作者:丿氵小柒柒2502894463 | 来源:互联网 | 2024-12-08 13:03
1. 概述
用户兴趣是推荐系统中非常重要的trigger,在召回阶段,通过召回与用户兴趣相匹配的item,在排序阶段,用户兴趣作为很重要的一个特征维度,与用户兴趣越相似的item将会被排到越靠前的位置。因此,在推荐系统中,对于用户兴趣的建模显得尤为重要。在目前为止,通常采用的方法是对用户的历史行为挖掘,实现对用户兴趣的建模。
在实际生活中,一个人的兴趣通常是多方面的,不是单一的,传统的建模方式是将用户的行为序列转成固定长度的embedding形式,这样的方式却限制了对用户兴趣的建模能力。其主要原因是用户的兴趣是多样的,统一的固定长度的embedding难以刻画用户兴趣的多样性。深度兴趣网络DIN[1]通过使用Attention机制捕获目标item与用户行为序列中的item之间的相关性,从而实现对特定的目标item的兴趣建模,并将其应用到排序阶段。
2. 算法原理
2.1. 基本模型
DIN模型也是建立在基本模型MLP基础上,对于基础模型Base Model如下图所示:
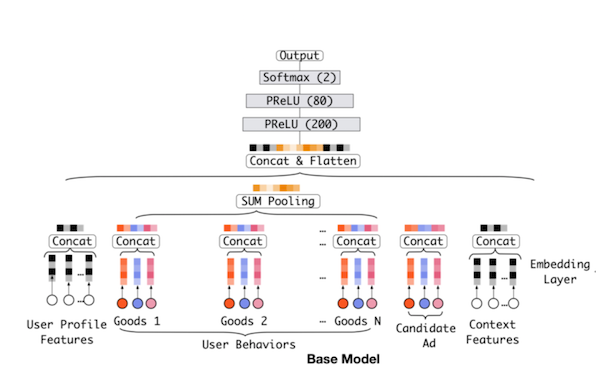
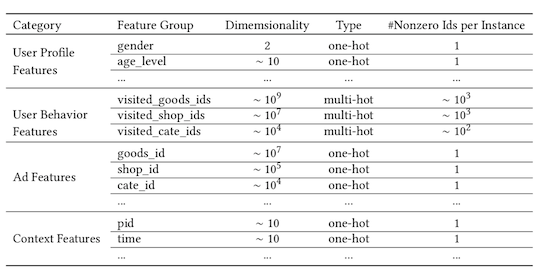
对于CTR预估,特征主要包括用户画像特征(User Profile Features),用户行为特征(User Behavior Features),目标item的特征(Candidate Ad)以及上下文特征(Context Features)。上述的特征中,对于离散的类别特征,通常转换成one-hot或者multi-hot形式,具体如下图所示:
通过对用户历史行为的特征进行pooling操作,实现对用户兴趣的建模,并与其他的特征,如用户的画像特征,待排序item特征,上下文特征一起实现CTR预估,最终,模型的损失函数为:
L=−1N∑(x,y∈S)(ylogp(x)+(1−y)log(1−p(x)))L=-\frac{1}{N}\sum_{\left ( \boldsymbol{x},y\in S \right )}\left ( ylog\, p\left ( \boldsymbol{x} \right ) + \left ( 1-y \right )log\left ( 1-p\left ( \boldsymbol{x} \right ) \right )\right )L=−N1(x,y∈S)∑(ylogp(x)+(1−y)log(1−p(x)))
2.2. 深度兴趣网络DIN
在实际场景中,用户的兴趣往往是多样的,或者说是多个维度的,在上述基本的网络模型中,通过对用户行为序列建模,得到用户兴趣的固定长度的向量表示,这样的固定长度的向量难以表达用户的不同兴趣。在深度兴趣网络(Deep Interest Network,DIN)[1]中,借鉴Attention的原理,通过计算候选item与用户行为序列中item之间的相关关系,来动态的计算用户在当前的item下的即时兴趣向量。
2.2.1. DIN的模型结构
DIN的模型结构如下图所示:
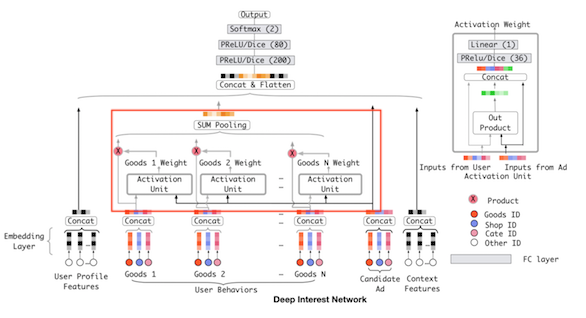
DIN的模型结构与基本模型结构基本一致,不同的是在计算用户兴趣向量时,使用了如下的计算方式:
vU(A)=f(vA,e1,e2,⋯,eH)=∑j=1Ha(ej,vA)ej=∑j=1Hwjej\boldsymbol{v}_U\left ( A \right )=f\left ( \boldsymbol{v}_A,\boldsymbol{e}_1,\boldsymbol{e}_2,\cdots ,\boldsymbol{e}_H \right )=\sum_{j=1}^{H}a\left ( \boldsymbol{e}_j,\boldsymbol{v}_A \right )\boldsymbol{e}_j=\sum_{j=1}^{H}\boldsymbol{w}_j\boldsymbol{e}_jvU(A)=f(vA,e1,e2,⋯,eH)=j=1∑Ha(ej,vA)ej=j=1∑Hwjej
2.2.2. DIN的实现差异
在[3]的官方实现中,在计算Activation Weight的过程中,有几点与原文中不一致:
- 特征
从上面的图中,我们看到是将User的特征,Ad的特征,以及Out Product(两者的外积)的特征concat在一起,在代码中是将:queries,facts,queries - facts,queries * facts这四项concat在一起:
in_all = tf.concat([queries, facts, queries - facts, queries * facts], axis=-1)
其中queries表示的是Ad向量,facts表示的是User的行为向量,queries * facts表示的是外积。
- 是否归一化
原文中指出不需要归一化,但是在代码中却是可以使用了归一化的操作,如下所示:
# Activation
if softmax_stag: # 是否使用归一化scores = tf.nn.softmax(scores) # [B, 1, T]
# Weighted sum
if mode == 'SUM': # 加权求和output = tf.matmul(scores, facts) # [B, 1, H]
完整的实现可以参见参考文献[3]。
3. 总结
鉴于单一的固定向量不能表达用户兴趣的多样性,在深度兴趣网络DIN中使用了注意力机制捕获目标item与用户的行为序列中的item之间的相关性,得到在特定目标item的场景下的用户兴趣表示,从而提升对用户及时兴趣的捕捉能力。
参考文献
[1]. Zhou G , Song C , Zhu X , et al. Deep Interest Network for Click-Through Rate Prediction[J]. 2017.
[2]. 推荐系统CTR模型:Deep Interest Network(DIN)源码分析
[3]. DIN官方实现







![扫描线三巨头 hdu1928hdu 1255 hdu 1542 [POJ 1151]](https://img.php1.cn/3c972/245b5/42f/19446f78530d3747.jpeg)

 京公网安备 11010802041100号
京公网安备 11010802041100号