作者:泱泱大国吴 | 来源:互联网 | 2023-09-25 11:06
深度强化学习笔记(一)——深度强化学习简述 前言 为什么会学习这个方向呢?现在还在放暑假,也还算有较为充裕的学习时间,所以自己暂时还有较为充裕的时间,目前就主要当作一个拓展的知识面,万一可能以后需要相关方向的研究生方向,或者其他原因,自己可以相对更快的学习。
PS:还有感觉蛮好玩的~2333
简介 强化学习(Reinforcement Learning,RL) 与深度学习都作为机器学习的一个重要方向,人工智能的一个重要目标是生成一个完全自主的智能体(agent),能够通过与环境的交互,学习最优行为。
深度学习方向更多的探索对事物的更好感知和表达,比如图像识别,目标检测,语义分割等方向。而强化学习方向擅长学习解决问题的策略。强化学习(RL)与深度学习(DL)的结合产物深度强化学习(DRL)对人工智能的重要目标迈出了更近的一步,DRL对自主系统的有更高层次的理解
强化学习发展简史 强化学习(Reinforcement Learning,RL) 历史上有三条主线,其中有两条主线有重要的历史地位。
试错学习 源于动物学习过程中的心理学,在学习过程中通过不断地尝试各种(错误或正确)行为以最终学习到最优的正确行为,即通过试错的方法进行学习 最优控制方法 使用值函数(value-function)和动态规划(Dynamic Programming,DP)的方法来解决最优控制问题,在大多数情况下不涉及学习 时间(序)差分(Temporal-Difference,TD)学习 与上两条相比,并不太明显 由同一时间内进行地连续估计之间的差异所驱动,在该方面是独特的 ,比如,棋类游戏获胜的概率1972年,Klopf提出了广义强化的概念,即每个组成部分(每个神经元)都以强化的角度看待所有输入(作为奖励的兴奋性输入,作为惩罚的抑制性输入),打算将TD学习和试错学习结合起来 1981年,提出了actor-critic 架构,也称为"行动者-评论者架构 ",现在DRL算法下,都包含在此架构下。actor 是行动者,负责动作的选择和执行,critic 是评论者,负责评价actor所选动作的好坏 上个世纪80年代后期所有这三条主线汇集在一起,产生了现代RL领域
强化学习简介 RL的本质是互动学习,即让智能体与其外界环境进行交互
智能体根据自己每次感知到的外界环境状态来选择相应的动作,以对环境进行响应,然后观测该动作造成的结果(或好或坏),并根据结果调整自身动作选择机制
RL模型中有最关键的三个部分 :
状态(state) :状态就是智能体所处坏境的、看嘛外界信息 ,外界的状态要能够准确地描述外界环境,尽可能将有效信息包含在内,要着重体现出外界环境的特征 动作(action) :动作就是智能体在感知到所处环境状态后所要采取的行为 动作的表现形式,既可以是离散的,也可以是连续的奖励(reward) :智能体感知到外界环境并采取动作后所获得的奖赏值 ,正向奖励会激励智能体趋向于学习该动作,负向奖励值则反之最优的动作顺序由环境提供的奖励决定 ,每次环境转换到新状态时,它还会向智能体提供**标量rt+1 **作为反馈。策略(控制策略)π\pi π 1 ,s2 ,…,st ,st+1 ,…},A为动作的集合A={a1 ,a2 ,…ak }。
给定状态,智能体根据策略返回要执行的动作,最优策略是最大化环境预期回报的任何策略。RL旨在解决与最优控制相同的问题,而RL是需要通过智能体通过试错学习的方法来了解在环境中采取某种动作后的所产生的结果
通过智能体与环境进行交互来感知环境,依靠策略π\pi π
在时间t,智能体从环境感知状态st ,然后使用其策略选择动作at 。一旦执行了动作,环境就会转换到下一个状态,并提供下一个状态st+1 和奖励rt+1 作为新的反馈
智能体以序列(st ,at ,st+ ,rt+1 )的形式使用状态转换的知识来学习和改进其策略
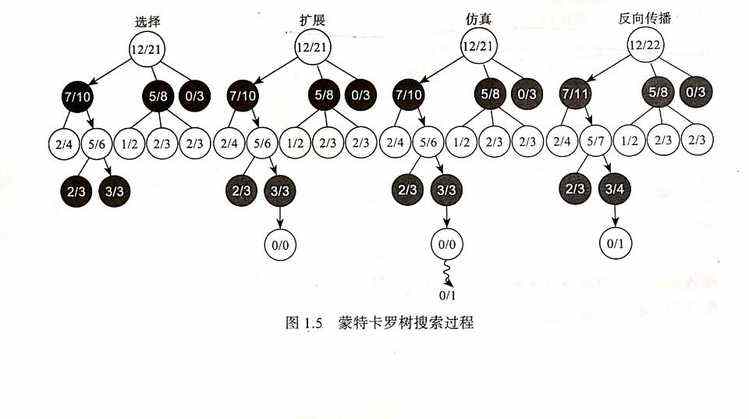
深度强化学习简介 DL方法擅长对事物的感知和表达,RL方法擅长学习解决问题的策略 ,2016年AlphaGo使用蒙特卡洛树搜索与DRL相结合的方法来打败了顶尖选手。
蒙特卡洛树搜索分为以下4个步骤:
选择:从根节点开始,选择连续的子节点向下至叶子节点。 后面给出了一种选择子节点的方法,让游戏树向最优的方向扩展扩展:除非任意一方的输赢使得游戏在叶子节点结束, 否则创建一个或多个子节点并选取其中一个子节点仿真:从选取的子节点开始 ,其随机策略进行游戏,又称为playout或rollout反向传播:使用随机游戏的结果,更新从选择的子节点到根节点的路径上的节点信息 每一个节点的内容代表胜利次数/游戏次数
目前DRL下,都在actor-critic框架下,actor-critic属于TD学习方法,其用独立的内存结构来明确地表示独立鱼值函数的策略。actor行动模块是大脑动作执行机构,输入外部的环境状态s,然后输出动作a。而critic评判模型则可被认为是大脑的价值观,根据历史信息及回馈r进行自我调整,然后对整个actor行动模块相关的更新指导
DRL目前已有:
基于值函数(value-based)的DRL 基于策略(policy-based)的DRL 基于模型(model-based)的DRL 基于分层(hierarchical-based)的DRL











 京公网安备 11010802041100号
京公网安备 11010802041100号