作者:怎么找个名字这么费劲 | 来源:互联网 | 2023-06-28 19:52
本文由编程笔记#小编为大家整理,主要介绍了清华深度学习框架Jittor开源,创新元算子和统一计算图,推理速度可提升10%-50%相关的知识,希望对你有一定的参考价值。
本文由编程笔记#小编为大家整理,主要介绍了清华深度学习框架 Jittor 开源,创新元算子和统一计算图,推理速度可提升 10%-50%相关的知识,希望对你有一定的参考价值。
近日,清华大学计算机系图形实验室宣布开源全新的深度学习框架:计图(英文名:Jittor),这也是
我国首个高校自研的开源深度学习框架
。
根据官网介绍,这是一个完全基于动态编译(Just-in-time)、内部使用创新的元算子和统一计算图的深度学习框架。
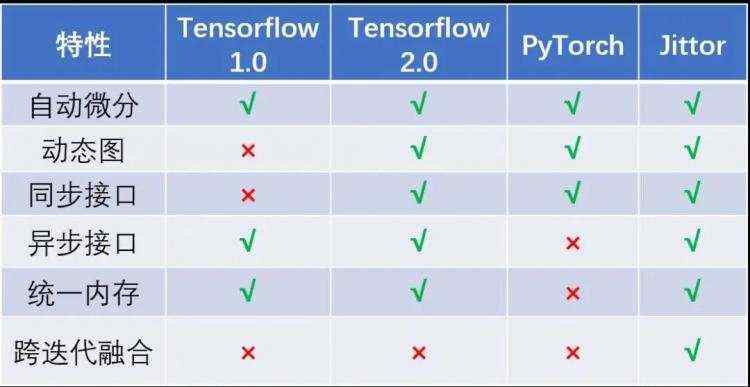
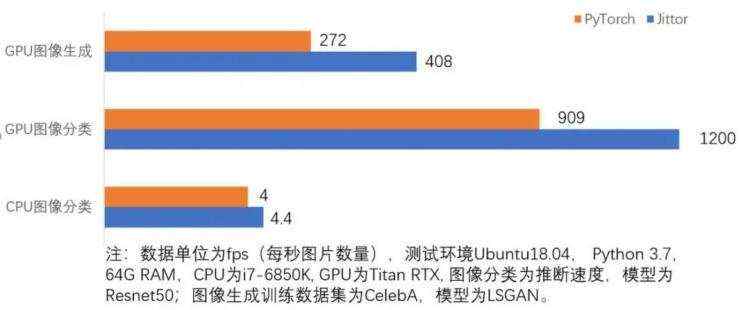
根据官方给出的特性对比来看,Jittor 与国际主流平台相比,具有多项先进特性。与同类型框架相比,Jittor 在收敛精度一致情况下,推理速度取得了 10%-50% 的性能提升。
1. 易用且可定制:只需要数行代码,就可定义新的算子和模型。
2. 实现与优化分离:可以通过前端接口专注于实现,而实现自动被后端优化。
3. 所有都是即时的:Jittor 的所有代码都是即时编译并且运行的,包括 Jittor 本身。用户可以随时对 Jittor 的所有代码进行修改,并且动态运行。
而这些理念以及最终实现的能力,要归功于 Jittor 的两大核心创新点:
元算子和统一计算图。
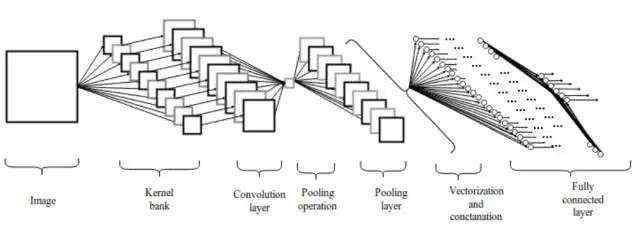
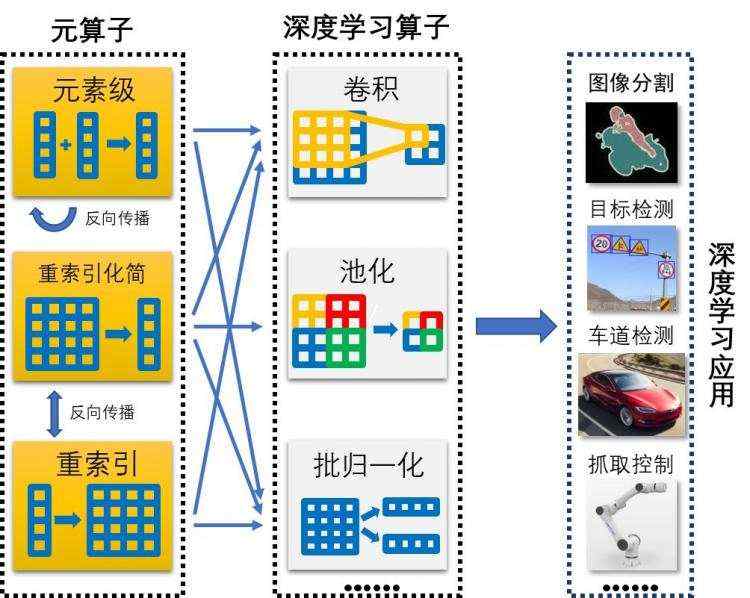
了解深度学习的朋友可能知道,深度学习采用的卷积神经网络是由算子(Operator)组成的一个计算网络。由于架构设计和不断扩充等原因,当前深度学习框架有多达 2000 种算子,系统复杂,优化和移植困难。
Jittor 则
将算子运算进一步分解,形成了更加底层的三类 20 余种元算子闭包
,目前神经网络常用算子均可以使用元算子的组合进行表达。
另一方面,为了面向未来深度学习框架的发展趋势,Jittor 利用元算子组合表达的优势,提出统一计算图进行优化,并从底层开始设计了一个全新的动态编译架构。
该架构支持多种编译器,
实现了所有代码的即时编译和动态运行,确保了实现和优化分离
,大幅提升了应用开发灵活性、可拓展性和可移植性。
其次,在算子的设置上,团队将元算子的反向传播进行了闭包,即元算子的反向传播也是元算子。这样避免了重复开发。此外,还支持计算任意高阶导数。
根据官方给出的 Jittor 与其他平台的计算图特性对比来看,Jittor 与国际主流平台相比,具有多项先进特性。
与同类型框架相比,Jittor 在收敛精度一致情况下,推理速度取得了 10%-50% 的性能提升。
在编程语言方面,Jittor 前端语言选择了 Python。前端使用了模块化的设计,类似于 PyTorch,Keras,用户可以编写元算子计算的 Python 代码,然后 Jittor 将其动态编译为 C++,从而提升性能。
后端则直接使用高性能语言编写,如 CUDA,C++。
盘点国内的深度学习框架
之所以清华开源的 Jittor 引起大家广泛的讨论,很重要的一原因是这是首个来自中国高校科研机构的开源深度学习框架,之前,来自高校的开源深度学习框架只有加拿大蒙特利尔大学的 Theano 和 UC Berkeley 的 Caffe。
中国作为人工智能产业发展和应用的最大市场,我们理应在人工智能生态的全产业链上占有一席之地。下面我们来盘点一下国内研发的规模较大的深度学习框架,如有遗漏,也欢迎大家在留言区进行补充:
根据 Jittor 团队核心开发成员表示,Jittor 的基本功能于 2019 年底完成,随后经过内部测试,于近日正式对外发布并开源。
「计图」的意思是图谋、谋取。这个词儿最早出现在唐朝崔致远《答徐州时溥书》:“今有城中将校,潜来计图,请少振兵戎,即便期开泰者。”
虽然官方并未对中文名字作出解释,但据研发团队介绍称,深度学习发展迅猛,TensorFlow、PyTorch 这些老牌主流框架,也会在新模型,新算法,新硬件上表现不佳,所以需要新的框架,在易于扩展同时保持高效。
https://cg.cs.tsinghua.edu.cn/jittor/
https://github.com/Jittor/jittor
NCNN 是腾讯优图实验室首个开源项目,于 2017 年 7 月正式开源。
这是一个为手机端极致优化的高性能神经网络前向计算框架。NCNN 从设计之初深刻考虑手机端的部署和使用。无第三方依赖,跨平台,手机端 CPU 的速度快于目前所有已知的开源框架。基于 NCNN,开发者能够将深度学习算法轻松移植到手机端高效执行,开发出人工智能 APP。
NCNN 目前已在腾讯多款应用中使用,如 QQ,Qzone,微信,天天P图等。
https://github.com/Tencent/ncnn
PaddlePaddle 作为国内首个深度学习开源平台,2013 年开始百度就投入精力进行研发,
2016 年 8 月底正式开源。
PaddlePaddle 是一个全面的开源开放平台,包含核心的开发、训练、部署框架,以及非常丰富的模型库。基于这个模型库,PaddlePaddle 可以覆盖很多经典的应用场景,开发者可以进行二次开发,或者直接使用。在这个模型库的基础之上,PaddlePaddle 还提供了端到端的开发套件,聚焦在人工智能领域的常见任务和场景。
在端到端开发套件之上是一整套的工具组件,这些工具组件可以帮助开发者解决更多人工智能应用当中的问题。同时,PaddlePaddle 还提供很多部署的工具链,方便开发者部署自己的应用。
https://github.com/PaddlePaddle
X-Deep Learning(下文简称 XDL)由阿里巴巴旗下大数据营销平台阿里妈妈基于自身广告业务自主研发,已经大规模部署应用在核心生产场景。
XDL 采用了「桥接」的架构设计理念。这种架构使得 XDL 跟业界的开源社区无缝对接。例如,用户可以非常方便地在 XDL 框架上应用基于 TensorFlow 或者 PyTorch 编写的最先进开源深度学习算法。此外,对于已经在使用其他开源框架的企业或者个人用户,也可以在原有系统基础上轻松进行扩展,享受 XDL 带来的高维稀疏数据场景下极致的分布式能力。
Github 地址:https://github.com/alibaba/x-deeplearning
深度学习技术正广泛应用于人工智能的各个领域,如计算机视觉、机器翻译、自然语言处理、智能机器人等,取得了前所未有的突破。
当前,一方面,随着深度学习新技术的出现、任务复杂度的提高,易于扩展同时保持高效的架构成为发展趋势;另一方面,
随着我国人工智能产业发展迅速,我们需要构建一个属于自己的开源深度学习生态,这也是一个绝好的机会。
尽管以 TensorFlow、PyTorch 等为代表的开源框架已经取得了一定程度上的成功,而我国在这一领域发展起步较晚,目前存在着一定的劣势。但单就开源框架来看,不论是底层的核心技术能力还是针对具体应用场景的解决能力,都还有着很大的提升空间。
希望国内的科技企业和研究机构可以奋起直追,不再在核心技术上被别人「卡脖子」。







 京公网安备 11010802041100号
京公网安备 11010802041100号