欢迎关注博主的公众号:happyGirl的异想世界。有更多干货还有技术讨论群哦~
LeNet-5LeNet-5是Yann LeCun在1998年设计的用于手写数字识别的卷积神经网络,当年美国大多数银行就是用它来识别支票上面的手写数字的,它是早期卷积神经网络中最有代表性的实验系统之一。
LenNet-5共有7层(不包括输入层),每层都包含不同数量的训练参数,如下图所示。

其参数:

AlexNet是2012年ImageNet竞赛冠军获得者Hinton和他的学生Alex Krizhevsky设计的。也是在那年之后,更多的更深的神经网络被提出,比如优秀的vgg,GoogLeNet。 这对于传统的机器学习分类算法而言,已经相当的出色。
alexNet为8层深度网络,其中5层卷积层和3层全连接层,不计LRN层和池化层。结构图如下图所示:

详解各层训练参数的计算:
前五层:卷积层

后三层:全连接层

整体计算图:

也可以这么看:

VGGNet (https://arxiv.org/pdf/1409.1556.pdf) 发布于2014年,作者是Karen Simonyan和Andrew Zisserman,该网络表明堆叠多个层是提升计算机视觉性能的关键因素。VGGNet包含16或19层,主要由小型的3X3卷积操作和2X2池化操作组成。
创新点:VGGNet全部使用3*3的卷积核和2*2的池化核,通过不断加深网络结构来提升性能。网络层数的增长并不会带来参数量上的爆炸,因为参数量主要集中在最后三个全连接层中。同时,两个3*3卷积层的串联相当于1个5*5的卷积层,3个3*3的卷积层串联相当于1个7*7的卷积层,即3个3*3卷积层的感受野大小相当于1个7*7的卷积层。但是3个3*3的卷积层参数量只有7*7的一半左右,同时前者可以有3个非线性操作,而后者只有1个非线性操作,这样使得前者对于特征的学习能力更强。

使用1*1的卷积层来增加线性变换,输出的通道数量上并没有发生改变。这里提一下1*1卷积层的其他用法,1*1的卷积层常被用来提炼特征,即多通道的特征组合在一起,凝练成较大通道或者较小通道的输出,而每张图片的大小不变。有时1*1的卷积神经网络还可以用来替代全连接层。
其他小技巧。VGGNet在训练的时候先训级别A的简单网络,再复用A网络的权重来初始化后面的几个复杂模型,这样收敛速度更快。VGGNet作者总结出LRN层作用不大,越深的网络效果越好,1*1的卷积也是很有效的,但是没有3*3的卷积效果好,因为3*3的网络可以学习到更大的空间特征。
优点:1.参数量减少了 81%(相比alxexnet),而感受野保持不变。
2.小卷积核的使用也扮演了正则化器的角色,并提高了不同卷积核的有效性。
缺点:其评估的开销比浅层网络更加昂贵,内存和参数(140M)也更多。这些参数的大部分都可以归因于第一个全连接层。
网络结构:VGGNet的网络结构如下图所示。VGGNet包含很多级别的网络,深度从11层到19层不等,比较常用的是VGGNet-16和VGGNet-19。VGGNet把网络分成了5段,每段都把多个3*3的卷积网络串联在一起,每段卷积后面接一个最大池化层,最后面是3个全连接层和一个softmax层。网络结构图:

代码实现参考自tensorflow的开源实现:
#%%
# Copyright 2016 The TensorFlow Authors. All Rights Reserved.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
# ==============================================================================
from datetime import datetime
import math
import time
import tensorflow as tfdef conv_op(input_op, name, kh, kw, n_out, dh, dw, p):n_in = input_op.get_shape()[-1].valuewith tf.name_scope(name) as scope:kernel = tf.get_variable(scope+"w",shape=[kh, kw, n_in, n_out],dtype=tf.float32, initializer=tf.contrib.layers.xavier_initializer_conv2d())conv = tf.nn.conv2d(input_op, kernel, (1, dh, dw, 1), padding='SAME')bias_init_val = tf.constant(0.0, shape=[n_out], dtype=tf.float32)biases = tf.Variable(bias_init_val, trainable=True, name='b')z = tf.nn.bias_add(conv, biases)activation = tf.nn.relu(z, name=scope)p += [kernel, biases]return activationdef fc_op(input_op, name, n_out, p):n_in = input_op.get_shape()[-1].valuewith tf.name_scope(name) as scope:kernel = tf.get_variable(scope+"w",shape=[n_in, n_out],dtype=tf.float32, initializer=tf.contrib.layers.xavier_initializer())biases = tf.Variable(tf.constant(0.1, shape=[n_out], dtype=tf.float32), name='b')activation = tf.nn.relu_layer(input_op, kernel, biases, name=scope)p += [kernel, biases]return activationdef mpool_op(input_op, name, kh, kw, dh, dw):return tf.nn.max_pool(input_op,ksize=[1, kh, kw, 1],strides=[1, dh, dw, 1],padding='SAME',name=name)def inference_op(input_op, keep_prob):p = []# assume input_op shape is 224x224x3# block 1 -- outputs 112x112x64conv1_1 = conv_op(input_op, name="conv1_1", kh=3, kw=3, n_out=64, dh=1, dw=1, p=p)conv1_2 = conv_op(conv1_1, name="conv1_2", kh=3, kw=3, n_out=64, dh=1, dw=1, p=p)pool1 = mpool_op(conv1_2, name="pool1", kh=2, kw=2, dw=2, dh=2)# block 2 -- outputs 56x56x128conv2_1 = conv_op(pool1, name="conv2_1", kh=3, kw=3, n_out=128, dh=1, dw=1, p=p)conv2_2 = conv_op(conv2_1, name="conv2_2", kh=3, kw=3, n_out=128, dh=1, dw=1, p=p)pool2 = mpool_op(conv2_2, name="pool2", kh=2, kw=2, dh=2, dw=2)# # block 3 -- outputs 28x28x256conv3_1 = conv_op(pool2, name="conv3_1", kh=3, kw=3, n_out=256, dh=1, dw=1, p=p)conv3_2 = conv_op(conv3_1, name="conv3_2", kh=3, kw=3, n_out=256, dh=1, dw=1, p=p)conv3_3 = conv_op(conv3_2, name="conv3_3", kh=3, kw=3, n_out=256, dh=1, dw=1, p=p) pool3 = mpool_op(conv3_3, name="pool3", kh=2, kw=2, dh=2, dw=2)# block 4 -- outputs 14x14x512conv4_1 = conv_op(pool3, name="conv4_1", kh=3, kw=3, n_out=512, dh=1, dw=1, p=p)conv4_2 = conv_op(conv4_1, name="conv4_2", kh=3, kw=3, n_out=512, dh=1, dw=1, p=p)conv4_3 = conv_op(conv4_2, name="conv4_3", kh=3, kw=3, n_out=512, dh=1, dw=1, p=p)pool4 = mpool_op(conv4_3, name="pool4", kh=2, kw=2, dh=2, dw=2)# block 5 -- outputs 7x7x512conv5_1 = conv_op(pool4, name="conv5_1", kh=3, kw=3, n_out=512, dh=1, dw=1, p=p)conv5_2 = conv_op(conv5_1, name="conv5_2", kh=3, kw=3, n_out=512, dh=1, dw=1, p=p)conv5_3 = conv_op(conv5_2, name="conv5_3", kh=3, kw=3, n_out=512, dh=1, dw=1, p=p)pool5 = mpool_op(conv5_3, name="pool5", kh=2, kw=2, dw=2, dh=2)# flattenshp = pool5.get_shape()flattened_shape = shp[1].value * shp[2].value * shp[3].valueresh1 = tf.reshape(pool5, [-1, flattened_shape], name="resh1")# fully connectedfc6 = fc_op(resh1, name="fc6", n_out=4096, p=p)fc6_drop = tf.nn.dropout(fc6, keep_prob, name="fc6_drop")fc7 = fc_op(fc6_drop, name="fc7", n_out=4096, p=p)fc7_drop = tf.nn.dropout(fc7, keep_prob, name="fc7_drop")fc8 = fc_op(fc7_drop, name="fc8", n_out=1000, p=p)softmax = tf.nn.softmax(fc8)predictions = tf.argmax(softmax, 1)return predictions, softmax, fc8, pdef time_tensorflow_run(session, target, feed, info_string):num_steps_burn_in = 10total_duration = 0.0total_duration_squared = 0.0for i in range(num_batches + num_steps_burn_in):start_time = time.time()_ = session.run(target, feed_dict=feed)duration = time.time() - start_timeif i >= num_steps_burn_in:if not i % 10:print ('%s: step %d, duration = %.3f' %(datetime.now(), i - num_steps_burn_in, duration))total_duration += durationtotal_duration_squared += duration * durationmn = total_duration / num_batchesvr = total_duration_squared / num_batches - mn * mnsd = math.sqrt(vr)print ('%s: %s across %d steps, %.3f +/- %.3f sec / batch' %(datetime.now(), info_string, num_batches, mn, sd))def run_benchmark():with tf.Graph().as_default():image_size = 224images = tf.Variable(tf.random_normal([batch_size,image_size,image_size, 3],dtype=tf.float32,stddev=1e-1))keep_prob = tf.placeholder(tf.float32)predictions, softmax, fc8, p = inference_op(images, keep_prob)init = tf.global_variables_initializer()config = tf.ConfigProto()config.gpu_options.allocator_type = 'BFC'sess = tf.Session(config=config)sess.run(init)time_tensorflow_run(sess, predictions, {keep_prob:1.0}, "Forward")objective = tf.nn.l2_loss(fc8)grad = tf.gradients(objective, p)time_tensorflow_run(sess, grad, {keep_prob:0.5}, "Forward-backward")batch_size=32
num_batches=100
run_benchmark()
ResNet
何凯明2016CVPR:Deep Residual Learning for Image Recognition
代表网络 :resnet50 resnet101,resnet152
优点:
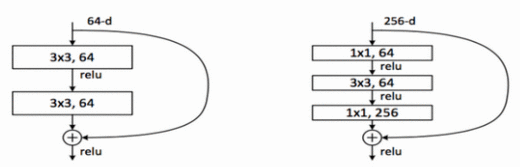
1.增加了神经网络架构的跳过连接(skip connection),卷积层的默认函数变成了恒等函数,卷积核学到的任何新信息都可以在基本表征中添加或减去,因此更容易优化残差映射。跳过连接不会增加参数的数量,但可以获得更稳定的训练和显著的性能提升。
2.每次卷积完成后、激活进行前都采取批归一化。
3.网络删除了全连接层,并使用平均池化层减少参数的数量。由于网络加深,卷积层的抽象能力更强,从而减少了对全连接层的需求。
4.引用1*1卷机来降维和升维,在进行3*3卷机之前,先对特征图进行降为,卷机后升维,恢复原来的维度。这样进行卷机操作的时候可以降低参数的数量,而且可以增加非线性。

具体:
Inception
(详见http://baijiahao.baidu.com/s?id=1601882944953788623&wfr=spider&for=pc)
代表网络 :
Inception v1,
Inception v2 和 Inception v3,
Inception v4 和 Inception-ResNet
Inception v1
论文:Going deeper with convolutions
论文链接:https://arxiv.org/pdf/1409.4842v1.pdf

Inception v2
论文:Rethinking the Inception Architecture for Computer Vision
论文地址:https://arxiv.org/pdf/1512.00567v3.pdf

Inception v3
这个非常常用
问题:
作者注意到辅助分类器直到训练过程快结束时才有较多贡献,那时准确率接近饱和。作者认为辅助分类器的功能是正则化,尤其是它们具备 BatchNorm 或 Dropout 操作时。是否能够改进 Inception v2 而无需大幅更改模块仍需要调查。
解决方案:
Inception Net v3 整合了前面 Inception v2 中提到的所有升级,还使用了:
RMSProp 优化器;Factorized 7x7 卷积;辅助分类器使用了 BatchNorm;标签平滑(添加到损失公式的一种正则化项,旨在阻止网络对某一类别过分自信,即阻止过拟合)。
Inception v4
由于v3无法解决太多类别
Inception v4 和 Inception -ResNet 在同一篇论文《Inception-v4, Inception-ResNet and the Impact of Residual Connections on Learning》中介绍。为清晰起见,我们分成两个部分来介绍。
在该论文中,研究者介绍道,Inception 架构可以用很低的计算成本达到很高的性能。而在传统的网络架构中引入残差连接曾在 2015ILSVRC 挑战赛中获得当前最佳结果,其结果和 Inception-v3 网络当时的最新版本相近。这使得人们好奇,如果将 Inception 架构和残差连接结合起来会是什么效果。在这篇论文中,研究者通过实验明确地证实了,结合残差连接可以显著加速 Inception 的训练。也有一些证据表明残差 Inception 网络在相近的成本下略微超过没有残差连接的 Inception 网络。研究者还展示了多种新型残差和非残差 Inception 网络的简化架构。这些变体显著提高了在 ILSVRC2012 分类任务挑战赛上的单帧识别性能。作者进一步展示了适当的激活值缩放如何稳定非常宽的残差 Inception 网络的训练过程。通过三个残差和一个 Inception v4 的模型集成,作者在 ImageNet 分类挑战赛的测试集上取得了 3.08% 的 top-5 误差率。
论文:Inception-v4, Inception-ResNet and the Impact of Residual Connections on Learning
论文地址:https://arxiv.org/pdf/1602.07261.pdf

Inception-ResNet v1 和 v2
受 ResNet 的优越性能启发,研究者提出了一种混合 inception 模块。Inception ResNet 有两个子版本:v1 和 v2。在我们分析其显著特征之前,先看看这两个子版本之间的微小差异。
Inception-ResNet v1 的计算成本和 Inception v3 的接近。Inception-ResNetv2 的计算成本和 Inception v4 的接近。它们有不同的 stem,正如 Inception v4 部分所展示的。两个子版本都有相同的模块 A、B、C 和缩减块结构。唯一的不同在于超参数设置。在这一部分,我们将聚焦于结构,并参考论文中的相同超参数设置(图像是关于 Inception-ResNet v1 的)。
问题:
引入残差连接,它将 inception 模块的卷积运算输出添加到输入上。
解决方案:
为了使残差加运算可行,卷积之后的输入和输出必须有相同的维度。因此,我们在初始卷积之后使用 1x1 卷积来匹配深度(深度在卷积之后会增加)。
V1
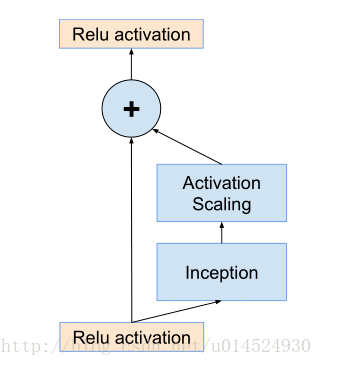
1.使用更简单的inception模型。并且每个inception分支后面都跟着一个1x1线性卷积层(就是不带激活函数的卷积层),这是为了匹配输入时的维度,因为残差分支是直接将输入送给输出,但是inception这边很明显进行通道压缩了,所以要通过1x1卷积重新扩增到输入时的维度,用原文话说就是,补偿inception模块带来的降维。

2.它说如果通道数量超过1000时,这个inception-resnet就会失去稳定,并且在训练的早期死亡,死亡意指几千次迭代后在平均池化前的最后一层会开始完全零化,就是只产生很小的数。并且这种现象无法被避免,无论是调低学习率还是增加批次归一化在这一层。但是他们发现如果在将其添加到前一层激活函数之前进行缩小似乎就能稳定训练,一般他们会挑选一些0.1到0.3之间的缩放系数在进行累加层激活之前来压缩inception-resnet模组。
Reduction-A:

inception-resnet-A:
1.使用更简单的inception模型。并且每个inception分支后面都跟着一个1x1线性卷积层(就是不带激活函数的卷积层),这是为了匹配输入时的维度,因为残差分支是直接将输入送给输出,但是inception这边很明显进行通道压缩了,所以要通过1x1卷积重新扩增到输入时的维度,用原文话说就是,补偿inception模块带来的降维。
2.它说如果通道数量超过1000时,这个inception-resnet就会失去稳定,并且在训练的早期死亡,死亡意指几千次迭代后在平均池化前的最后一层会开始完全零化,就是只产生很小的数。并且这种现象无法被避免,无论是调低学习率还是增加批次归一化在这一层。但是他们发现如果在将其添加到前一层激活函数之前进行缩小似乎就能稳定训练,一般他们会挑选一些0.1到0.3之间的缩放系数在进行累加层激活之前来压缩inception-resnet模组。
Reduction-A:
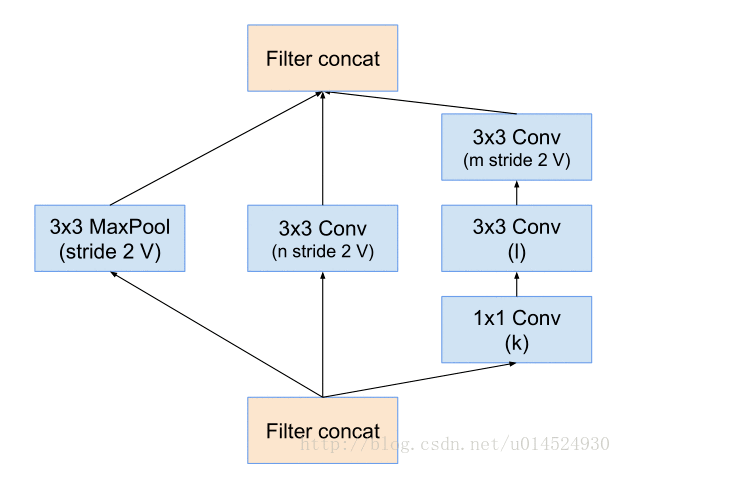
这张图上通道数是变量。这个模组是三个模型共用的,所以不同模型有不同系数。reduction就是减少的意思,这个模组负责减半数据空间尺寸,并且加深通道,不知道从某种程度上我们是否可以将其理解为聚集特征。
inception-resnet-B:
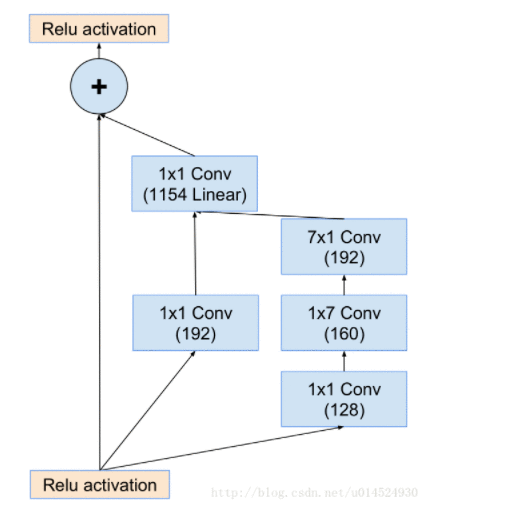
inception-resnet-C:
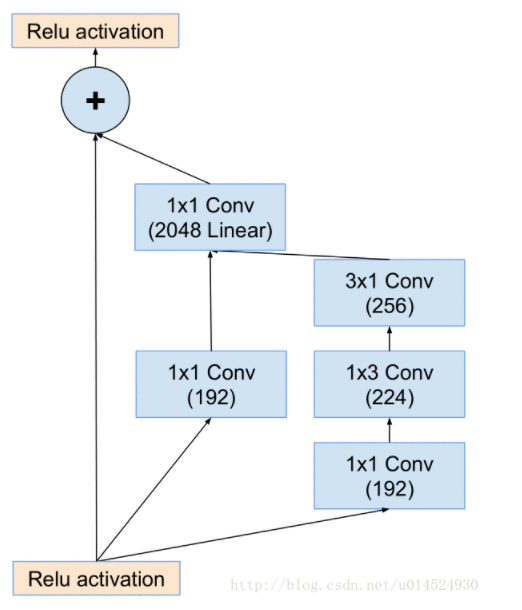
ResNeXt:
文中提出了另外一种维度cardinality,和channel和space的维度不同,cardinality维度主要表示ResNeXt中module的个数。
1.增大Cardinality比增大模型的width或者depth效果更好
2.与 ResNet 相比,ResNeXt 参数更少,效果更好,结构更加简单,更方便设计
Xception:
在Inception V3的基础上提出了Xception(Extreme Inception),基本思想就是通道分离式卷积(depthwise separable convolution operation)。模型参数有微量的减少,减少量很少。精度较Inception V3有提高,但提高不大。卷积的操作上面,主要进行2种变换,空间变换和通道变换而Xception就是在这2个变换上做文章。
1.ception V3是先做1*1的卷积,再做3*3的卷积,这样就先将通道进行了合并,即通道卷积,然后再进行空间卷积,而Xception则正好相反,先进行空间的3*3卷积,再进行通道的1*1卷积。
2.这个区别是最不一样的,Inception V3在每个module中都有RELU操作,而Xception在每个module中是没有RELU操作的。
mobilenets:
MobileNets其实就是Exception思想的应用。区别就是Exception文章重点在提高精度,而MobileNets重点在压缩模型,同时保证精度。obileNets模型基于深度可分解的卷积,它可以将标准卷积分解成一个深度卷积和一个点卷积(1 × 1卷积核)。深度卷积将每个卷积核应用到每一个通道,而1 × 1卷积用来组合通道卷积的输出。
宽度乘数:
这里介绍模型的第一个超参数,即宽度乘数 α 。为了构建更小和更少计算量的网络,作者引入了宽度乘数 α ,作用是改变输入输出通道数,减少特征图数量,让网络变瘦。在 α 参数作用下,MobileNets某一层的计算量为:
DK×DK×αM×DF×DF+αM×αN×DF×DF
其中, α 取值是0~1,应用宽度乘数可以进一步减少计算量,大约有 α2 的优化空间。
分辨率乘数:
第二个超参数是分辨率乘数 ρ ,分辨率乘数用来改变输入数据层的分辨率,同样也能减少参数。在 α 和 ρ 共同作用下,MobileNets某一层的计算量为:
DK×DK×αM×ρDF×ρDF+αM×αN×ρDF×ρDF
其中,ρ 是隐式参数,ρ 如果为{1,6/7,5/7,4/7},则对应输入分辨率为{224,192,160,128},ρ 参数的优化空间同样是 ρ2 左右。 表3可以看出两个超参数在减少网络参数的上的作用。
参考文献:
(第3个为LeNet-5,第4个为AlexNet,第5个VGG,)
https://www.e-learn.cn/content/qita/725036
http://www.360doc.com/content/18/0402/16/48868863_742310994.shtml
https://blog.csdn.net/happyorg/article/details/78274066
https://blog.csdn.net/u012679707/article/details/80793916
https://blog.csdn.net/u013181595/article/details/80974210
http://baijiahao.baidu.com/s?id=1601882944953788623&wfr=spider&for=pc



 京公网安备 11010802041100号 | 京ICP备19059560号-4 | PHP1.CN 第一PHP社区 版权所有
京公网安备 11010802041100号 | 京ICP备19059560号-4 | PHP1.CN 第一PHP社区 版权所有