学习得到)进行几何解析,得到最终相机坐标系下的 gaze。该工作在自己收集的数据集上取得了 4.3 度的误差。
小结:不知各位读者发现没有,在 person independent(训练数据与测试数据采集自不同的人)这一设定下,上述方法的精度大都在 4-5 度之间徘徊,似乎很难得到进一步的提升。这个瓶颈主要是由人的眼球内部构造造成的。
如果希望继续提升精度,一般要使用个性化策略。这一部分内容准备在下下一个篇章中讲解。在下一篇章中,我会简要介绍三维视线数据如何收集标注的问题,以及如何在数据集短缺的情况下,训练一个 gaze 模型。

三位视线估计(数据集问题)
在本篇章中,我会简要介绍三维视线数据如何收集和标注的问题,以及如何在数据集短缺的情况下,训练一个 gaze 模型。
5.1 数据收集
与分类、检测等任务不同,三维视线难以人工标注,而需要专门设置一套复杂的系统或流程。本篇以 Eyediap 和 MPIIGaze 两个数据集为例,介绍两种 gaze 数据的收集和标注方法。
Eyediap 数据集 [16] 是我们组于 2014 年提出并公开的(当时本人尚未入组读博)。其基本的系统设定如下图所示。以 floating target 这一 session 为例,一位参与者坐在深度摄像头 Kinect 前,而一名实验人员则手握一根吊着乒乓球的棍子,操纵乒乓球在参与者面前随机运动。
参与者被要求始终盯着乒乓球,而深度摄像头则会记录下整个过程。数据收集完毕后,我们可以通过算法或人工的方式标注 RGB 视频中的眼睛中心点位置和乒乓球位置。
我们把这两个位置映射到深度摄像头记录的三维点云中,从而得到对应的三维位置坐标。这两个三维位置坐标相减后即得到视线方向。在我看来,这种数据收集和标注方式不仅精准而且相对简单。额外的要求就是需要一台深度摄像头。

另一种数据收集方式以 MPIIGaze [8] 为代表,仅仅需要普通的 RGB 摄像头即可。其基本做法是利用相机的公开参数,将 gaze 目标以及眼睛位置坐标(通过一个三维的 6 关键点模型得到)通过算法变换到相机坐标下,然后再计算 gaze 作为 ground truth。但是这种标注方法不仅操作复杂,而且并不准确。
由以上两个例子可以看到,gaze 数据的收集和标注比较耗时耗力。因此在实际应用中,如何在数据短缺的情况下训练一个可靠的 gaze 模型,就成了一个亟待解决的问题。
本篇剩余部分主要介绍三类针对数据短缺的解决方案:基于合成数据的方法、基于 Domain Adaptation 的方法以及基于无监督学习的方法。
5.2 基于合成数据的方法
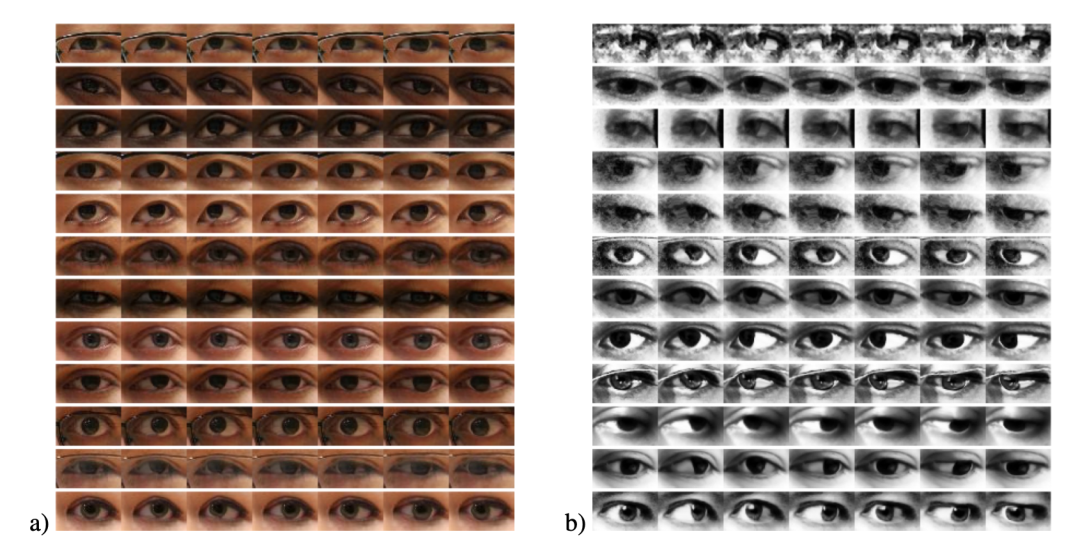
微软剑桥研究院的 Erroll Wood 博士在读博期间曾尝试使用计算机图形学的方法来合成眼睛样本 [17, 18],并公开了相关数据集。其中 UnityEyes 数据集因其真实性及丰富的标签信息(关键点位置)已经是 gaze 领域十分重要的数据集,被多篇工作使用。下图展示了一些 UnityEyes 合成数据样本。

在 [21] 中,Erroll Wood 展示了使用 UnityEyes 数据训练的简单的 k-NN 模型,可以在 MPIIGaze 上取得 9.95 度的精度。由于 [17, 18] 中的数据合成方法主要使用的是图形学技术,与本文讨论的主题有所不同,因此就不具体介绍了。
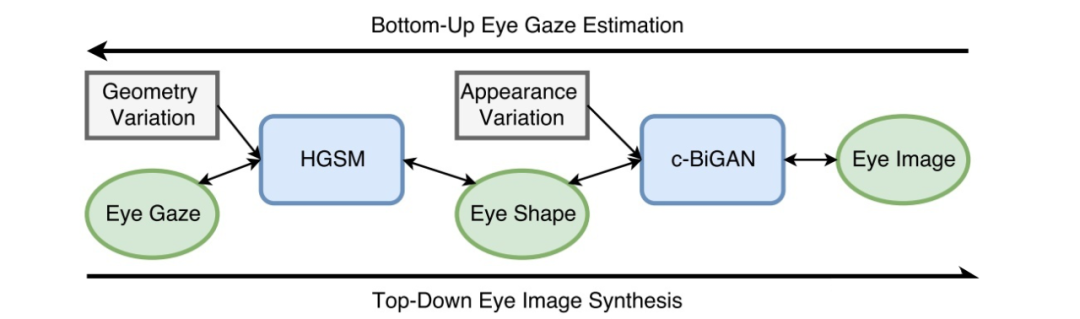
随着 GAN 的盛行,一部分研究者也开始使用神经网络的方式来合成数据。伦斯勒理工的 Kang Wang 博士在 CVPR 2018 上提出了一种分层的眼睛数据合成方法 [19],方法框架如下。
具体地,在数据合成流程中,用户先指定 gaze 数据,接着一个图模型模块(HGSM)生成相应的眼睛形状(由关键点表示),最后眼睛形状通过 GAN 合成眼睛图像。通过这种方式生成的眼睛图像自带 gaze 以及眼睛关键点这两个标签信息。
另外,在使用 GAN 合成数据的过程中,用户可自行选择某个数据集作为对抗学习的真实样本,这一特性保证了该框架可以用来生成多个 domain 的数据。实验结果表明,如果使用该框架合成的数据来训练模型,可以在 MPIIGaze 真实数据集上取得 7.6 度的误差。
5.3 基于Domain Adaptation的方法
在数据短缺的情况下,除了使用合成数据之外,另外一个思路是使用现有的数据集,通过 domain adaptation 的方式,将这个数据集变换到你所需要的 domain 中。
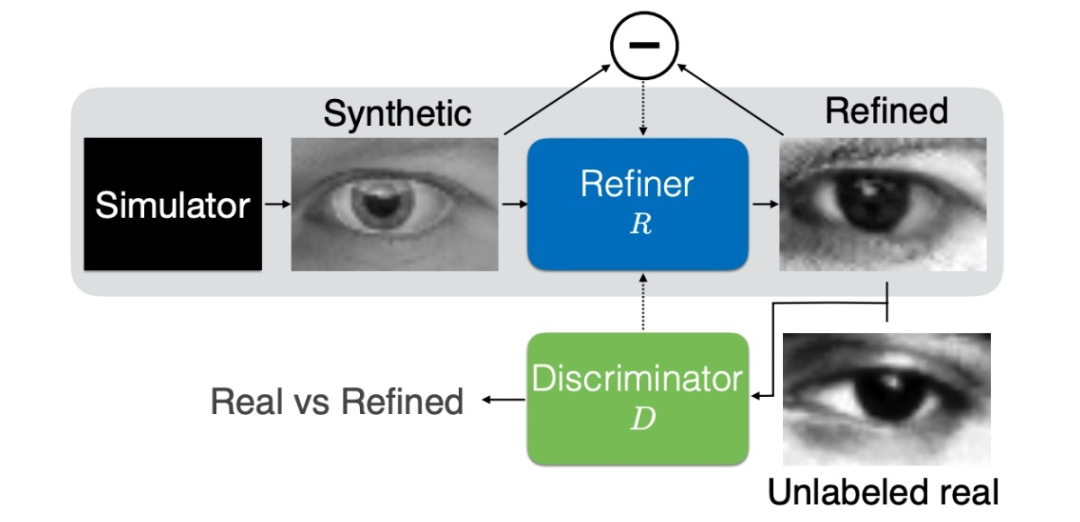
下面要介绍的工作想必大家都很熟悉了,来自 Apple 的 CVPR 2017 best paper:SimGAN [20]。该工作首先通过一个 Refiner 网络将输入图像变换到另一个 domain 中。
接下来,该工作一方面通过 L1 Loss 保证输入图像与输出图像的语义信息保持一致,另一方面通过对抗学习保证输出图像的 domain 与所需要的 domain 保持一致。
实验结果表明,如果使用变换后的合成数据(UnityEyes)来训练模型,其在真实数据集上的误差可以缩小 3.4 度。
5.4 基于无监督学习的方法
本篇最后介绍一下我们被 CVPR 2020 接收的最新工作 [21],从无标签的数据中学习 gaze 表征。实验表明,通过我们的方法学习到的 gaze 表征与真实值呈强线性关系。在实际使用时,仅需要极少量的标注样本(<=100),就可以得到有效可靠的视线估计模型。
据我所知,这应该是第一篇通过无监督的方式学习 gaze 的论文。
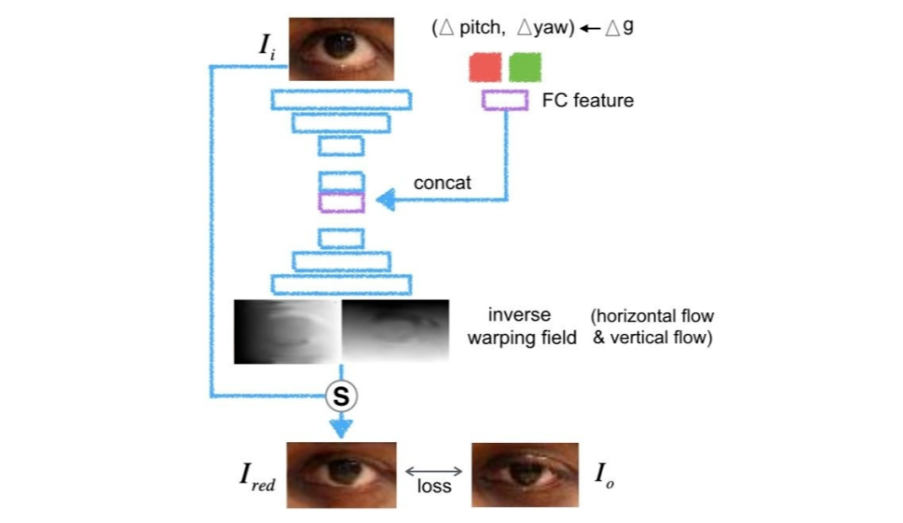
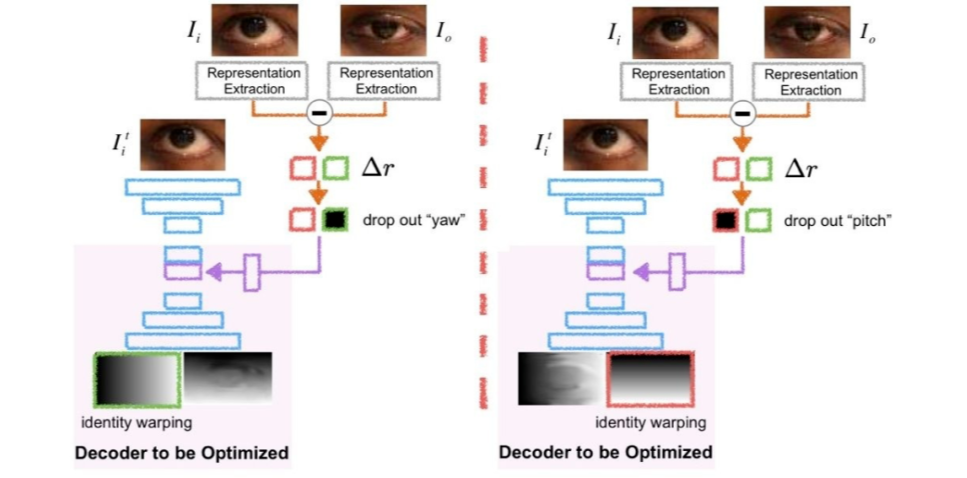
前情提要:这个工作的灵感来自于我们在 CVPR2019 上一篇关于视线重定向(gaze redirection)的工作 [22](在下一小节个性化视线估计中会详细介绍),通过改变眼睛的瞳孔位置或开合程度来改变视线,具体效果如下:
我们当时采取了如下网络结构。训练该网络需要输入样本,目标样本,以及输入样本与目标样本间 gaze 角度(包括垂直方向角度 pitch 与水平方向角度 yaw)的差值。
网络通过解析输入样本与 gaze 差值输出两个光流场(垂直和水平两个方向),来对输入图像的像素重定向,从而得到接近于目标图像的输出。
主要思想:在上面这个 idea 的基础上,我们想到为什么不用另一个网络模块来替代这两个 gaze 角度的差值呢?
具体地,这个网络模块由两个网络支路构成,一个支路处理输入图像,得到一个表征;另一个支路处理目标图像,得到另一个表征;然后用这两个表征相减后的差值来代替原来的 gaze 角度差值,如下图所示。
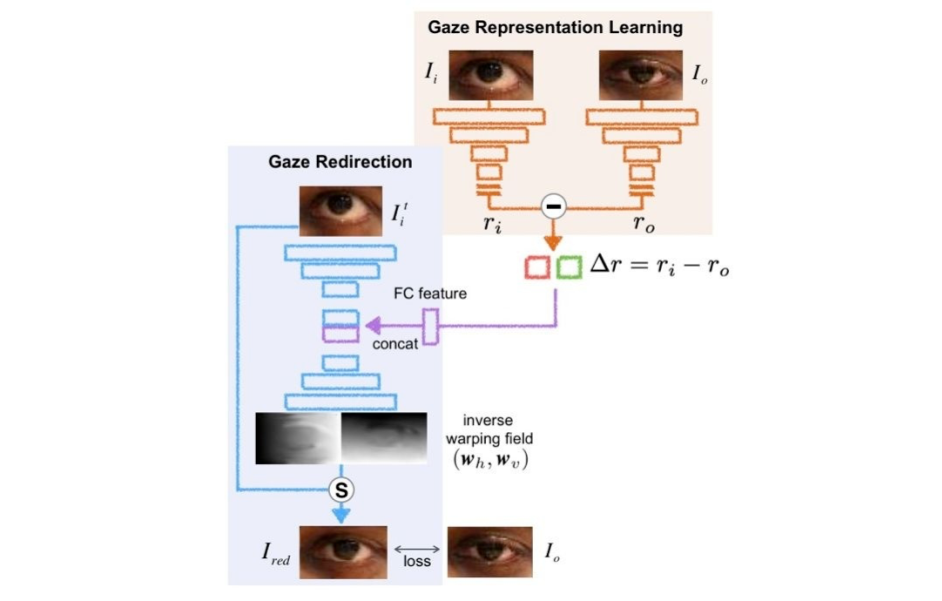
我们期望通过缩小最终的输出图像与目标图像之间的 loss,来迫使右上角的网络学习到 gaze 相关的表征(end to end training)。这样一来我们就可以不依赖任何标注数据而学习出 gaze 表征。这对于视线估计,这个数据标注十分复杂和困难的领域十分有意义。
需要注意的是,由于 gaze 由两个角度表示,我们的 gaze 表征也设定为二维。
赋予物理意义:至此,网络或许能够学习出 gaze 相关的表征,但我们并不清楚这个表征所表示的物理意义。我们观察到,当人的视线上下变化时,眼皮和眼珠等部位主要在垂直方向运动,水平方向的运动几乎为 0;当人的视线左右变化时,主要是眼珠在水平方向运动,几乎所有部位在垂直方向的运动为 0。
这也就是说,当垂直方向的 gaze 角度 pitch 变化(差值)为 0 时,视线重定向网络生成的垂直方向光流场应该接近于一个 identity mapping;而当水平方向 gaze 角度 yaw 变化(差值)为0时,水平方向光流场则接近于一个 identity mapping。
由此我们提出一个针对光流场的正则:一方面,我们人为将 gaze 表征的第一维修改为 0,然后输入重定向网络,并优化垂直方向光流场与 identity mapping 之间的差异;另一方面,我们人为将 gaze 表征的第二维修改为 0,输入重定向网络,优化水平方向光流场与 identity mapping 间的差异。
如下图所示。经此操作,gaze 表征的第一维即对应 pitch,第二维即对应 yaw。
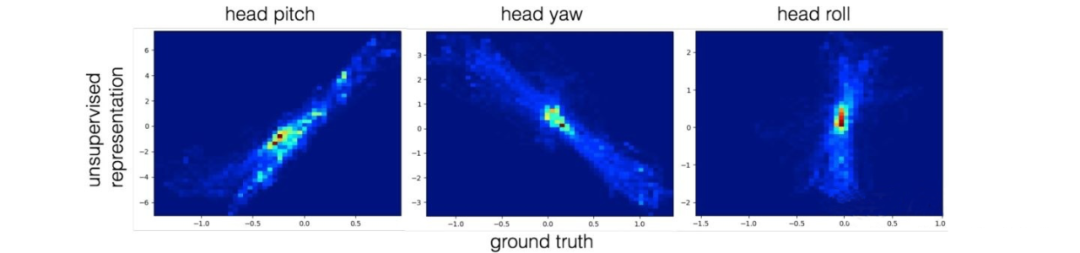
表征可视化:我们在三个数据集上进行了实验,分别是 Eyediap,ColumbiaGaze 和 UTMultiview,每个数据集使用 n-fold validation。
无监督学习到的 gaze 表征与 ground truth 的关系如下(第一行 pitch,第二行 yaw,图a. Eyediap: 5-fold,图b. ColumbiaGaze: 5-fold,图c. UTMultiview: 3-fold)。可以看到 gaze 表征与 ground truth 高度线性相关。

实验:得到 gaze 表征后,我们通过少量的标注样本(<=100)就可以将网络输出从表征空间映射到 gaze 空间,从而实现了小样本情况下的 gaze estimation。
在 Eyediap 数据集下,通过 100 张标注样本得到的实验结果可以接近 25000 张标注样本训练得到的结果。同时,在跨数据集的 setting 下,我们的无监督学习方法甚至超过了监督学习的方法。
扩展1-头部姿态估计:我们将提出的框架应用到了头部姿态估计(head pose estimation)这一任务中。我们使用 BIWI 数据集,表征可视化结果如下。可以看到由于缺少合适的正则项,roll 的表征学得并不好。但 pitch与yaw 的表征依旧和真实值呈现出了一定的线性关系。
扩展2-视线迁移:我们可以把 person A 的眼睛图片输入到表征学习网络中(抽取 A 的视线变化),而把 person B 的眼睛图片输入到视线重定向网络中,从而实现无监督视线迁移,即把 A 的 gaze 行为转移给 B。下面是一个 demo:
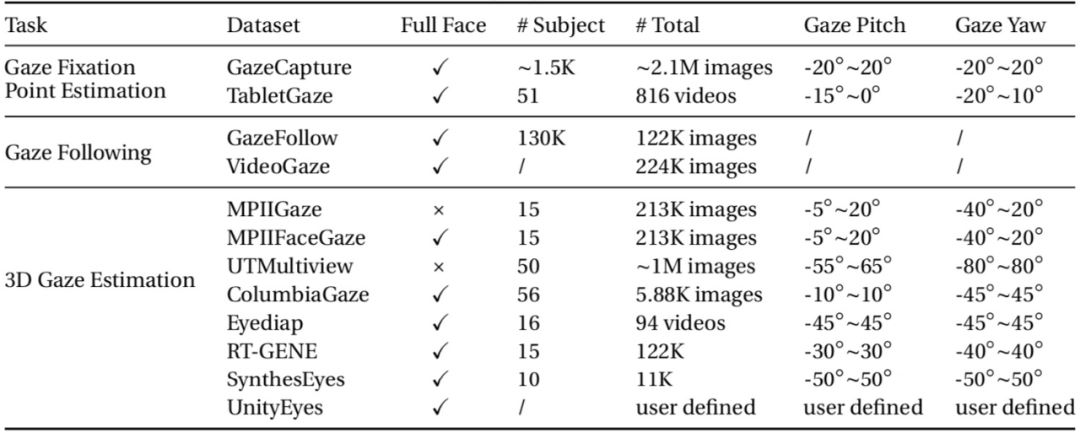
附录-常用数据集:本附录列举目前常用的 gaze 数据集及其特性,摘自我的博士毕业论文。
小结:本小节主要总结了在数据短缺的情况下,如何训练一个 gaze 模型。然而从结果上看,基于合成数据的方法和基于 Domain Adaptation 的方法,目前还难以接近使用真实数据训练的模型。从这个角度看,我更看好无监督或自监督学习在视线估计领域的发展。
另外,我也相信无监督学习在其他领域的成功,会为视线估计带来更多的启发和灵感。下一篇会主要介绍最近两年视线估计领域的研究热点,个性化视线估计。

三维视线估计(个性化问题)
在上上一篇中我们提到,在 person independent(训练数据与测试数据采集自不同的人)设定下,大部分主流视线估计方法的精度大都在 4-5 度之间徘徊,很难得到进一步的提升。
其主要原因是人与人之间存在一定的视线偏差。对于不同的两个人,即便眼球的旋转角度完全相同,其视线也会存在 2 到 3 度的不同。在本章节中,我将简要解释造成这种现象的原因,以及如何采用个性化方法解决这一问题。
6.1 视线偏差产生原因
视线偏差产生的原因当然跟每个人的眼睛形状,眼珠大小等因素相关。但这些因素导致的视线偏差事实上很小,并且这些都是视觉元素,他们与 gaze 的相关性是可以从图像中学习得到的。真正产生视线偏差的原因来自于眼球内部构造。
我师兄 Kenneth 在他 CVPR 2014 年的论文中 [23] 较详细的介绍了原因。
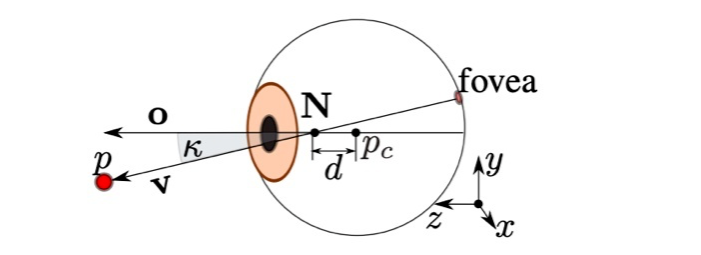
如图是一个眼球的构造图,其中 v 表示视线,o 表示 optical axis(瞳孔中心与眼球中心的连线,不知道中文该怎么翻),pc 是眼球中心,而 fovea 是视网膜上对光敏感度最高的一个点,N 则代表一个与眼球中心距离为 d 的节点。
直觉上来说,视线 v 应该就是瞳孔中心与眼球中心的连线。然而事实上,视线 p 是连接 fovea 与 N 的直线,它与我们通常认为的“视线”,即 optical axis 不同。
我们用 k 来表示视线 p 与 optical axis 的夹角,k 的大小因人而异,由人眼球内部参数决定,无法从图像中学习获得。了解了这个原因之后,我们就理解了为什么在 person independent 设定下,模型精度难以进一步提高的原因:训练数据的后验概率分布与测试数据的后验概率分布不同。
下面我用图表的方式更直观地描述一下视线偏差这个现象。在我们 PAMI 2019 的论文中 [24],我们用 person independent 模型分别对 Eyediap 数据集(图a)和 MPIIGaze 数据集(图b)中某一个人的样本做了测试,得到下图结果。
我们看到测试样本的估计值与真实值之间确实存在一定的偏差。而估计值相对真实值的分布,可以用一个线性模型 y = kx + b 来描述,其中截距 b 可以作为视线偏差的一个粗略估计。

本篇剩余部分主要介绍三类视线个性化估计方法,偏差消除方法,偏差估计方法与模型微调方法。大多数个性化估计方法都需要一定的个性化校准样本,而需要注意的是,考虑到实际应用的需要,这些方法都假设仅有极少量的个性化样本(<=9)。
6.2 偏差消除方法(差分网络)
我们介绍的第一种个性化估计方法是偏差消除法。具体策略非常直观,即模型估计的不再是某一张图像的视线,而是两张图像的视线差值(pitch 角差值与 yaw 角差值)。这一方法同样来自于我们 PAMI 2019 的论文 [24]。
注意这里的一个严格要求是用于估计视线差值的两个样本必须来自同一个人,只有这样才能保证减法操作可以消除偏差。方法的网络架构如图所示,网络的输入是同一个人的两个样本,经两路卷积网络(参数共享)处理后进行特征拼接,再经过两个全连接层后得到视线差。
而在测试阶段,我们则要求少量(<=9)的个性化校准样本(calibration sample)。我们把校准样本与待测样本(同一个人)输入网络,得到他们的视线差。然后将校准样本的真实值与视线差值相加即得到待测样本的视线估计值。
实验结果显示,用这种差分网络的方法,可以将 person independent 方法的误差缩小 1.5 度以上,达到 3 度左右。另外,实验结果也表明,使用一个简单的线性模型(见上一个小节)去做个性化校准也能得到较大幅度的性能提升。
6.3 偏差估计方法
前面提到过,视线偏差与图像的视觉元素无关,无法从图像中学习得到。但是我们可以通过其他信息去学习估算这个偏差。考虑到视线偏差是与人相关的,因此我们可以在训练中使用样本的 ID 信息去学习偏差。
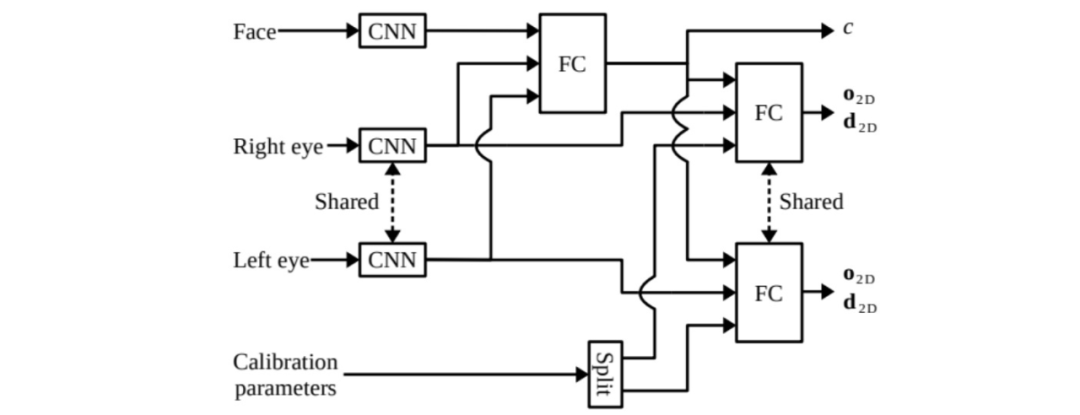
Tobii 团队在他们 2019 年的论文中 [25],就提出了这样一种思想。方法架构如图,我们忽略人脸和眼睛支路这些常见策略,而专注于方法的精髓:Calibration parameters。具体地,方法为每一个人分配一个 6 维的参数向量作为校准参数。
在训练过程中,方法根据当前样本的 ID 信息,使用相应的校准参数输入网络,并与网络参数被共同学习优化。这样,视线的估计就被分为了两个部分,一个是与图像和视觉相关的分量,而另一个是与 ID 信息相关的分量。
而在测试过程中,对于一个未在训练集中出现的人,方法再通过少量的校准样本(<=9)去学习这个人的校准参数(网络参数固定)。实验表明,该个性化方法在 MPIIGaze 数据集上可以获得 3 度左右的误差。
威斯康辛大学麦迪逊分校的 Yunyang Xiong 在 CVPR 2019 的论文中也提出了类似的思想 [26]。他们将视线估计分解为估计一个固定分量和一个与人相关的随机分量,如图所示。其中 T(Xi) 表示网络最后一个全连接层的输出,B 是固定分量参数,ui 则是随机分量参数(i 表示 ID 序号)。
该模型的参数通过 Variational EM + SGD 算法优化得到。而与前面的文章有所不同的是,在估计得到随机分量(偏差)后,该方法学习了一个从图像到偏差的映射,并在测试阶段,使用这个映射直接预测输入样本的偏差(因此该方法不需要校准样本)。
这种做法其实和我在本篇中一直强调的观点“视线偏差与图像的视觉元素无关,无法从图像中学习”相左。虽然说与 [24, 25] 这种利用校准样本的方法比,该方法在实验结果上有一定差距,但相比直接预测 gaze(不对偏差建模),确实有一定的提升。
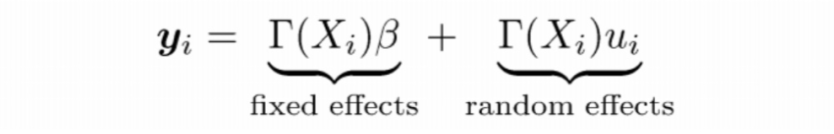
6.4 模型微调方法
最后一种个性化方法其实是最容易想到的方法,即使用校准样本对 person independent 模型进行 finetune(微调)。考虑到 [24, 25] 仅需要少量的标注样本即可得到较大的性能提升,我们的一个疑问是模型微调在仅有少量标注样本(<=9)的情况下是否可行。
答案是肯定的。在我们 CVPR 2019 的论文中 [22],我们发现使用 9 张样本对网络微调,即可得到 1 度左右的提升。
为了进一步提升个性化估计的效果,我们期望可以获得更多的样本用于模型微调。这里,我们使用视线重定向技术来生成更多的样本。我们在上一篇中已简要提及了视线重定向,为读者阅读方便,我们这里重复一下。
视线重定向是通过改变眼睛的瞳孔位置或开合程度来改变视线的技术。它原本应用于视频通话中,以确保通信双方始终保持眼神接触。视线重定向的直观效果可以参考第五篇的第一个视频。
我们使用的网络架构如下图所示。训练该网络需要输入样本,目标样本,以及输入样本与目标样本间 gaze 角度(包括垂直方向角度 pitch 与水平方向角度 yaw)的差值。网络通过解析输入样本与 gaze 差值输出两个光流场(垂直和水平两个方向),来对输入图像的像素重定向,从而得到接近于目标图像的输出。
在这个工作中,我们使用 UnityEyes 合成数据来训练网络,主要动机是合成数据集可以保证输入样本与目标样本间的光照条件、眼睛位置等信息相同,以方便训练(在后续工作中 [21],我们通过 perceptual loss 和 learning to align 放宽了这一限制)。
由于我们的最终目标是将网络应用到真实数据集上,因此我们还使用了 cycle loss 和 redirection loss 等自监督或半监督方法进行 domain adaptation。

网络训练完成后,我们就可以人为设定想要改变的视线角度(∆pitch, ∆yaw),利用校准样本来生成全新的数据。这些新生成的样本与原始样本相比,肤色、瞳孔颜色等信息均保持一致。所不同的是眼珠位置、眼睛开合程度等,如下图所示。
更重要的是,新生成的样本自带视线的标签。假设原始样本的视线标签是(pitch, yaw),那么新生成样本的标签是(pitch+∆pitch, yaw+∆yaw)。我们用原始标注样本与新生成的标注样本来对模型进行微调,即可以得到进一步的性能提升。
▲ 图a. ColumbiaGaze, 图b. MPIIGaze。第一列为原始样本,其余为视线重定向生成的样本
除了我们的工作外,ETH 的 Park 等人在 ICCV 2019 的工作中 [27],也尝试使用模型微调来提升个性化估计的效果。他们工作的核心思想是将针对一个人的个性化估计看做一个 task,而把个性化的过程看做针对这个 task 的 transfer learning,然后使用元学习方法 MAML 去解决问题。
除此之外,该工作还有两个重要贡献:1)提出了一种基于 disentangle 方式的 gaze 表征学习方法;2)对 GazeCapture 这一注视点估计的数据集重新标注,计算出相应的三维视线标签。该方法最终在 GazeCapture 数据集上实现了 3 度左右的误差。
小结:本小节主要总结了在仅有少量校准样本的情况下,如何进行有效的个性化视线估计。我们总结了三类个性化视线估计方法。总的来说,这三类方法并没有明显的高下之分,在使用个性化策略后,精度都可以达到 3 度左右。
这一方向是最近两年 gaze 领域的研究热点,我也会持续关注。下一篇可能是这个系列文章的最后一篇,我会简单介绍下几种处理头部姿态的方法。

三维视线估计(头部姿态问题)
在第四篇中,我们曾提到,视线的方向不仅取决于眼球的旋转,还取决于头部的姿态(head pose)。
如图,虽然眼睛相对头部是斜视,但在相机坐标系下,他看的是正前方。在大多数情况下,我们希望得到的是相对于相机坐标系的视线,那么如何在视线估计中有效使用头部姿态信息就成了一个非常值得研究的问题。
本篇我会介绍我所知的五类方法。其中前三类方法需要一个独立的前处理步骤事先估计出 head pose,而后两类方法则是在同一个框架内估计 head pose 和 gaze。

7.1 基于逐姿态视线估计的方法
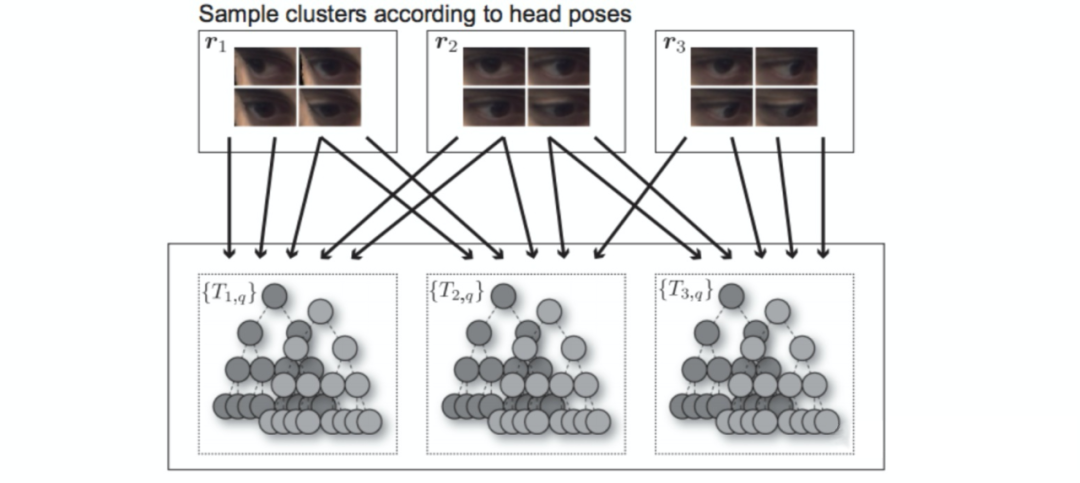
我介绍的第一种方法应该说是一种“最笨”的方法(抱歉名字翻译的很拗口),即先对 head pose 聚类,然后对每一类的样本分别训练一个 gaze 模型。其代表是东京大学的 Sugano 教授发表在 CVPR 2014 上的工作 [28],如图所示。
需要注意的是,为提高鲁棒性,该方法在训练一个随机森林时,也会用到相邻的 head pose 类的样本。这类方法的一大缺点是需要训练多个 gaze 模型,对实际应用参考意义不大。
7.2 基于视角变换的方法
第二类方法来自我师兄 Kenneth 发表在 2012 年的工作 [29]。
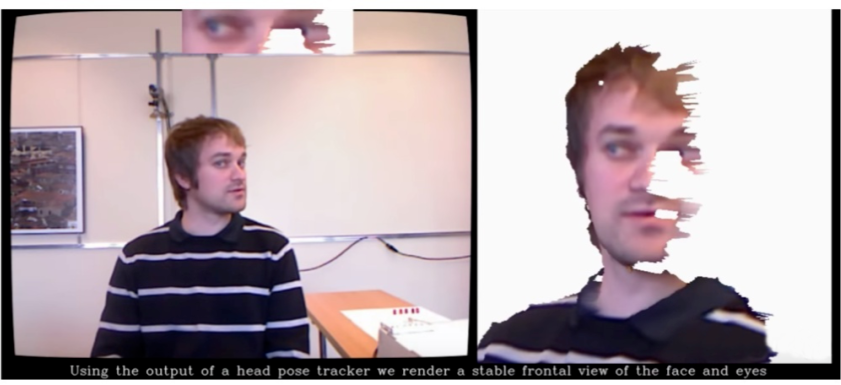
这类方法的一个前提条件是需要一个深度摄像头获取点云数据。在计算得到 head pose 之后,该方法利用 head pose 信息对点云数据作几何逆变换,从而得到前视视角(frontal view)的人脸或眼睛图像,如下图所示。
该方法使用前视视角的样本训练 gaze 模型,再把估计得到的 gaze 利用 head pose 信息变换到相机坐标系。由于眼睛图像被统一变换到前视视角,可以认为这些训练样本处于同一个 pose 空间,因此该方法训练的模型相对比较准确。
但这类方法也有两大缺点,一是需要深度摄像头(普通摄像头无法操作),二是在 head pose 较大时,视角变换后的样本信息会有所缺失(如图右侧眼睛)。
7.3 基于特征拼接的方法
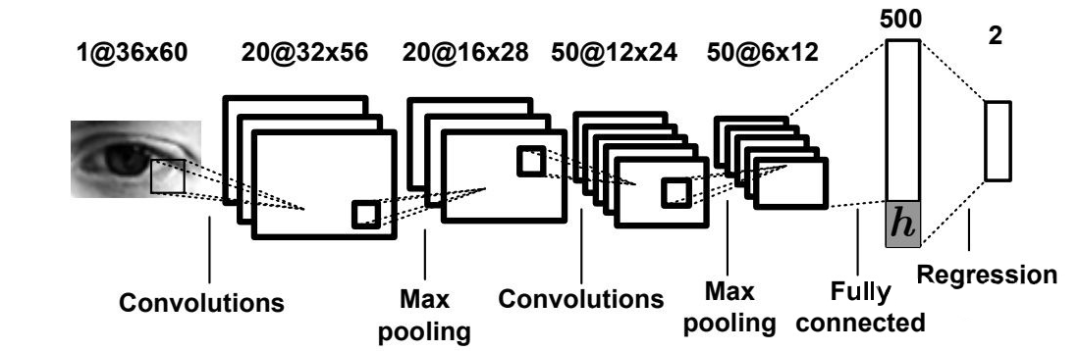
这类方法已在第四篇提及,其代表是德国马普所 Xucong Zhang 博士在 CVPR 2015 上的工作 [8]。方法架构如图,他们将头部姿态(head pose)信息与提取出的眼睛特征拼接,用以学习相机坐标系下的 gaze。
这类方法本质上是用全连接层去拟合几何变换操作(特征拼接后使用更多的全连接层会达到更好的效果)。一大优点是简便易用,效果也不错。个人比较推荐这类方法。
7.4 基于几何变换的方法
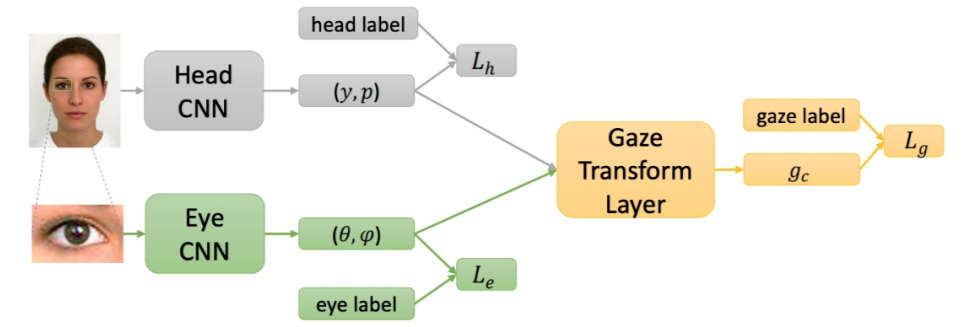
前面三类方法需要一个独立的模块事先估计 head pose。而一旦这个模块估计的 head pose 不够准确,后面的视线估计模块也会受到影响,因此容错性较差。这类方法的代表作是商汤在 ICCV 2017 上发表的一个全脸视线估计工作 [15]。
该工作主要认为特征拼接的方式并不能准确地反映 gaze 与 head pose 的的几何关系。
因此,该工作提出了一个 gaze 的几何变换层,用于将 head pose(人脸支路学习得到)与人脸坐标系下的 gaze(眼睛支路学习得到)进行几何解析,得到最终相机坐标系下的 gaze,如图所示。
该方法将 head pose 的估计和 gaze 的估计放在一个框架内(所需要的前处理步骤主要是眼睛的定位),因此容错性更大。
7.5 基于头部姿态隐式估计的方法
其代表是 Xucong Zhang 等于 2017 年提出的基于注意力机制的全脸视线估计方法 [14]。网络的输入是人脸图像,并采用 end to end 的学习策略,直接学习出最终相机坐标系下的 gaze。
因此我们可以认为这类方法隐式估计了 head pose。这类方法的优点是简单直接,但内部机制不明,可解释性较差。
小结:本篇主要介绍了五类处理头部姿态问题的方法。从我比较熟悉的单眼/双眼视线估计来说,我更推荐第三种方式:基于特征拼接的方法。商汤的论文 [15] 认为特征拼接并不是一个好的方式。
他们通过在 MPIIGaze 上做实验发现处理 head pose 的 weight 几乎等于 0,进而得出特征拼接效果欠佳这一结论。我认同这一现象,但不认同其结论。
事实上,在我看来,造成这一现象的真正原因是MPIIGaze提供的head pose非常非常不准确,能提供的有效信息十分有限,用不用head pose差别不大(结果差0.1度左右)。
相反,如果换做其他数据集,如 ColumbiaGaze 和 UTMultiview,特征拼接则会显著提高精度(至少提高 2 度)。
在我们 CVPR 2020 的论文中 [21],我们也比较了特征拼接和几何变换(网络的输入是单眼,输出是头部坐标系下的 gaze,然后通过事先获得的 head pose 对 gaze 进行几何变换,得到相机坐标系下的 gaze)两种方式,结果是特征拼接的效果明显好于几何变换(1-2 度)。
这个结果可能与我们的直觉相悖。我理解的原因是,一般来说,如果注视目标位于前方,则相机坐标系下的 gaze 范围更小,而头部坐标系下的 gaze 范围更大。有兴趣的话可以尝试一下,变换头部姿态,但眼睛始终盯着正前方一个物体。
如果这时正前方有一个摄像机,那么相机坐标系下你的 gaze 范围很小,接近于 0 度。但头部坐标系下的 gaze,根据你头部运动幅度的大小,范围可以很大。
拿 ColumbiaGaze 举例,相机坐标系下的 gaze yaw 的范围是 -15~15,而头部坐标系下的 gaze yaw 是 -45~45。因此,网络如果通过特征拼接的方式直接预测相机坐标系下的 gaze 的话,反而更容易学习。
写在最后:本文七个篇章总计涵盖了近 30 篇论文,总结了自深度学习以来,视线估计领域近五年的发展。 最近博士毕业正在找工作,以后不一定会从事这个方向,而中文 CV 圈中又很少有系统介绍 Gaze 的文章或博客,因此写下本文算留下个脚印。
参考文献
[1] Recasens, A., Khosla, A., Vondrick, C., and Torralba, A. Where are they looking? NIPS 2015.
[2] Krafka, K., Khosla, A., Kellnhofer, P., and Kannan, H. Eye Tracking for Everyone. CVPR 2016
[3] Funes-Mora, K. A. and Odobez, J.-M. Gaze estimation in the 3d space using rgb-d sensors, towards head-pose and user invariance. IJCV 2016
[4] Recasens, A., Vondrick, C., Khosla, A., and Torralba, A. Following gaze in video. ICCV 2017
[5] Junfeng He, Khoi Pham, Nachiappan Valliappan, Pingmei Xu, Chase Roberts, Dmitry Lagun, and Vidhya Navalpakkam. On-device few-shot personalization for real-time gaze estimation. ICCV Gaze Workshop 2019
[6] Tianchu Guo, Yongchao Liu, Hui Zhang , Xiabing Liu, Youngjun Kwak, Byung In Yoo, Jae-Joon Han, Changkyu Choi. A Generalized and Robust Method Towards Practical Gaze Estimation on Smart Phone. ICCV Gaze Workshop 2019
[7] Qiong Huang, Ashok Veeraraghavan, Ashutosh Sabharwal. TabletGaze: Unconstrained Appearance-based Gaze Estimation in Mobile Tablets. Machine Vision and Applications 2017
[] Zhang, X., Sugano, Y., Fritz, M., and Bulling, A. (2015). Appearance-based gaze estimation in the wild. In IEEE Conference on Computer Vision and Pattern Recognition (CVPR), pages 4511–4520
[9] Zhang, X., Sugano, Y., Fritz, M., and Bulling, A. (2017). MPIIGaze: Real-World Dataset and Deep Appearance-Based Gaze Estimation. IEEE Transactions on Pattern Analysis and Machine Intelligence (TPAMI), pages 1–14.
[10] Cheng, Y., Lu, F., and Zhang, X. (2018). Appearance-based gaze estimation via evaluation- guided asymmetric regression. In The European Conference on Computer Vision (ECCV).
[11] Park, S., Spurr, A., and Hilliges, O. (2018). Deep Pictorial Gaze Estimation. In European Conference on Computer Vision (ECCV), pages 741–757.
[12] Seonwook Park, Xucong Zhang, Andreas Bulling, Otmar Hilliges (2018). Learning to find eye region landmarks for remote gaze estimation in unconstrained settings. ACM Symposium on Eye Tracking Research and Applications (ETRA)
[13] Yu, Y., Liu, G., and Odobez, J.-M. (2018). Deep multitask gaze estimation with a constrained landmark-gaze model. European Conference on Computer Vision Workshop (ECCVW).
[14] Zhang, X., Sugano, Y., Fritz, M., and Bulling, A. (2016). It’s Written All Over Your Face: Full-Face Appearance-Based Gaze Estimation. IEEE Conference on Computer Vision and Pattern Recognition Workshops (CVPRW).
[15] Zhu, W. and Deng, H. (2017). Monocular free-head 3d gaze tracking with deep learning and geometry constraints. In The IEEE International Conference on Computer Vision (ICCV).
[16] Funes Mora, K. A., Monay, F., and Odobez, J.-M. (2014). Eyediap: A database for the devel- opment and evaluation of gaze estimation algorithms from rgb and rgb-d cameras. In Proceedings of the Symposium on Eye Tracking Research and Applications (ETRA), pages 255–258.
[17] Wood, E., Baltruaitis, T., Zhang, X., Sugano, Y., Robinson, P., and Bulling, A. (2015). Rendering of Eyes for Eye-Shape Registration and Gaze Estimation. IEEE International Conference on Computer Vision (ICCV), pages 3756–3764.
[18] Wood, E., Baltrušaitis, T., Morency, L.-P., Robinson, P., and Bulling, A. (2016b). Learning an appearance-based gaze estimator from one million synthesised images. In Proceedings of the Ninth Biennial ACM Symposium on Eye Tracking Research & Applications (ETRA), pages 131–138.
[19] Wang, K., Zhao, R., and Ji, Q. (2018). A hierarchical generative model for eye image synthesis and eye gaze estimation. In The IEEE Conference on Computer Vision and Pattern Recognition (CVPR)
[20] Shrivastava, A., Pfister, T., Tuzel, O., Susskind, J., Wang, W., and Webb, R. (2017). Learning from simulated and unsupervised images through adversarial training. In The IEEE Conference on Computer Vision and Pattern Recognition (CVPR), volume 3, page 6.
[21] Yu Yu, Jean-Marc Odobez (2020). Unsupervised Representation Learning for Gaze Estimation, CVPR 2020 accepted.
[22] Yu, Y., Liu, G., and Odobez, J.-M. (2019). Improving few-shot user-specific gaze adaptation via gaze redirection synthesis. In 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition.
[23] Funes Mora, K. A. and Odobez, J.-M. (2014). Geometric Generative Gaze Estimation (G3E) for Remote RGB-D Cameras. IEEE Conference on Computer Vision and Pattern Recognition (CVPR), pages 1773–1780.
[24] Liu, G., Yu, Y., Mora, K. A. F., and Odobez, J. (2019). A differential approach for gaze estimation. accepted in IEEE Transaction on Pattern Analysis and Machine Intelligence.
[25] Lindén, E., Sjöstrand, J., and Proutiere, A. (2019). Learning to personalize in appearance-based gaze tracking. ICCV Gaze Workshop.
[26] Xiong, Y., Kim, H. J., and Singh, V. (2019). Mixed effects neural networks (menets) with applications to gaze estimation. In The IEEE Conference on Computer Vision and Pattern Recognition (CVPR).
[27] Park, S., Mello, S. D., Molchanov, P., Iqbal, U., Hilliges, O., and Kautz, J. (2019). Few-shot adaptive gaze estimation. ICCV 2019.
[28] Sugano, Y., Matsushita, Y., and Sato, Y. (2014). Learning-by-synthesis for appearance-based 3d gaze estimation. In Computer Vision and Pattern Recognition (CVPR), 2014 IEEE Conference on, pages 1821–1828. IEEE.
[29] Funes-Mora, K. A. and Odobez, J.-M. (2012). Gaze Estimation from Multimodal Kinect Data. CVPR Workshop.
点击以下标题查看更多往期内容:
从近年CVPR看域自适应立体匹配
联合检测和跟踪的多目标跟踪算法解析
浅谈多目标跟踪中的相机运动
如何快速理解马尔科夫链蒙特卡洛法?
深度学习预训练模型可解释性概览
CVPR 2020 三篇有趣的论文解读
????
现在,在「知乎」也能找到我们了
进入知乎首页搜索「PaperWeekly」
点击「关注」订阅我们的专栏吧
关于PaperWeekly
PaperWeekly 是一个推荐、解读、讨论、报道人工智能前沿论文成果的学术平台。如果你研究或从事 AI 领域,欢迎在公众号后台点击「交流群」,小助手将把你带入 PaperWeekly 的交流群里。









 京公网安备 11010802041100号 | 京ICP备19059560号-4 | PHP1.CN 第一PHP社区 版权所有
京公网安备 11010802041100号 | 京ICP备19059560号-4 | PHP1.CN 第一PHP社区 版权所有