什么是可见性?为什么会出现”不可见“?Java并发-theme:channing-cyan什么是可见性?为什么会出现”不可见“我们已经知道counter.increment
theme: channing-cyan
什么是可见性?为什么会出现”不可见“
我们已经知道
counter.increment();
编译成字节码为
getfield #2
iconst_1
iadd
putfield #2
上一篇已经说过,这里的字节码的执行过程是在工作内存中,但是getField和putField这二条指令其实是跟主内存有交互的,这里还是以Counter类的increment方法为例。
- getField指令会从主存中读取count的值,但是并不是每次都从主存中读,因为CPU高速cache的存在,我们count值有可能会从cache中读,导致读的并不是最新的
- putField指令会将count新的值写入主内存,但是也不是立即生效,别的CPU的高速cache中的count不会立即更新,CPU会使用缓存一致性协议来做同步,这个对我们是透明的。
正是因为CPU高速cache的存在,在多核环境中会有可见性的问题。这里额外提一句 ,之所以有高速cache存在,是为提高运行效率,现代CPU的速度比我们的内存快很多,如果每次都锁总线写主存,会导致执行速度下降很多,这是不可以接受的,木桶理论我们都能理解。这里我也画了一张图,来帮助大家理解。
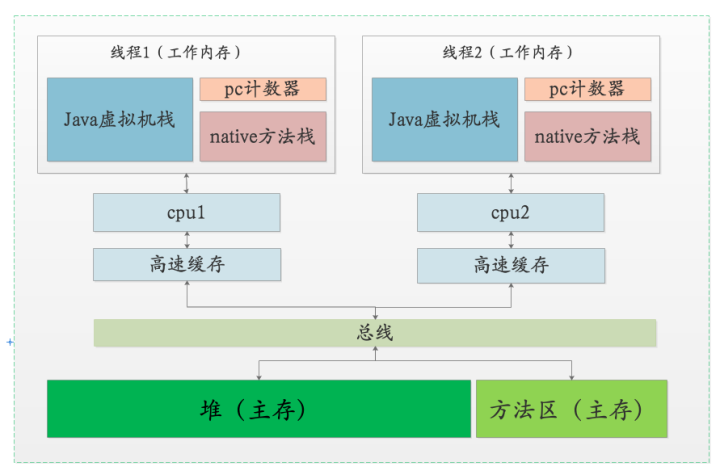
那有没有办法解决可见性带来的问题呢?当然是有的,对于Java,我们可以使用volatile关键字。
volatile
volatile修饰的变量有下面的特性
- 在写volatile的时候,有monitor release的语义,会刷新各个cpu中该变量的cache,存入最新的值
- 在读volatile的时候,有monitor acquire的语义,会使当前cpu的cache中该变量的cache失效,从主存中读取最新的值
- volatile拥有禁止指令重排序的语义
其中monitor可以理解为锁,moniter release就是释放锁,monitor acquire就是获取锁,这样就是volatile变量的读写都是直接对主存操作的,相当于牺牲一部分性能来换取可见性,这一部分牺牲的性能一般是可以忽略不计的,只需要知道有这么回事就行。
volatile实现原理
给count加上volatile修饰符后,查看编译后的字节码后会发现,字节码层面唯一的变化是给count添加了ACC_VOLATILE标识flag,在运行时会根据这个flag会自动插入内存屏障,保证volatile可见性语义,内存屏障一共有四种,分别是:
- LoadLoad
- LoadStore
- StoreStore
- StoreLoad
这里有个文档,比较权威详细的说明了内存屏障的知识,这一块知识大家可以自己继续深入。这里给出文档中的一个实例,比较形象的说明了内存屏障是怎么插入的。

编辑
添加图片注释,不超过 140 字(可选)
再回到上面的例子,我们给count添加上volatile修饰符之后,是不是就能在多线程中得到正确的累加结果呢?我们试验一下,简单起见,我们只开2个线程,每个线程分配一半的计算量。
// Counter.java
private volatile int count;
// main 方法
Counter counter = new Counter();
int loopCount = 100000000;
int halfCount = loopCount / 2;
Thread thread1 = new Thread(() -> {
for (int i = 0; i {
for (int i = halfCount; i
结果显然还是不对的,而且程序运行的时间长了好几倍了。这是因为volatile只保证了可见性,却没有原子性语义,比如下面这种情况

在T1-T6时间内,初始count=0,经过二次++操作,最后count的值还是1,在我们上面的例子中,5千万次的循环会出现大量类似的错误覆盖写入。根据我们上面分析的volatile的语义,在T5时刻,Thread1对count的修改对Thread2是可见的,这里的可见指的是,如果此时调用getfield指令,拿到的值会是Thread1修改的最新的1,但是遗憾的是,Thread2对此一无所知,只是按着自己的步骤将错误的1写入了count中。
那我们不妨设想下,如果在putfield之前,检查下当前栈中存储的count是不是最新的,如果不是最新的重新读取count,然后重试,如果是最新的,直接写入更新值,似乎这样就能解决我们上面出现的错误写入的问题。看起来似乎是一个不错的想法,但是一定要注意,整个检查过程要保证原子性,否则仍然会有并发问题。事实上JDK中Unsafe包里面的CAS方法就是这个思路,不断循环尝试,这个过程就是自旋,它的底层实现依赖cmpxchgl 和 cmpxchgq这二个汇编指令,不同平台的cpu有不同的实现,但是代码大同小异,我在这里以opekjdk8为例扒一扒CAS的源码,源码比较多我只会贴出关键代码块。
// Unsafe.class中的三个CAS方法,都是native的
public final native boolean compareAndSwapObject(Object var1, long var2, Object var4, Object var5);
public final native boolean compareAndSwapInt(Object var1, long var2, int var4, int var5);
public final native boolean compareAndSwapLong(Object var1, long var2, long var4, long var6);
它对应的native实现在hotspot/src/share/vm/prims/unsafe.cpp
UNSAFE_ENTRY(jboolean, Unsafe_CompareAndSwapInt(JNIEnv *env, jobject unsafe, jobject obj, jlong offset, jint e, jint x))
UnsafeWrapper("Unsafe_CompareAndSwapInt");
oop p = JNIHandles::resolve(obj);
jint* addr = (jint *) index_oop_from_field_offset_long(p, offset);
return (jint)(Atomic::cmpxchg(x, addr, e)) == e;
UNSAFE_END
篇幅关系,这里只贴上compareAndSwapInt的实现,可以看到又调用了Atomic::cmpxchg方法,继续跟进去
unsigned Atomic::cmpxchg(unsigned int exchange_value,
volatile unsigned int* dest, unsigned int compare_value) {
assert(sizeof(unsigned int) == sizeof(jint), "more work to do");
return (unsigned int)Atomic::cmpxchg((jint)exchange_value, (volatile jint*)dest,
(jint)compare_value);
}
jbyte Atomic::cmpxchg(jbyte exchange_value, volatile jbyte* dest, jbyte compare_value) {
assert(sizeof(jbyte) == 1, "assumption.");
uintptr_t dest_addr = (uintptr_t)dest;
uintptr_t offset = dest_addr % sizeof(jint);
volatile jint* dest_int = (volatile jint*)(dest_addr - offset);
jint cur = *dest_int;
jbyte* cur_as_bytes = (jbyte*)(&cur);
jint new_val = cur;
jbyte* new_val_as_bytes = (jbyte*)(&new_val);
new_val_as_bytes[offset] = exchange_value;
while (cur_as_bytes[offset] == compare_value) {
jint res = cmpxchg(new_val, dest_int, cur);
if (res == cur) break;
cur = res;
new_val = cur;
new_val_as_bytes[offset] = exchange_value;
}
return cur_as_bytes[offset];
}
我们跟踪到了调用了cmpxchg这个方法,这个方法不是在atomic.cpp中定义的,查看atomic.hpp,看到了cmpxchg对应的内联函数的定义
inline static jint cmpxchg (jint exchange_value, volatile jint* dest, jint compare_value);
// See comment above about using jlong atomics on 32-bit platforms
inline static jlong cmpxchg (jlong exchange_value, volatile jlong* dest, jlong compare_value);
这里我们以solaris_x86平台为例,cmpxchg对应的内涵函数定义在hotspot/src/os_cpu/solaris_x86/vm/atomic_solaris_x86.inline.hpp
#define LOCK_IF_MP(mp) "cmp $0, " #mp "; je 1f; lock; 1: "
inline jint _Atomic_cmpxchg(jint exchange_value, volatile jint* dest, jint compare_value, int mp) {
__asm__ volatile (LOCK_IF_MP(%4) "cmpxchgl %1,(%3)"
: "=a" (exchange_value)
: "r" (exchange_value), "a" (compare_value), "r" (dest), "r" (mp)
: "cc", "memory");
return exchange_value;
}
这个是内嵌汇编代码,实话说,汇编这一块的知识我也还给老师了。根据LOCK_IF_MP这个宏定义判断是不是多核心,如果是多核心需要加锁,但是这个锁是cpu总线锁,它的代价比我们应用层中用的Lock代价小得多。同时我们看到cmpxchgl这个关键的指令。追到这一层,我想对于应用开发工程师已经足够了。了解了底层实现,我们来现学现卖实战一波。
使用CAS改造我们的加法器Counter,使其是线程安全的
要使用CAS,肯定要使用Unsafe类,我们还是通过反射来获取Unsafe对象,先看UnsafeUtil类的实现
// UnsafeUtil.java
public static Unsafe getUnsafeObject() {
Class clazz = AtomicInteger.class;
try {
Field uFiled = clazz.getDeclaredField("unsafe");
uFiled.setAccessible(true);
return (Unsafe) uFiled.get(null);
} catch (Exception e) {
e.printStackTrace();
}
return null;
}
public static long getVariableOffset(Object target, String variableName) {
Object unsafeObject = getUnsafeObject();
if (unsafeObject != null) {
try {
Method method = unsafeObject.getClass().getDeclaredMethod("objectFieldOffset", Field.class);
method.setAccessible(true);
Field targetFiled = target.getClass().getDeclaredField(variableName);
return (long) method.invoke(unsafeObject, targetFiled);
} catch (Exception e) {
e.printStackTrace();
}
}
return -1;
}
再来看Counter类的实现
public class Counter {
private volatile int count;
private Unsafe mUnsafe;
private long countOffset;
public Counter() {
mUnsafe = UnsafeUtil.getUnsafeObject();
countOffset = UnsafeUtil.getVariableOffset(this, "count");
}
public void increment() {
int cur = getCount();
while (!mUnsafe.compareAndSwapInt(this, countOffset, cur, cur+1)) {
cur = getCount();
}
}
public int getCount() {
return this.count;
}
}
再次开启二个线程,执行我们的累加程序
// 输出结果
count:100000000
take time:5781ms
可以看到我们得到正确的累加结果,但是运行时长更长了,但是还好,时间复杂度还是在一个数量级上的。这里要注意一点的是,上述示例代码中,我给count变量增加了volatile关键字,其实就算不加volatile关键字,在这里CAS也是能够正确工作的,但是效率会低一点,我测试下来差不多性能会低5%左右,大家可以思考下为什么不加volatile效率会低?
volatile关键字还有一个禁止指令重排序的语义,一个经典的应用就是DCL单例模式。
到这里,关于可见性我们已经讨论的差不多了,下一篇我们来讨论”原子性“
Java学习视频
Java基础:
Java300集,Java必备优质视频_手把手图解学习Java,让学习成为一种享受
Java项目:
【Java游戏项目】1小时教你用Java语言做经典扫雷游戏_手把手教你开发游戏
【Java毕业设计】OA办公系统项目实战_OA员工管理系统项目_java开发








 京公网安备 11010802041100号
京公网安备 11010802041100号