RecordReader接口
RecordReader有5个方法
RecordReader通过这几个方法的配合运用,将数据转化为key-value形式的数据,输送给Mapper Task。
InputFormat在Hive中的使用
调节Map任务数需要一套算法,该算法也和InputFormat有密切的关系,具体如下:
优化的核心就是
MapReduce的Mapper
Mapper类负责MapReduce计算引擎Map阶段业务逻辑的处理。
Mapper类
Mapper的核心Map方法是MapReduce提供给用户编写业务的主要接口之一,它的输入是一个键-值对的形式,输出也是一个键-值形式
cleanup()、map()、run()和setup()方法之间的关系
setup()方法主要用于初始化一些信息,以供map()中使用,如初始化数据库连接。
cleanup方法主要是清理释放setup()、map()方法中用到的资源,例如,释放数据库连接、关闭打开的文件句柄等资源。
Hive中与Mapper相关的配置
Hive可以通过一些配置来影响Mapper的运行
MapReduce的Reducer
Reducer类是MapReduce处理Reduce阶段业务逻辑的地方
Reducer类
Reducer的核心Reduce方法是MapReduce提供给用户编写业务的另一个主要接口,它的输入是一个键-数组的形式,和Mapper的输入不太一样。
Hive中与Reducer相关的配置
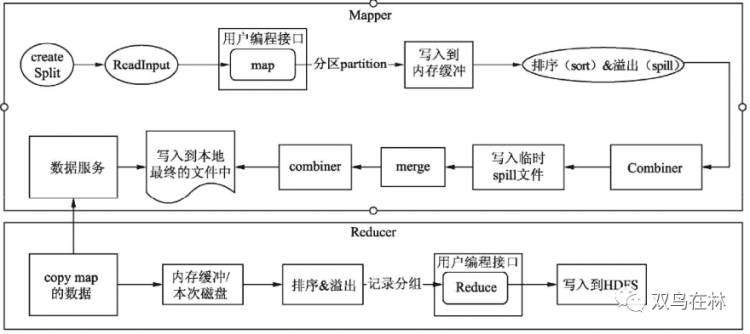
MapReduce的Shuffle
在Mapper的Map方法中,context.write()方法会将数据计算所在分区后写入到内存缓冲区,缓冲区的大小为mapreduce.task.io.sort.mb=100MB。当缓冲区缓存的数据达到一定的阀值mapreduce.map.sort.spill.percent=0.8, 即总缓冲区的80%时,将会启动新的线程将数据写入到HDFS临时目录中。这样设计的目的在于避免单行数据频繁写,以减轻磁盘的负载。这与关系型数据库提倡批量提交(commit)有相同的作用。在写入到HDFS的过程中,为了下游Reducer任务顺序快速拉取数据,会将数据进行排序后再写入临时文件中,当整个Map执行结束后会将临时文件归并成一个文件
为什么不选用Mapper任务结束后直接推送到Reducer节点,这样可以节省写入到磁盘的操作,效率更高?因为采用缓存到HDFS,让Reducer主动来拉,当一个Reducer任务因为一些其他原因导致异常结束时,再启动一个新的Reducer依然能够读取到正确的数据。
MapReduce的Map端聚合
MapReduce的Map端聚合通常指代实现Combiner类。Combiner也是处理数据聚合,但不同于Reduce是聚合集群的全局数据。
Combiner类
Combiner是MapReduce计算引擎提供的另外一个可以供用户编程的接口
使用Combiner的初衷是减少Shuffle过程的数据量,减轻系统的磁盘和网络的压力。
Map端的聚合与Hive配置
mapred.reduce.tasks:设置Reducer的数量,默认值是-1,代表有系统根据需要自行决定Reducer的数量。
hive.exec.reducers.bytes.per.reducer:设置每个Reducer所能处理的数据量,在Hive 0.14版本以前默认是1000000000(1GB),Hive 0.14及之后的版本默认是256MB。输入到Reduce的数据量有1GB,那么将会拆分成4个Reducer任务。
hive.exec.reducers.max:设置一个作业运行的最大Reduce个数,默认值是999。
hive.multigroupby.singlereducer:表示如果一个SQL语句中有多个分组聚合操作,且分组是使用相同的字段,那么这些分组聚合操作可以用一个作业的Reduce完成,而不是分解成多个作业、多个Reduce完成。这可以减少作业重复读取和Shuffle的操作。
hive.mapred.reduce.tasks.speculative.execution:表示是否开启Reduce任务的推测执行。即系统在一个Reduce任务中执行进度远低于其他任务的执行进度,会尝试在另外的机器上启动一个相同的Reduce任务。
hive.optimize.reducededuplication:表示当数据需要按相同的键再次聚合时,则开启这个配置,可以减少重复的聚合操作。
hive.vectorized.execution.reduce.enabled:表示是否启用Reduce任务的向量化执行模式,默认是true。MapReduce计算引擎并不支持对Reduce阶段的向量化处理。
hive.vectorized.execution.reduce.groupby.enabled:表示是否移动Reduce 任务分组聚合查询的向量化模式,默认值为true。MapReduce计算引擎并不支持对Reduce阶段的向量化处理。
Mapper通过调用run()方法,在通过run()调用setup()方法,紧接着通过一个while循环调用map方法,将一行行数据循环发送给map()方法进行处理,跳出循环后再调用cleanup()方法,整个run()方法结束。
增大Map个数,需要减少mapred.min.split.size的值,同时增大mapred.map.tasks的值。
减少Map个数,需要增大mapred.min.split.size的值,减少mapred.map.tasks的值;
getCurrentKey()方法,用于获取当前的key。
getCurrentValue()方法,用于获取当前的value。
nextKeyValue()方法,读取下一个key-value对。
getProgress()方法,读取当前逻辑分片的进度。
hive.map.aggr:默认值为true,表示开启Map端的聚合。开启和不开启Map端聚合的差别可以在执行计划中看到,详见下面两个案例执行计划的精简结构。
Hive在默认开启hive.map.aggr的同时,引入了两个参数, hive.map.aggr.hash.min.reduction和hive.groupby.mapaggr.checkinterval,用于控制何时启用聚合
hive.map.aggr.hash.min.reduction:是一个阈值,默认值是0.5。
hive.groupby.mapaggr.checkinterval:默认值是100000。Hive在启用Combiner时会尝试取这个配置对应的数据量进行聚合,将聚合后的数据除以聚合前的数据,如果小于hive.map.aggr.hash.min.reduction会自动关闭。
hive.map.aggr.hash.percentmemory:默认值是0.5。该值表示在进行Mapper端的聚合运行占用的最大内存。例如,分配给该节点的最大堆(xmx)为1024MB,那么聚合所能使用的最大Hash表内存是512MB,如果资源较为宽裕,可以适当调节这个参数。
hive.map.aggr.hash.force.flush.memory.threshold:默认值是0.9。该值表示当在聚合时,所占用的Hash表内存超过0.9,将触发Hash表刷写磁盘的操作。例如Hash表内存是512MB,当Hash表的数据内存超过461MB时将触发Hash表写入到磁盘的操作。
hive.vectorized.execution.enabled:表示是否开启向量模式,默认值为false。在run()方法中,我们看到map()方法是逐行处理数据,这样的操作容易产生更多的CPU指令和CPU上下文切换,导致系统的处理性能不高。
目前MapReduce计算引擎只支持Map端的向量化执行模式, Tez和Spark计算引擎可以支持Map和Reduce端的向量化执行模式。
hive.ignore.mapjoin.Hint:是否忽略SQL中MapJoin的Hint关键,在Hive 0.11版本之后默认值为true,即开启忽略Hint的关键字。如果要使用MapJoin的Hint关键字,一定要在使用前开启支持Hint语法,否则达不到预期的效果。
hive.auto.convert.join:是否开启MapJoin自动优化,hive 0.11版本以前默认关闭,0.11及以后的版本默认开启。
hive.smalltable.filesize or hive.mapjoin.smalltable.filesize:默认值2500000(25MB)如果大小表在进行表连接时的小表数据量小于这个默认值,则自动开启MapJoin优化。在Hive 0.8.1以前使用hive.smalltable.filesize, 之后的版本使用hive.mapjoin.smalltable.filesize参数。Hive 0.11版本及以后的版本,可以使用hive.auto.convert.join.noconditionaltask.size和hive.auto.convert.join.noconditionaltask两个配置参数。
hive.auto.convert.join.noconditionaltask.size的默认值为10000000(10MB)。
hive.auto.convert.join.noconditionaltask的默认值是true,表示Hive会把输入文件的大小小于
hive.auto.convert.join.noconditionaltask.size指定值的普通表连接操作自动转化为MapJoin的形式。
hive.auto.convert.join.use.nonstaged:是否省略小表加载的作业,默认值为false。对于一些MapJoin的连接操作,如果小表没有必要做数据过滤或者列投影操作,则会直接省略小表加载时额外需要新增的MapReduce作业(一般一个MapReduc作业对应一个Stage)。
hive.map.aggr:是否开启Map任务的聚合,默认值是true。
hive.map.aggr.hash.percentmemory:默认值是0.5,表示开启Map任务的聚合,聚合所用的哈希表,所能占用到整个Map被分配的内存50%。例如,Map任务被分配2GB内存,那么哈希表最多只能用1GB。
hive.mapjoin.optimized.hashtable:默认值是true,Hive 0.14新增, 表示使用一种内存优化的哈希表去做MapJoin。由于该类型的哈希表无法被序列化到磁盘,因此该配置只能用于Tez或者Spark。
hive.mapjoin.optimized.hashtable.wbsize:默认值是10485760(10MB),优化的哈希表使用的是一种链块的内存缓存,该值表示一个块的内存缓存大小。这种结构对于数据相对较大的表能够加快数据加载,但是对于数据量较小的表,将会分配多余的内存。
hive.map.groupby.sorted:在Hive 2.0以前的默认值是False,2.0及2.0以后的版本默认值为true。对于分桶或者排序表,如果分组聚合的键(列)和分桶或者排序的列一致,将会使用BucketizedHiveInputFormat。
hive.vectorized.execution.mapjoin.native.enabled:是否使用原生的向量化执行模式执行MapJoin,它会比普通MapJoin速度快。默认值为False。
hive.vectorized.execution.mapjoin.minmax.enabled:默认值为False,是否使用vector map join哈希表,用于整型连接的最大值和最小值过滤。
在默认情况下Map的个数defaultNum=目标文件或数据的总大小totalSize/hdfs集群文件块的大小blockSize。
当用户指定mapred.map.tasks,即为用户期望的Map大小,用expNum表示,这个期望值计算引擎不会立即采纳,它会获取mapred.map.tasks与defaultNum的较大值,用expMaxNum表示,作为待定选项。
获取文件分片的大小和分片个数,分片大小为参数mapred.min.split.size和blockSize间的较大值,用splitMaxSize表示,将目标文件或数据的总大小除以splitMaxSize即为真实的分片个数,用realSplitNum表示。
获取realSplitNum与expMaxNum较小值则为实际的Map个数。












 京公网安备 11010802041100号
京公网安备 11010802041100号