作者:陀飞轮小朱朱 | 来源:互联网 | 2023-09-12 16:54
本文为AI研习社编译的技术博客,原标题:What’sNewinDeepLearningResearch:HowGoogleBuildsCuriosityIntoReinforcem

本文为 AI 研习社编译的技术博客,原标题 :
What’s New in Deep Learning Research: How Google Builds Curiosity Into Reinforcement Learning Agents
作者 | Jesus Rodriguez
翻译 | 酱番梨、卜嘉田、will_L_Q、Disillusion、J. X.L. Chan
校对 | Pita 审核 | 约翰逊·李加薪 整理 | 立鱼王
原文链接:
https://towardsdatascience.com/whats-new-in-deep-learning-research-how-google-builds-curiosity-into-reinforcement-learning-32d77af719e8

探索-利用困境是规范强化学习算法的动力之一。如何平衡智能体应该探索环境的程度与如何执行特定操作和评估奖励?在强化学习的背景下,探索和开发被视为奖励模型中抑制好奇心的相反力量。然而,就像人类的认知一样,强化学习智能体的好奇心产生于正确的知识,那么我们如何在不惩罚智能体的情况下激发好奇心呢?这是Google Research最近发表的一篇研究论文的主题,论文介绍了一种在强化学习智能体中激发好奇心的方法。
大多数强化学习算法都基于结构化奖励模型,该模型假设有一组密集的奖励可以与代理的行为相关联。 然而,现实世界中的许多环境都基于稀疏的奖励机制,这些奖励不易适应强化学习机制。 考虑到强化学习智能体需要在库环境中查找特定书籍的场景。 智能体可以不断地搜索,但书籍无处可寻,并且对特定行为没有明确的奖励。 稀疏奖励环境对于强化学习智能体来说是非常具有挑战性的,因为他们不得不在没有明确奖励的情况下不断探索环境。 在那些环境中,强化学习智能体的“好奇心”对获得适当的奖励功能至关重要。 换句话说,强化学习环境中的奖励稀疏性与好奇心之间存在直接关系。
好奇心一直是强化学习中的一个活跃研究领域。大多数强化学习中好奇心公式旨在最大限度地增加“惊奇”或者无法预测未来。这种方法从神经科学的好奇心理论中得到启发,但已被证明在强化学习模型中相对低效。效率低下的核心原因是,最大化与目标任务无关的好奇心没有直接关系,因此会导致拖延。下面让我来解释这恼人的事实?
让我们以一个环境为例,在这个环境中,强化学习智能体被放入一个三维迷宫中。迷宫中有一个珍贵的目标,它会给予很大的奖励。现在,智能体被给予了电视遥控器,并可以切换频道。每个频道显示一个随机图像(从一组固定的图像中选取)。优化惊喜的好奇心公式会很高兴,因为频道切换的结果是不可预测的。智能体将永远停留在电视机前,而不会试图解决目标任务。
这种困境很明显:强化学习模型只应在有利于最终目标的情况下才能最大限度地激发好奇心。然而,我们如何知道哪些探索性步骤与目标任务相关而哪些又不相关。谷歌通过提出一种称为Episodic Curiosity的方法来应对这一挑战。
谷歌在强化学习领域的创新之处在于,通过引入努力的概念解决好奇心-拖延之间的摩擦。从本质上来讲,情境记忆方法是一种仅对需要一定努力而获取的观察数据给与奖励的方法,它建议去避免“自我沉溺的行为”。根据我们电视迷宫(maze-tv)例子,在转换频道之后,所有的节目将最终在内存中结束。因此,电视节目将不会具有任何吸引力,因为出现在屏幕上的节目顺序是随机的和不可预知的,所有这些节目都已经在存储中了!一个情境存储智能体将检查过去, 以确定它是否看到了与当前类似的观察结果,在这种情况下, 它不会得到任何奖励。在电视上反复播放几次之后,情景存储代理就不会被即时满足所吸引,而必须去探索电视之外的世界以获得额外的奖励。听起来是不是聪明啊?
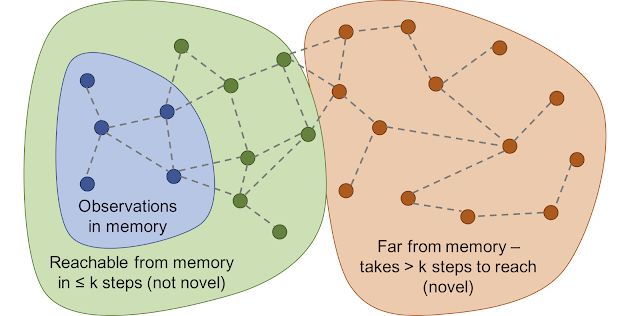
情景记忆方法把好奇心和图的可达性联系起来。智能体在剧集开始时以一个空的存储开始,每一步都将当前的观察结果与存储中的观察结果进行比较,以确定它的新颖性。如果当前的观察确实是新颖的 - 那么从记忆中的观察中采取的步骤比阈值更多 - 那么智能体就会奖励自己,并将当前的观察添加到情景存储中。这个过程一直持续到剧集结束, 此时存储将会被抹去。
为了在强化学习代理中实现情景记忆功能,谷歌依赖于一种架构,该架构将两个神经网络与情景记忆缓冲器和奖赏估计模块相结合,如下图所示:
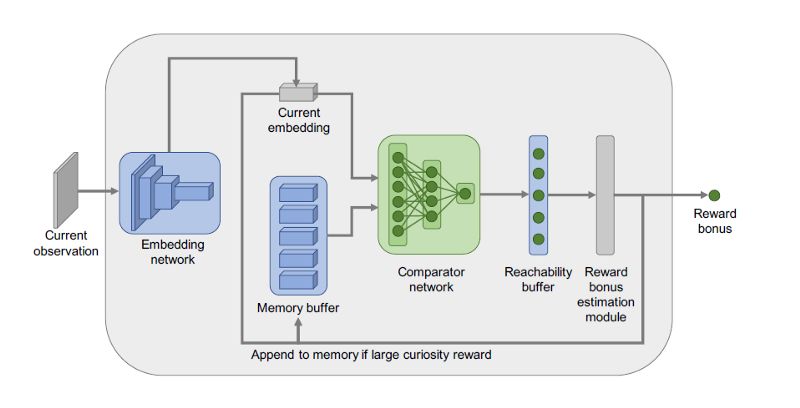
让我们来看看情景记忆架构的各个组成部分:
-
嵌入和比较器网络:这两个网络的目的是在给定另一个输入观察的情况下预测特定观察的可达性。具体而言,两个网络是基于一个称为R-Network的架构,这是一个由逻辑回归的损失训练的分类器:如果在k步内两个观测从一个到另外一个的可达的概率比较低,那么它的预测值接近于0,反之,当概率是很高时,其值接近于1。
-
情景记忆缓冲器:情景记忆缓冲器存储当前情景中过去的观察结果的嵌入,以便根据特定的观察结果进行评估。
-
奖励估计模块:该模块的目的是检查内存中是否有可达到的观察结果,如果没有,则进行检查。从本质上说,通过从当前状态只采取一些行动,这个模块的检查确保在内存中没有观察可以达到,因此鼓励好奇心。
Google在一系列视觉环境(如ViZDoom和DMLab)中测试了情景记忆强化学习模型,结果非常出色。 在这些环境中,智能体的任务是处理各种问题,例如在迷宫中搜索目标或收集好的内容以及避免坏对象。 DMLab环境碰巧为智能体提供了类似激光科幻小说中物件。 之前关于DMLab的工作中的标准设置是为智能体配备所有任务的小工具,如果智能体不需要特定任务的小工具,则可以免费使用它。 奖励的稀疏性使得这些环境对于大多数传统的强化学习方法而言非常具有挑战性。 当负责在迷宫中搜索高回报的项目时,它更喜欢花时间标记墙壁,因为这会产生很多“惊喜”奖励。

在相同的环境中,情景记忆智能体能够通过有效地在迷宫中导航,它所使用的方式是——努力通过奖励来最大化好奇心。

以下动画显示了情节记忆代理如何鼓励积极奖励(绿色)而不是奖励(红色),同时保持内存中探索位置的缓冲区(蓝色)。
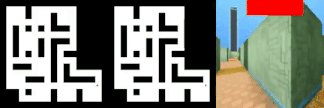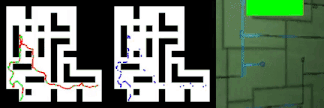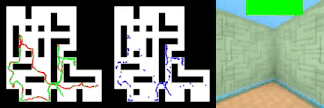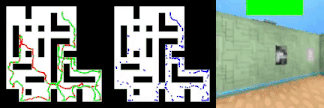
情节记忆方法是我看到的最有创意的方法之一,可以鼓励强化学习智能体的好奇心。 随着强化学习在AI系统中变得越来越普遍,诸如情景记忆的方法应该成为这些体系结构的重要组成部分。
想要继续查看该篇文章相关链接和参考文献?
点击【深度强化学习新趋势:谷歌如何把好奇心引入强化学习智能体】或长按下方地址:雷锋网雷锋网雷锋网(公众号:雷锋网)
https://ai.yanxishe.com/page/TextTranslation/1231
机器学习大礼包
限时免费/18本经典书籍/Stanford经典教材+论文
点击链接即可获取:
https://ai.yanxishe.com/page/resourceDetail/574
。









 京公网安备 11010802041100号
京公网安备 11010802041100号