本文是博雅大数据学院“深度学习理论与应用课程”第八章的内容整理。我们将部分课程视频、课件和讲授稿进行发布。在线学习完整内容请登录www.cookdata.cn
深度强化学习是一种将深度学习的感知能力和强化学习的决策能力相结合,去解决复杂系统感知决策问题的人工智能方法。本次课程将主要介绍强化学习的方法论和应用场景,其中会重点讲解(1)强化学习的数据基础,即马尔可夫决策过程(Markov Decision Process, MDP);(2)求解强化学习问题的一些方法,其中包括Q Learining以及与深度学习结合的方法Deep Q Network, Policy Gradient等。
介绍强化学习前,我们先简单回顾一下之前讲解的无监督学习和有监督学习。
无监督学习 的特点是从无标签数据的样本中学习数据集的内部结构,比如生成式模型便是通过学习概率分布来生成与观测样本类似的数据点。
与之相对的是有监督学习,其样本一般是标签数据,通过形如的点对,学习从到的映射函数,一个非常典型的例子就是图像分类问题。
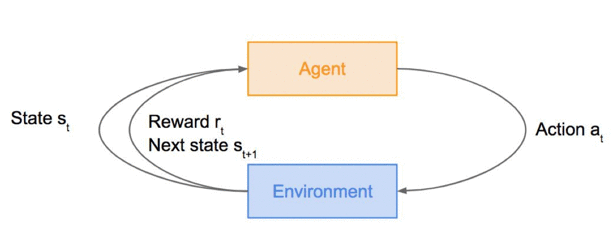
强化学习(Reinforcement Learning, RL)和上述两种方法有很大的区别。强化学习其实就是一个智能体(agent)与外部环境(environment)互动的过程,上图概括了其主要概念和框架:为了达到特定目的,agent会采取一些动作(action),记为,这些动作会影响到外部环境的状态(state),记为;State由更新为后会反馈给Agent一个奖励(reward),记为,去评价当前动作的执行效果。
例如在自动驾驶的系统中,我们的最终目的是希望汽车能够平稳地驾驶。智能体需要根据观察到的当前路况,去对环境执行方向盘向左打或向右打的动作。如果在行驶过程中没有任何撞车,反馈的奖励便会更高。
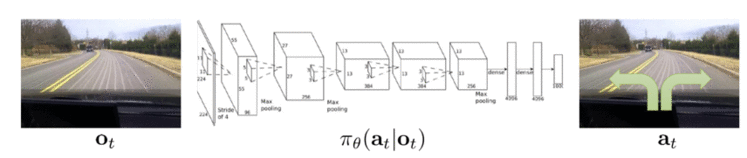
由上述框架可以看出,“如何采取action来最大化reward”是强化学习的核心问题。一般完成一个目标,agent需要执行一系列的动作,我们称这样的问题为序列决策(sequential decision making)。以机器人走路为例,机器人在当前位置,如何一步一步完成开门并走出屋子的任务,这便是一个序列决策。

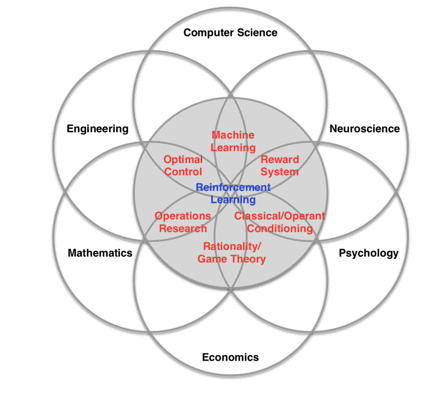
因为涉及到了决策,强化学习往往会参与到多学科交叉的主题中(见下图),比如在数学和经济学的交叉领域中会涉及到许多经济政策与股票交易的决策问题,在工程学和神经科学里会应用到机器人控制与人脑研究等等。
综上所述,强化学习的显著特点包括:
除了上文提及的智能体、奖励、环境 等元素外,强化学习还有一些其它基本概念:
 经验 (Experience)可以理解成一个观察、动作、奖励不断重复的轨迹图,而状态 (state)是对这些经验的一个函数总结和特征提取。
经验 (Experience)可以理解成一个观察、动作、奖励不断重复的轨迹图,而状态 (state)是对这些经验的一个函数总结和特征提取。
状态可以进一步区分成智能体状态 ()与环境状态 ():
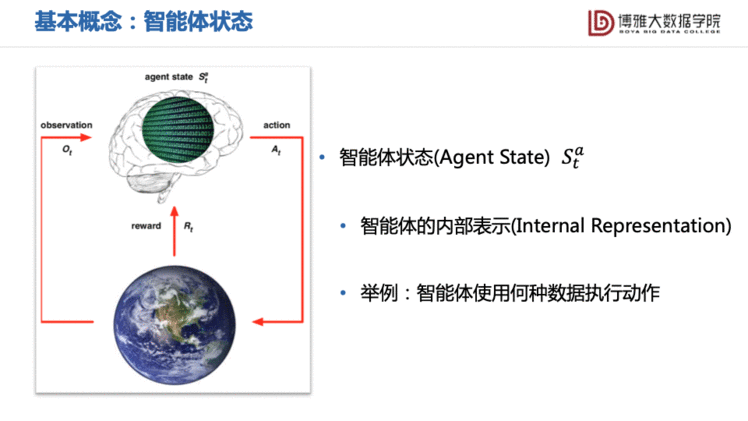
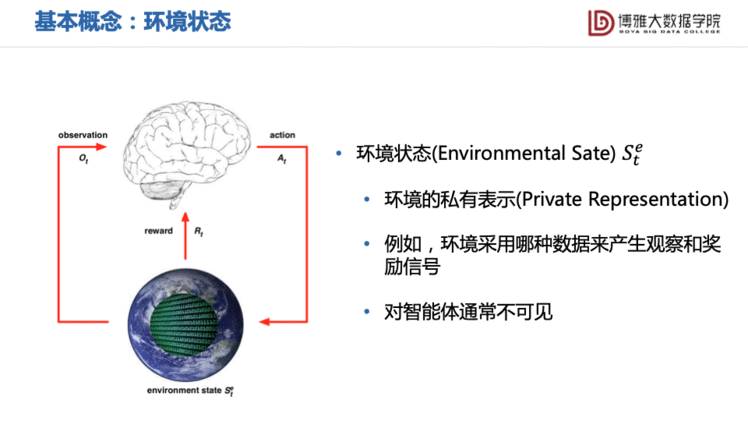
需要指出的是,环境状态对智能体通常不可见。例如一个机器人A推倒另一机器人B,机器人A是看不到机器人B内部的状态变化的。
下面我们介绍完全可观察(fully observability)和部分可观察(partially observability)的概念:


在完全可观察环境中,所有元素的状态都是共享信息的。这也是标准马尔可夫决策过程MDP的基本条件。
部分可观察环境的一个直观例子是安装有摄像头的机器人,由于遮挡带来的盲区,机器人观察不到环境状态的全部信息;另一个例子是在金融市场中,每个人都无法获知其他人的交易信息,而只能看到当前价格。这样的马尔可夫决策过程被称为Partially Observable MDP。
一个强化学习智能体由以下部分组成:
策略 (Policy),简单说就是从状态到动作的一个映射,分为确定性(Deterministic)策略
和随机性(Stochastic)策略,即动作服从一个概率分布:值函数 (Value Function),是对未来奖励的一种预测,即在状态下,预测智能体执行动作能获得多少奖励。
具体而论,值函数有很多形式,如状态价值函数和状态-动作价值函数。状态价值函数 指在策略下,从状态开始获得的所有奖励的期望:
其中为给定的折扣因子。引入折扣因子是因为,我们只假设对步的预测比较准确,但是对未来的步的预测就会产生偏差,所以每往后预测一步便乘以一个区间里的数进行“折现”,比如0.99、0.999这样的数,使得我们越往后的预测被“折现”得越厉害。
状态-动作价值函数 也称作Q-value Function。它代表在策略下,从状态以及动作开始获得的所有奖励的期望:
在此基础上提出的最优值函数 的意义就很显然了,即找到最优策略下的值函数。如果得到了最优值函数,我们便可以选择使最优值函数最大的动作来获得最大的未来奖励——这便是Reinforcement Learning的目的。
模型 (Model),就是预测环境下一步要做什么。我们首先得到在当前状态,智能体做了动作,下一步状态的概率分布是什么样的,接着我们求出这个动作对应的Reward的期望:
有了这样一个Model之后,为了要达到特定的目的,往往会对生成的树用前向搜索(Lookahead search)做个规划,就可以收敛到最优的策略。

用迷宫游戏举个简单的例子。每个time/step的奖励为-1,表示多花了一步走出迷宫;动作为向上下左右移动;状态是每个智能体的实际位置。在每个状态的策略是向哪个方向移动;值函数便是执行策略的Reward的期望。可以看出,在走到最后一步时,数值会比较大;而走到一些“死胡同”的位置,值函数会比较小,也就意味着比较难走出去。所以值函数是评估当前状态的一个非常有意义的量。这里的模型是一个网格分布。
篇幅有限,我们会在后文重点介绍前两种。
深度强化学习(Deep Reinforcement Learning)是指使用深度神经网络来表示值函数/策略/模型,并使用随机梯度下降(Stochastic Gradient Descent, SGD)算法优化损失函数的方法。
马尔可夫决策过程描述了强化学习的(完全可观察)环境,几乎所有的强化学习问题都可以转化为MDP,部分可观察环境问题也可转化为MDP。我们将由简单到复杂逐步地讲解马尔可夫决策过程:

马尔可夫过程 是一种不带记忆的随机过程,即马尔可夫过程是一个符合马尔可夫假设
的元组,其中是一个状态的有限集合,是状态转移概率矩阵(state transition matrix),表示从当前状态到其后继状态的转移概率。
时间和状态都是离散的马尔可夫过程称为马尔可夫链(markov chain)。
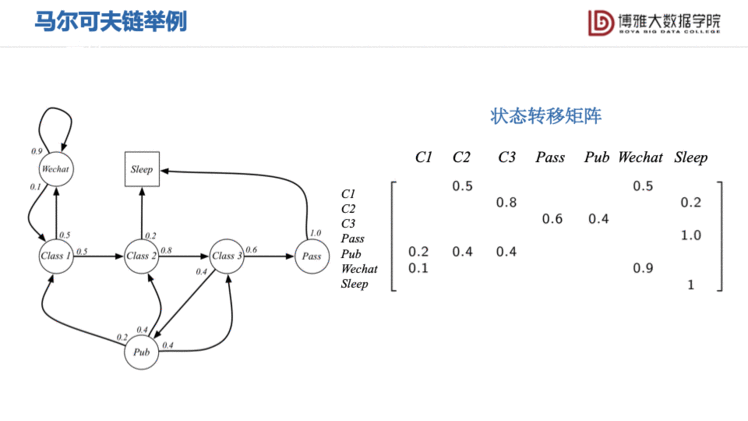
上图是大学生一天日常生活的马尔可夫链模型。可以看到,“玩微信”这一状态转移到自身的概率为0.9,表达了刷微信停不下来的行为模式。
马尔可夫奖励过程 (Markov Reward Process,MRP)其实就是给马尔可夫链的每一个状态加一个奖励函数(Reward function)和折扣因子(discount factor)。
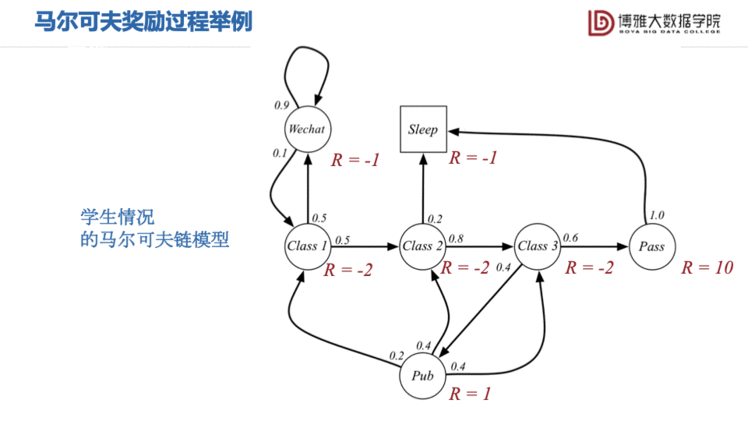
还是拿刚才大学生的日常生活举例。这里的Reward表达了学生的高兴程度,我们可以看出“考试通过”这件事是最让人开心的。
在这个马尔可夫奖励过程MRP里有一个回报(return) 的概念,是指从时间步(time step) 开始的所有的折扣奖励
同样,这里的折扣因子可以表示未来奖励(future reward)的折现。
那么自然地,MRP中也有了值函数 的概念,表示从状态开始的回报期望值。
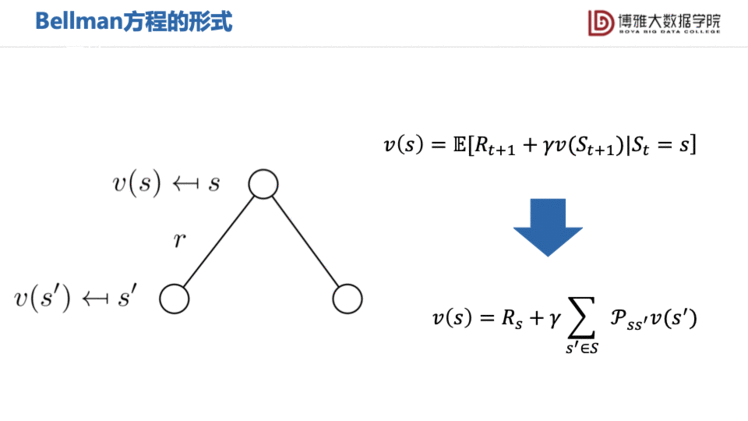
MRP的值函数可以分解为两部分:瞬时奖励(Immediate Reward) 和后继状态(Successor State)的折扣值 ,即Bellman方程,这一方程其实就是描述相邻两个时刻的值函数的关系。
上述值函数关于时间的迭代式对于强化学习问题来说非常重要,一般来说必须要满足Bellman方程。
马尔可夫决策过程 (Markov Decision Process, MDP),是一个带有决策(decision)的马尔可夫奖励过程(MRP),其所有的状态都是马尔可夫状态的环境(environment)。
从数学上来说,马尔可决策过程是一个元组,其中是一个状态的有限集合,是状态转移概率矩阵,是动作的有限集合,是奖励函数(Reward Function),是折扣因子(Discount Factor)。所以模型可以表述为
引入MDP的Policy 后,模型修改为

MDP的值函数定义也很直观:

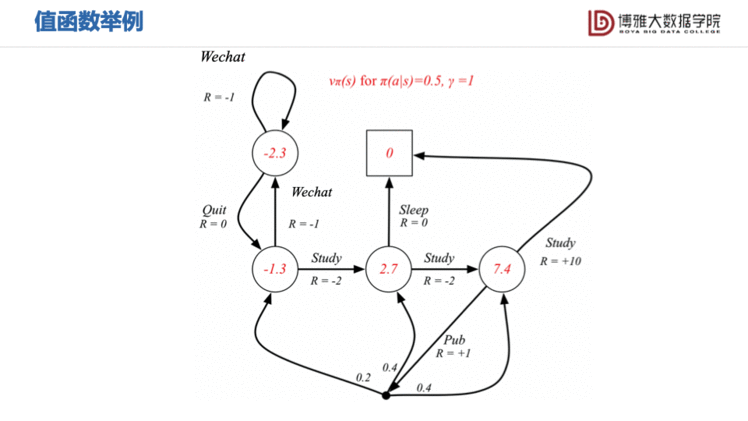 我们可以看出从出发,虽然去study的动作的依旧是-2,但其未来回报的期望值上升到了2.7。
我们可以看出从出发,虽然去study的动作的依旧是-2,但其未来回报的期望值上升到了2.7。
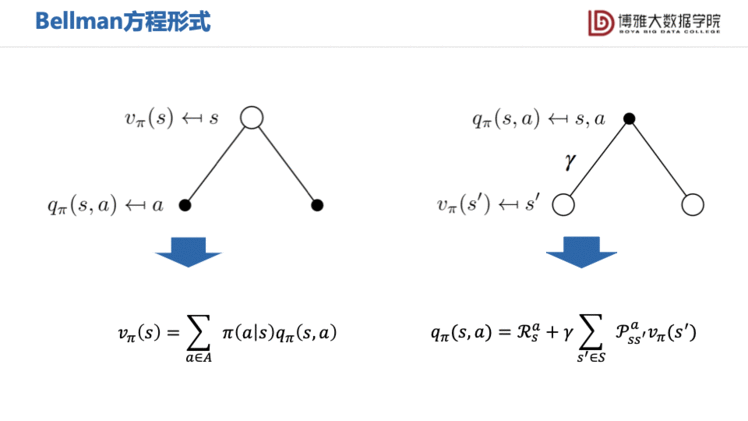
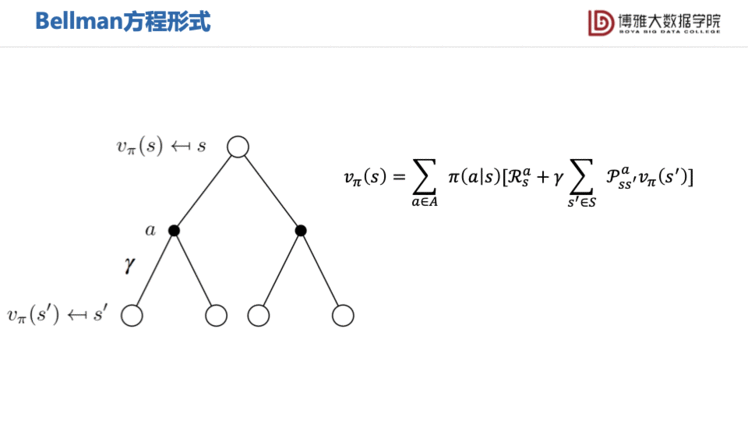
与MRP相同,我们也可以写出MDP的Bellman方程。MDP的状态值函数仍然可以分为两部分
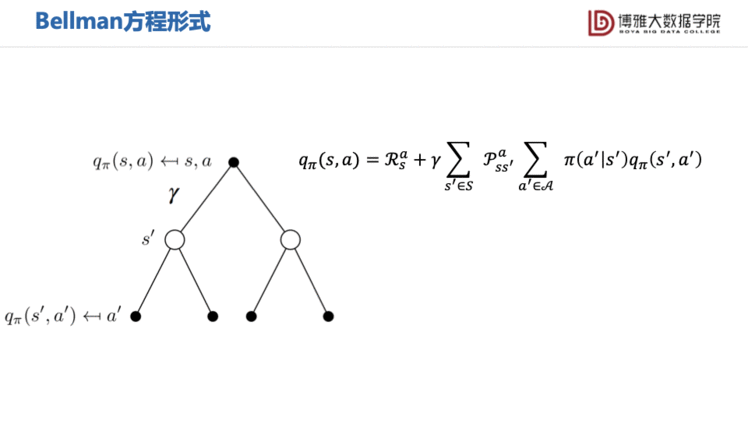
动作值函数也可以分为两部分
自然地,可以定义MDP的最优状态值函数
和最优动作值函数
通过最优状态值函数,我们可以定义不同策略之间的偏序(Partial Order)规则:
定理 对于任意一个马尔可夫决策过程,存在最优策略,使得
这个定理告诉我们,将问题建模成MDP是可解的,强化学习问题必然会存在最优解。
通过最大化,最优策略可以表示为
对于任意的马尔可夫决策过程来说,总能找到确定性最优策略。所以如果我们知道了,问题便解决了,这给出了一种求解RL问题的方法——想办法把求出来,我们在后文会提到。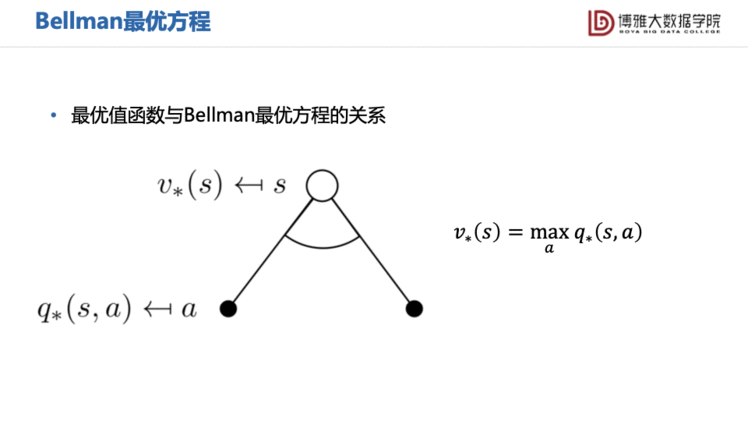
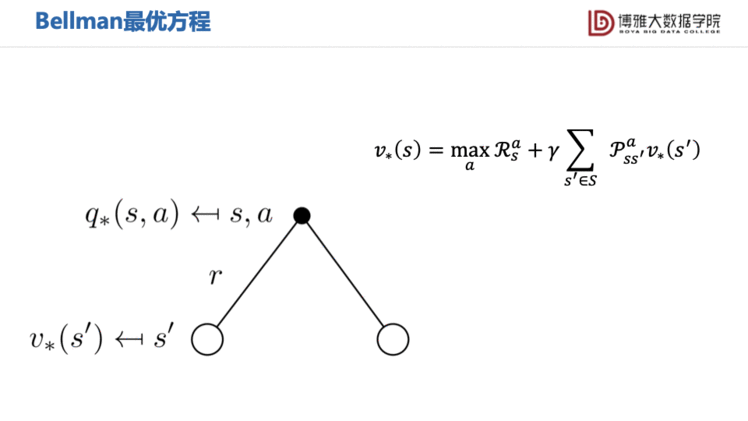
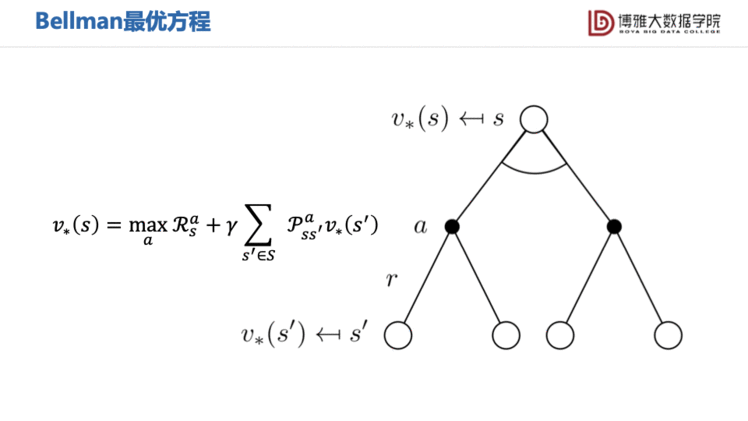
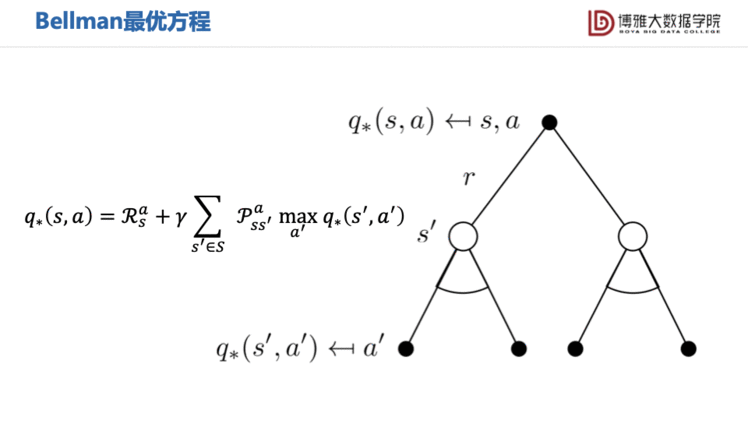
通过最优值函数,我们可以得到Bellman最优方程。
Bellman最优方程是非线性的,通常来说没有闭式解(Closed Form)。所以Bellman方程的求解可以使用迭代方法:
在这里,我们重点介绍一下Q-Learning,一种Valued Based深度强化学习的方法。
我们先来回顾一下上文定义的状态-动作价值函数,给定折扣因子(Discount Factor) ,
它代表在策略 下,从状态以及动作开始获得的所有奖励的期望。那么我们如何去优化它呢?
我们以最简单的离散情况为例。在离散的情况下,Q值相当于一个表,每一行是不同的State,每一列是不同的Action,每一个点的值便是在当前State,执行这一列Action的Q值。所以每次选择最优Action执行的时候,我们只需要在每一行里找到使得Q值最大的Action就可以了,这便是Q-learning的关键。
接下来,问题就变成了如何去求解这个Q值。因为Q值必须满足Bellman方程,所以我们可以移项再平方,构造目标函数。
有了目标函数后,我们如何去更新、优化这个函数呢?Q learning的算法就是直接求导,用梯度迭代计算Q值。具体的算法详见下图

这里为了避免陷入局部最优,实际中往往使用greedy,以一个非常小的概率去随机探索别的状态,增加对整个空间的遍历、探索。
接下来我们来讲解用Deep Learning怎么做RL问题。
Q learning是一个简单可行的算法,但有一个致命的问题是,如果State或Action特别多,那么Q表会特别大,算法中更新迭代就会非常慢,可能非常难以收敛。
所以Deep Q Network(DQN)用一个神经网络来模拟这些Q值(见下图)。这个神经网络的输入是当前的State,输出一共是m个动作的Q值。我们需要优化地就变成了神经网络的参数。
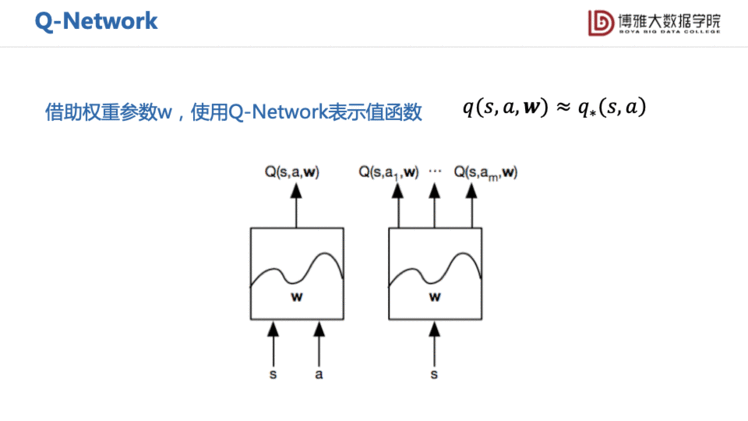
DQN的基本思路和Q learning很像,也是去更新同样的目标函数。为了去除序列数据间的相关性,DQN的数据来自于智能体自己缓冲区的历史数据,每次从中随机采样经验。为了解决相关性比较高、不平稳性,一般会固定求解参数一段时间后再进行更新。

下图展示了DQN的算法实现,同样也在每次迭代的开始用了greedy,可以看到仿真器产生的新状态如上文所述,存储在缓存区里,用于之后的随机采样更新。

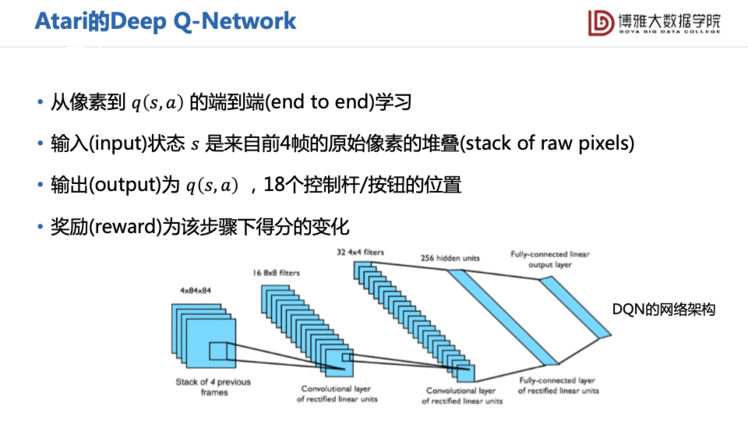
在最初DeepMind发表在Nature上的这篇文章里,应用场景是Atari游戏。
它的输入就是时间相邻的前后4帧图像,输出是18个动作(控制杆的位置)的Q值。网络当初是非常简单的,只是选取了一些最简单的两三层卷积神经网络,加两个全连接层来求Q值和更新参数。
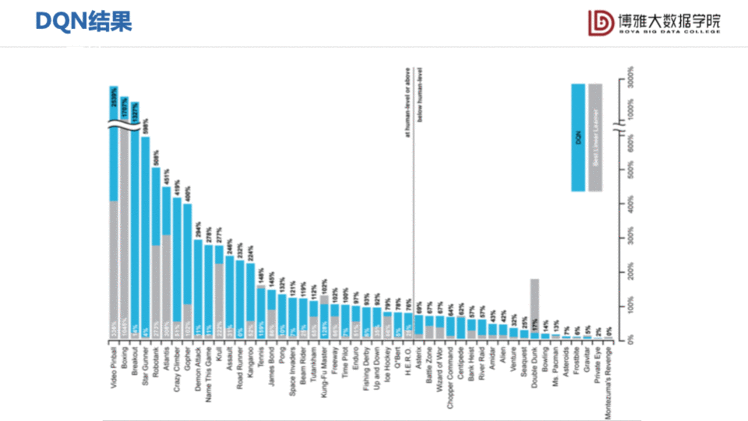
从下图可以看出,这个算法在不同Atari游戏中都能玩的很好,可以达到和人类玩家差不多的水平,甚至有的时候比人的水平还要高。
当然,后续还有很多对DQN的一些改进。可以对目标函数进行优化来移除向上偏误(upward bias),

也可以对存储历史数据的缓存区进行优化,将比较差的经验放入一个优先队列去优先更新它,可以增加效率。

也可以采用对抗网络,将网络分为两个通道,一个是独立于动作的值函数,一个是依赖于动作的优势函数。

之前的DQN系列算法均为Value Based强化学习方法,主要对值函数进行近似表示,引入动作值函数,其由参数描述,并接受状态与动作作为输入,计算后得到近似动作值函数:
而在Policy Based强化学习方法下,采用同样的思路,但是选择对策略进行近似表示。此时策略可以被描述为一个包含参数的函数,即策略函数:
Deep Policy Network直接用Deep Network去参数化表示Policy;把执行策略的期望回报作为RL的目标;为了求解这个目标函数的最大值,我们使用随机梯度算法。我们称这样的算法为策略梯度 (Policy Gradient)。

策略梯度法的优势主要在于其在很多的模型里表现稳定,尤其是连续控制的场景,比如机器人控制的问题往往还是Policy Gradient的方法做的好一点。

Policy Gradient具体是如何实现的呢?注意这里目标函数中的表示使用策略进行交互得到的一条轨迹。

在求解梯度的时候我们用到一个小技巧,将其转换为对的梯度求解问题。
因为梯度公式里有一个非常复杂的期望,不可能给出闭式解,所以我们采用蒙特卡洛估计,采样多个轨迹求平均来估计梯度。

策略梯度算法的求解从下图的角度看,与之前我们讲过的有监督学习求解过程有些类似。

这个算法里还可以有一些小小的改进。因为在策略梯度算法中梯度公式的回报值总和是从开始求和的,但由马尔可夫性质我们知道,从当前时刻开始的决策和前面的回报都无关,所以我们实际的更新中可以把之前的回报都省掉。

这个算法里还有一个很重要的问题是方差,尤其是当轨迹特别长的时候,如果要达到一个非常准确的梯度估计,往往需要非常多的轨迹,这时候的计算代价就会过高,导致估计方差会比较大。所以为了降低方差,比较常用的方法是Actor-Critic算法。它的特点是用一个独立的模型来估计未来回报,而不再用轨迹的真实回报。

这里的Actor指策略函数,负责生成动作与环境交互,学习一个策略来得到尽量高的回报;而Critic指值函数,对当前策略的值函数进行估计,即评估Actor的好坏,并指导Actor下一阶段的动作。
这样可以实现单步更新参数,不需要等回合结束再进行更新。Actor-Critic算法本质上相当于是有两个network,一个是Actor去学习Policy,另一个是值函数,算法把值函数和策略梯度很好地结合在一起去同时学习。

Actor-Critic算法里要做两组近似:一个是对策略函数用神经网络做一个近似;另一个是用神经网络近似值函数。

最后用TD-Error来估计轨迹的回报

因为可以单步更新,所以AC算法运算起来会比较快。但是有时候也出现一些难收敛的情况,所以后面DeepMind也提出了一些新的改进,让它收敛更快。

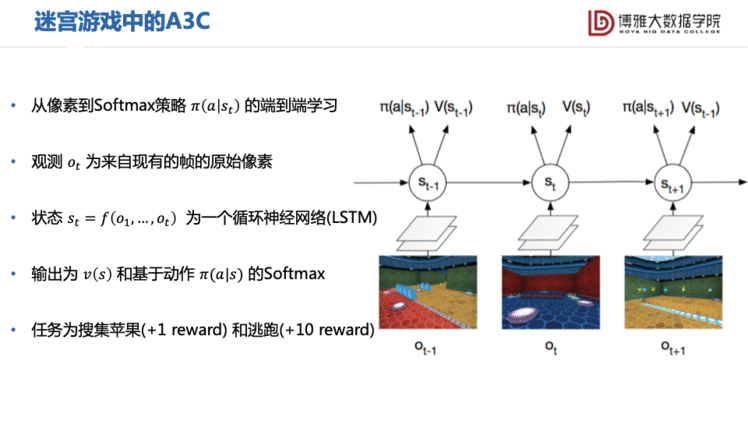
另一个改进AC框架的算法是A3C。这个算法主要是从加快计算的速度、提高学习效率的角度改进。A3C采取了多个并行的环境,利用分布式计算,每个环境里都有一个智能体执行各自动作,然后我们去汇总这个动作去降低方差。

在此基础上,我们可以用A3C去做一些迷宫游戏。因为迷宫中玩家需要不停地走,所以这是个序列问题,我们用LSTM网络来学习从观测到状态之间的编码。至于其它的如Policy和值函数,都是用神经网络的思路(卷积神经网络)来做的。大家有兴趣可以看看这个demo。
Model Based的强化学习其实只需要我们知道环境的模型,以及如何去进行规划,下棋便是经典的例子。但是往往虽然我们知道模型,但是进行规划时往往存在搜索代价特别昂贵的问题。围棋是19×19的格子,如果搜索步数特别深的话,这个计算量是难以承受的。
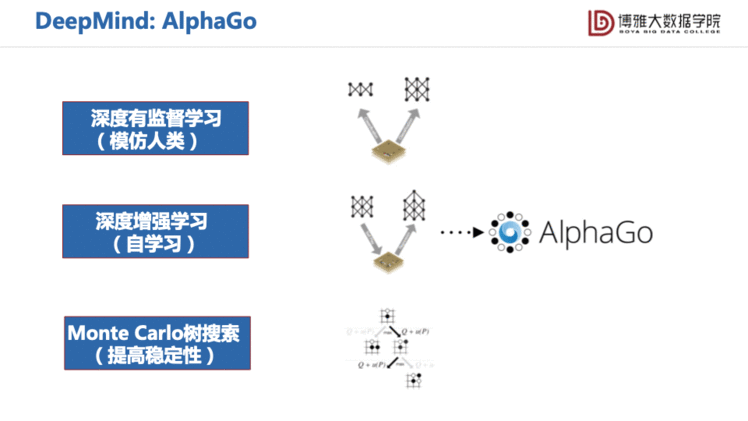
AlphaGo中第一次尝试把强化学习的思路引入到基于搜索的方法中,大大避免了搜索时过深过宽的问题。我们称这种规划为蒙特卡洛树搜索,也就是下图中所写的tree search。AlphaGo就是用深度学习的方法去估计每一时刻的状态的价值是多大,帮助去剪枝原本很庞大的搜索。
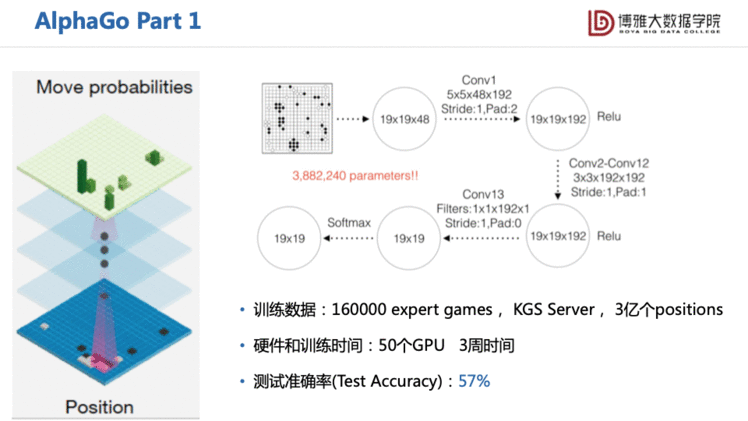
最初第一版的AlphaGo由三部分组成。第一部分是模仿人类,它搜集了大量的7段以上高手的对弈记录,用最朴素的有监督学习,训练数据是当前棋盘状态和下一步落子的数据对,构建一个CNN模型,相当于19×19的381分类问题。但是在学习了这个之后,AlphaGo只能赢一些非常普通的选手,于是它的第二部分就用此基础做初始化,再训练一个Policy Network、 Value Network的深度增强学习,来指导第三部分的蒙特卡罗树搜索。
我们可以看到,第一部分的有监督学习中的棋盘状态提取了19×19×48个特征。可能大家会好奇这个48的维度是从哪来的?其实他就是根据围棋的一些构造,比如说这个位置是白子、黑子还是空?这个位置是不是边缘或者天眼?这个位置是不是已经被围住了,不能被下了。它根据这些围棋的规则整理出这样一个48维的特征。接下来它用了一些gpu去训练,做了两三次的卷积网络,最后输出。所以可以明显看到在这一过程中AlphaGo是不涉及到序列决策的。
在第二部分AlphaGo用了深度强化学习的思想,同时用Policy Network和Value Network去估计权重,有些类似AC算法的思路。
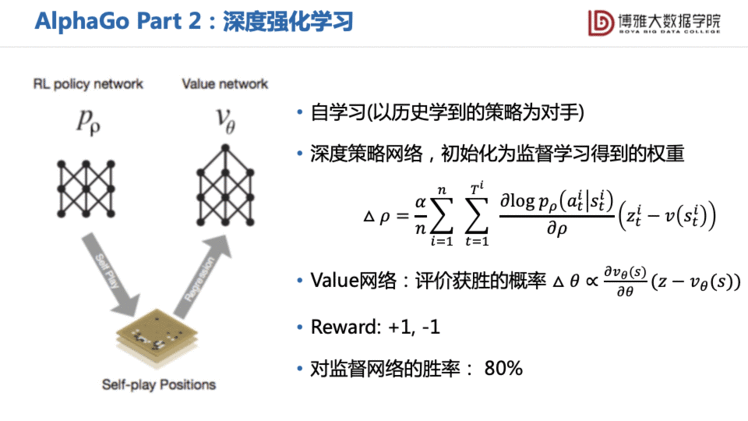
最后在决策落子的时候,AlphaGo就将刚刚深度强化学习学到的信息与树搜索结合。第二部分中的网络给每个位置一个关于胜率的值,所以在搜索中我们可以只搜那些值比较大的分支,大大减少了蒙特卡洛搜索的代价。
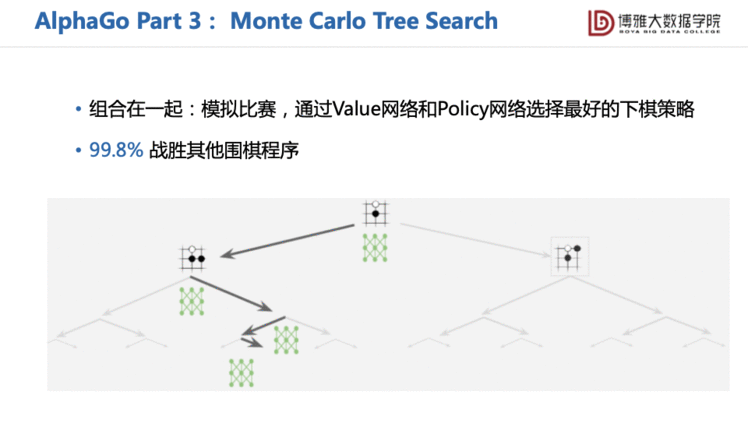
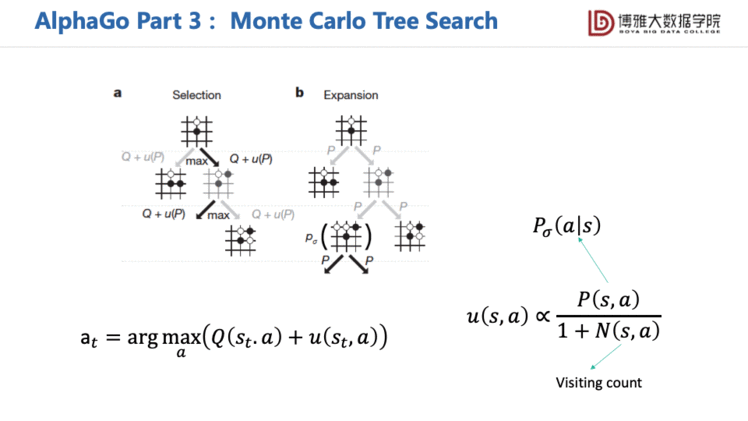
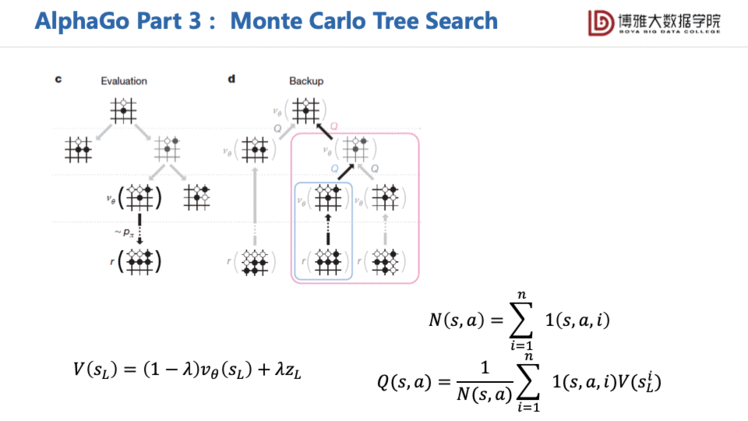
后来的AlphaGo Zero是一个更强的版本。它放弃使用了人类的专家数据了,只依赖强化学习,将特征提取的网络改用ResNet。其实没有改变太多,但是它用了一个很好的网络结构,并且增强了计算量,所以取得了更好的效果,基本上打败了目前所有的传统媒体程序,人类棋手基本上也是没有办法去和它抗衡的。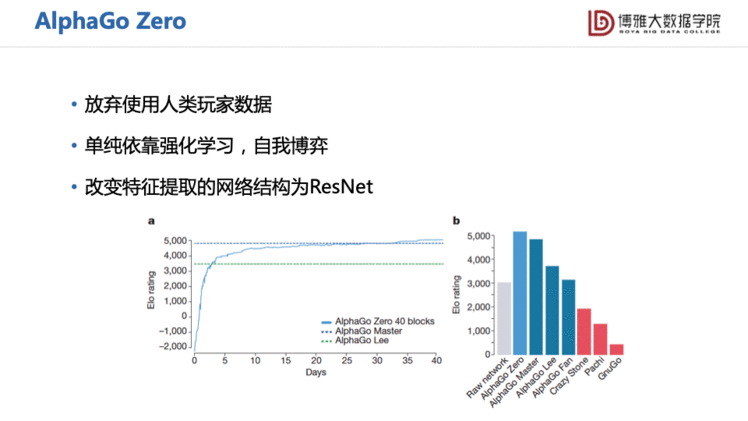
深度学习的完整课程视频、课件、案例、数据以及题库等资源,请登录数据酷客平台(www.cookdata.cn)。
深度学习理论与应用
深度学习理论与应用第2课:机器学习基础
深度学习理论与应用第3课:深度前馈神经网络
深度学习理论与应用第4课:深度学习中的优化方法及正则化
深度学习理论与应用第5课:卷积神经网络
深度学习理论与应用第6课:序列模型
深度学习理论与应用第7课:深度生成模型










 京公网安备 11010802041100号 | 京ICP备19059560号-4 | PHP1.CN 第一PHP社区 版权所有
京公网安备 11010802041100号 | 京ICP备19059560号-4 | PHP1.CN 第一PHP社区 版权所有