
1. 背景
如何为自动驾驶程序计算链路延迟?
一般来说在互联网开发上, 我们采用Distributed Systems Tracing(比如说Google Dapper), 来追踪一次服务调用的链路延迟.
但是对机器人程序来说, 是不存在"服务调用"的概念的. 链路上可能大部分程序都是time-based, 对数据都是buffer的形式来使用. 无法建立上下游的关联.
换种思路, 其实可以大问题分解成小问题: 通过各部分task/io的执行情况, 来证明某个链路的延迟.
2. 延迟计算
stop链路如下, 从决策一直到底盘:
Decider --> Planning --> Control --> Guardian --> Chassis
这里的程序逻辑如下:
(time-based, 100hz)表示是定时触发, 频率为100hz
Decider --> Planning(time-based, 10hz) --> Control(time-based, 100hz) --> Guardian(event-based) --> Chassis(time-based, 100hz)
如下假设是Decider到Planning发decision的一个io情况:
max_delay(测量) = Planning收到queue - Decider发出 = cpu调度响应时间 + 处理时间 = 10ms
根据上面的数据, 该io的deadline可以设置到10ms
关于deadline概念:
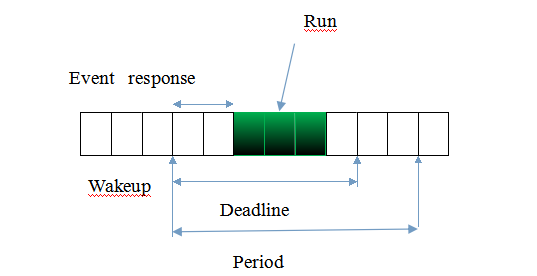
Planning的timer callback执行情况如下:
max_delay(测量) = Planning完成task- timer wakeup = cpu调度响应时间 + 处理时间 = 10ms
根据上面的数据, Planning的timer task的deadline可以设置10ms
(time-based任务的deadline的start为timer wakeup时间, event-based任务的deadline的start为event input的时间)
最终:
Decider到Planning消费decision的延迟 = Planning周期间隔(100ms) + Planning Timer Deadline(10ms) + io Deadline(10ms) = 120ms
其他地方同理, 一个个计算过来叠加, 就可以得到整个链路的预期最大延迟.
这样算过来的值会偏大, 但还是足够合理.
3. 其他
使用上述方法, 链路的延迟就简化为deadline一种可变量.
控制了deadline, 就可以保证所有链路延迟的确定.
-
不做实时性优化, deadline是不可确定/不可控的, 从而所有链路的预期最大延迟也都是不可确定.
-
即时是做了实时性优化, 也不能保证task/io的执行就不会超过deadline
- 所以要使用deadline监控, 以此反馈指导程序设计
- 最终要做到deadline在99.99%情况下都不会被突破


 京公网安备 11010802041100号
京公网安备 11010802041100号