作者:你的美我chase | 来源:互联网 | 2023-08-25 17:07
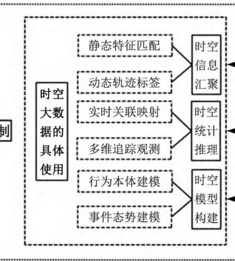
时空大数据的使用
通过这篇论文,对于时空大数据的应用,无疑是从三个方面展开的:聚合、统计推理
大体的使用框架如上图所示,那么具体该怎么处理数据呢
时空轨迹数据的预处理 时空轨迹数据预处理包括:道路匹配和轨迹压缩两个基本阶段
道路匹配修正 定位技术精度的偏差和自身设备的可靠性所对可视化在电子地图上 时,移动对象位置会出现偏离路网道路的情况 的影响 轨迹压缩 时空轨迹模式 时空轨迹模式的类型定义 按照序列中元素类型的不同,可以分为时空轨迹点序列和时空轨迹边序列两种
时空轨迹点序列 时空轨迹边序列 时空轨迹模式的类型 对于时空轨迹数据,我们要选择有价值的模式进行进一步挖掘,常见的模式有:频繁模式、伴随模式、聚集模式、异常模式和大数据模式
频繁模式 时空轨迹频繁模式是指从时空轨迹集中发现的频繁重复的序列,在进行轨迹频繁模式挖掘之前,必须对时空轨迹数据进行预处理,采用路网匹配和轨迹压缩技术处理的同时还要提取出兴趣点序列 ,以便找出频繁兴趣点子序列
挖掘由兴趣区域(Region of interest,ROI)构成的频繁序列 基于时间周期的 最频繁路 径 (Time period-based most frequent path,TPMFP)查询算法 时空轨迹的细粒度序列模式挖掘 伴随模式 时空轨迹伴随模式是指从时空轨迹数据集中发现具有相同或者相似路线的移动对象群体。通过分析移动对象群体的行为特征和规律,可以帮助实现在时空环境中的群体跟踪、热点事件发现等
定义::给定m,k∈N,r为大于零的常数。给定时空轨迹集合,且每条轨迹由τ条线段构成。伴随模式是指在时间区间I=ti,tj中,至少包含m个移动对象,在时间区间I的每个时刻中所有位置点都集中在半径为r的圆形区域内
常用算法
群体模式算法 伴随模式算法 相干移动簇算法(Coherent moving cluster,CMC) 采用轨迹简化技术的伴随模式发现(Convoy discovery using trajectory simplification,CuTS)算法 交错式进化伴随算法ID-1/2 蜂群模式算法 聚集模式 首先了解三个概念
快照簇:为某一时刻移动对象形成的簇,并且簇内所有移动对象密度相连 群体:由一定数目的快照簇形成的集合,并且任意相邻时刻的快照簇间的距离都小于等于给定的距离阈值 参与者:在群体中出现至少kp次的移动对象 聚集模式 ::如果群体中的每个快照簇含有至少mp个参与者,那么这个群体就属于聚集模式
常用算法:
基于关联规则剪枝的聚集模式挖掘算法
基于关联规则剪枝的聚集模式挖掘算法 基于FP-Growth的有效组图结构挖掘算法 基于轨迹的组模式挖掘 (Apriori trajectory-based group pattern mining,ATGP)算法 遍历式VG-Growth(Traversal VG-Growth,TVG-Growth)算法 面向移动对象的深度优先搜索算法 基于密度聚类的聚集模式挖掘算法
基于密度的空间聚类 (Density-based spatial clustering of applications with noise,DBSCAN)算法 异常模式 设有时空轨迹数据集D={TR1,…,TRn},TRi=p1p2p3…pj…pleni(1≤i≤n)是一条轨迹,其中,pj为d维度的点,leni为轨迹TRi的长度。轨迹段是指一条线段pipj(ii和pj是来自TRi中任意的点
离群轨迹段 :如果一个轨迹段周围没有足够数量的其他轨迹段与其靠近,则它称为离群轨迹段异常模式 :轨迹的异常模式是指O={O1,…,Om},其中Oi为离群轨迹段
常用算法:
静态数据集的轨迹异常检测 基于R-Tree的异常轨迹检测算法 实时轨迹异常检测算法 轨迹数据流的异常检测 大数据模式 对于时空轨迹大数据,时空轨迹模式挖掘除了需要经典的数据挖掘技术(关联分析、分类、聚类、异常检测等)以外,通过还有特殊的技术
云计算技术 轨迹数据压缩和消减技术 时空轨迹数据可视化技术 欢迎交流学习 个人博客
掘金主页








 京公网安备 11010802041100号
京公网安备 11010802041100号