首页
技术博客
PHP教程
数据库技术
前端开发
HTML5
Nginx
php论坛
新用户注册
|
会员登录
PHP教程
技术博客
编程问答
PNG素材
编程语言
前端技术
Android
PHP教程
HTML5教程
数据库
Linux技术
Nginx技术
PHP安全
WebSerer
职场攻略
JavaScript
开放平台
业界资讯
大话程序猿
登录
极速注册
取消
热门标签 | HotTags
tensorflow
人脸识别
算法
人工智能
svm
深度学习
机器人
自动驾驶
自然语言处理
ocr
数据挖掘
图像识别
机器学习
nlp
神经网络
深度
pytorch
当前位置:
开发笔记
>
人工智能
> 正文
【深度学习】常见的梯度下降的方法
作者:一根吃兔子的萝卜 | 来源:互联网 | 2023-05-25 09:32
批量梯度下降(Batch Gradient Descent,BGD) 这个方法是当所有的数据都经过了计算之后再整体除以它,即把所有样本的误差做
批量梯度下降(Batch Gradient Descent,BGD)
这个方法是当所有的数据都经过了计算之后再整体除以它,即把所有样本的误差做平均。这里我想提醒你,在实际的开发中,往往有百万甚至千万数量级的样本,那这个更新的量就很恐怖了。所以就需要另一个办法,随机梯度下降法。
随机梯度下降(Stochastic Gradient Descent,SGD)
随机梯度下降法的特点是,每计算一个样本之后就要更新一次参数,这样参数更新的频率
就变高了。
想想看,每训练一条数据就更新一条参数,会有什么好处呢?对,有的时候,我们只需要
训练集中的一部分数据,就可以实现接近于使用全部数据训练的效果,训练速度也大大提
升。
然而,鱼和熊掌不可兼得,SGD 虽然快,也会存在一些问题。就比如,训练数据中肯定会
存在一些错误样本或者噪声数据,那么在一次用到该数据的迭代中,优化的方向肯定不是
朝着最理想的方向前进的,也就会导致训练效果(比如准确率)的下降。最极端的情况
下,就会导致模型无法得到全局最优,而是陷入到局部最优。
小批量梯度下降(Mini-Batch Gradient Descent, MBGD)
Mini-batch 的方法是目前主流使用最多的一种方式,它每次使用一个固定数量的数据进行
优化。
这个固定数量,我们称它为 batch size。batch size 较为常见的数量一般是 2 的 n 次方,
比如 32、128、512 等,越小的 batch size 对应的更新速度就越快,反之则越慢,但是更
新速度慢就不容易陷入局部最优。
基于随机梯度下降法,人们又提出了包括 momentum、nesterov momentum 等方法,这部分知识同学们有兴趣点击这里可以自行查阅。
梯度下降的min-batch越大越好么?
batch_size越大显存占用会越多,可能会造成内存溢出问题,此外由于一次读取太多的
样本,可能会造成迭代速度慢的问题。
batch_size较大容易使模型收敛在局部最优点
此外过大的batch_size的可能会导致模型泛化能力较差的问题
batch size太小的话,那么每个batch之间的差异就会很大,迭代的时候梯度震荡就会严重,不利
于收敛。
batch size越大,那么batch之间的差异越小,梯度震荡小,利于模型收敛。
但是凡事有个限度,如果batch size太大了,训练过程就会一直沿着一个方向走,从而陷入局部最
优。
深度学习
写下你的评论吧 !
吐个槽吧,看都看了
会员登录
|
用户注册
推荐阅读
深度学习
龙蜥社区开发者访谈:技术生涯的三次蜕变 | 第3期
龙蜥社区的开发者们通过自己的实践和经验,推动着开源技术的发展。本期「龙蜥开发者说」聚焦于一位资深开发者的三次技术转型,分享他在龙蜥社区的成长故事。 ...
[详细]
蜡笔小新 2024-11-21 11:12:28
机器学习
Python 领跑!2019年2月编程语言排名更新
根据最新的编程语言流行指数(PYPL)排行榜,Python 在2019年2月的份额达到了26.42%,稳坐榜首位置。 ...
[详细]
蜡笔小新 2024-11-21 09:18:39
机器学习
使用 Jupyter Notebook 实现 Markdown 编写与代码运行
Jupyter Notebook 是一个开源的基于网页的应用程序,允许用户在同一文档中编写 Markdown 文本和运行多种编程语言的代码,并实时查看运行结果。 ...
[详细]
蜡笔小新 2024-11-15 14:50:50
机器学习
吴恩达机器学习+deeplearning课程笔记干货链接分享
分享两个GitHub链接,今天看到的,超赞超赞不能更赞了,答应我一定要去看好吗~~~~不论是笔记还是github中分享的其它资源ÿ ...
[详细]
蜡笔小新 2024-11-15 09:24:12
深度
Java 网站开发指南
本文详细介绍了 Java 网站开发的相关资源和步骤,包括常用网站、开发环境和框架选择。 ...
[详细]
蜡笔小新 2024-11-14 22:39:58
pytorch
Google Colab 免费 GPU 使用指南(第一部分)
本文介绍了如何使用 Google Colab 的免费 GPU 资源进行深度学习应用开发。Google Colab 是一个无需配置即可使用的云端 Jupyter 笔记本环境,支持多种深度学习框架,并且提供免费的 GPU 计算资源。 ...
[详细]
蜡笔小新 2024-11-14 13:42:03
深度
非计算机专业的朋友如何拿下多个Offer
大家好,我是归辰。秋招结束后,我已顺利入职,并应公子龙的邀请,分享一些秋招面试的心得体会,希望能帮助到学弟学妹们,让他们在未来的面试中更加顺利。 ...
[详细]
蜡笔小新 2024-11-13 18:41:58
深度
深度学习入门 - 理解神经网络的基本概念
本文介绍了实现人工智能的多种方法,并重点探讨了当前最热门的技术——通过深度学习训练神经网络。文章通过具体实例详细解释了神经网络的基本原理及其应用。 ...
[详细]
蜡笔小新 2024-11-13 17:35:06
机器学习
利用OpenCV和线性SVM实现人脸识别
本文介绍如何使用OpenCV和线性支持向量机(SVM)模型来开发一个简单的人脸识别系统,特别关注在只有一个用户数据集时的处理方法。 ...
[详细]
蜡笔小新 2024-11-13 14:50:37
深度
Python 数据可视化实战指南
本文详细介绍如何使用 Python 进行数据可视化,涵盖从环境搭建到具体实例的全过程。 ...
[详细]
蜡笔小新 2024-11-13 06:03:30
机器学习
从0到1搭建大数据平台
从0到1搭建大数据平台 ...
[详细]
蜡笔小新 2024-11-12 15:26:03
深度
飞桨助力产业智能化:百度自研AI硬件深度融合
在2019中国国际智能产业博览会上,百度董事长兼CEO李彦宏强调,人工智能应务实推进其在各行业的应用。随后,在“ABC SUMMIT 2019百度云智峰会”上,百度展示了通过“云+AI”推动AI工业化和产业智能化的最新成果。 ...
[详细]
蜡笔小新 2024-11-12 00:45:20
深度学习
在Windows系统中安装TensorFlow GPU版的详细指南与常见问题解决
在Windows系统中安装TensorFlow GPU版是许多深度学习初学者面临的挑战。本文详细介绍了安装过程中的每一个步骤,并针对常见的问题提供了有效的解决方案。通过本文的指导,读者可以顺利地完成安装并避免常见的陷阱。 ...
[详细]
蜡笔小新 2024-11-11 19:02:49
自然语言处理
Linux系统中权限修改命令详解:chmod使用方法与技巧
在Linux系统中,`chmod`命令用于修改文件和目录的访问权限。文件和目录的访问控制由其所有权和权限设置决定。本文将详细介绍`chmod`命令的使用方法和技巧,帮助用户更好地管理和控制文件系统的安全性。 ...
[详细]
蜡笔小新 2024-11-11 17:36:22
深度
机器学习的持续探索与进展
在机器学习领域,深入探讨了概率论与数理统计的基础知识,特别是这些理论在数据挖掘中的应用。文章重点分析了偏差(Bias)与方差(Variance)之间的平衡问题,强调了方差反映了不同训练模型之间的差异,例如在K折交叉验证中,不同模型之间的性能差异显著。此外,还讨论了如何通过优化模型选择和参数调整来有效控制这一平衡,以提高模型的泛化能力。 ...
[详细]
蜡笔小新 2024-11-11 10:27:39
一根吃兔子的萝卜
这个家伙很懒,什么也没留下!
Tags | 热门标签
tensorflow
人脸识别
算法
人工智能
svm
深度学习
机器人
自动驾驶
自然语言处理
ocr
数据挖掘
图像识别
机器学习
nlp
神经网络
深度
pytorch
RankList | 热门文章
1
Java编程实践第6条:减少无谓的对象实例化以提升性能和资源利用效率
2
体验八块腹肌与智能屏幕互动的独特魅力
3
康宁发布Victus大猩猩玻璃:2米高度跌落仍完好,抗划伤能力达历史最佳水平
4
在 Ubuntu 系统中配置 br0 网桥,实测验证有效
5
Python进阶精讲(第三篇):深入探索高级特性与应用技巧
6
将PEBuilder转换为DIBooter.sh,集成DI工具至启动层(5):实现离线镜像引导安装
7
Linux学习精华:程序管理、终端种类与命令帮助获取方法综述
8
Linux系统下MySQL用户权限管理详解——第四阶段运维指南
9
深入RTOS实践,面对原子操作提问竟感困惑
10
ZeroMQ在云计算环境下的高效消息传递库第四章学习心得
11
【汇编语言 局部标签解析】beq %F1 指令中百分号的作用与含义
12
沙漏结构中的最大总和值分析
13
数据可视化 | 探索全球70亿人的生活方式与活动分布
14
解决 Ubuntu 系统中因 LC_CTYPE 或 LC_ALL 设置不当引起的中文字符显示异常问题
15
如何在MySQL中安全地更改主键值
PHP1.CN | 中国最专业的PHP中文社区 |
DevBox开发工具箱
|
json解析格式化
|
PHP资讯
|
PHP教程
|
数据库技术
|
服务器技术
|
前端开发技术
|
PHP框架
|
开发工具
|
在线工具
Copyright © 1998 - 2020 PHP1.CN. All Rights Reserved |
京公网安备 11010802041100号
|
京ICP备19059560号-4
| PHP1.CN 第一PHP社区 版权所有
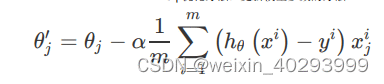








 京公网安备 11010802041100号 | 京ICP备19059560号-4 | PHP1.CN 第一PHP社区 版权所有
京公网安备 11010802041100号 | 京ICP备19059560号-4 | PHP1.CN 第一PHP社区 版权所有