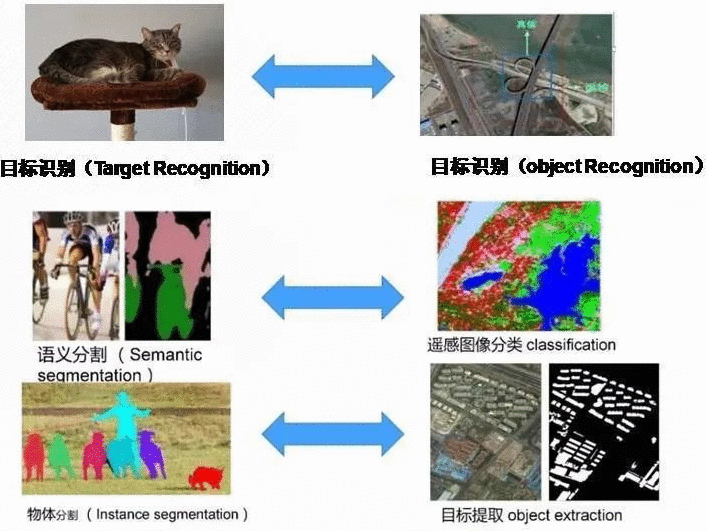
侧重于检测,遥感分析什么什么的

1.自动翻译技术精度低,
2.应用场景多样性,
3.深度学习缺陷(目标检测的攻击和防守,决策过程难以控制)对抗样本等问题

1.2012年的语音识别与图像识别(学习猫的行为)
2. 2012年的微软全自动同声传译系统,关键技术(DNN)也可以叫深度学习
3. 2018年,深度学习不仅仅在工业领域发展迅速,在图灵奖中也获得成绩。



1.图像识别
2.语音识别
3.自然语言理解
4.天气预测
5.基因表达
6.内容推荐
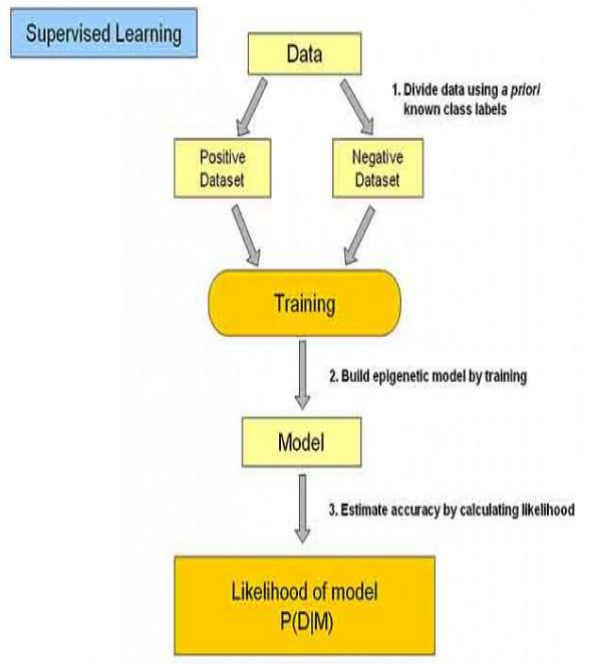
获取数据——》预处理——》特征提取——》特征选择——》预测,识别
典型的过程:输入数据,评估函数(函数可以对没有见过的新数据给一个新的评估,构建一个模型)
评估过程问题(评估一辆车,四个***,一个车体,但是,四个***一个车体不一定是车,所以特征的选取很重要,那么,如何特征选择,是一个很难的问题,我们需要进行一个思考)
1.经典定义:利用经验改善系统自身的性能
(经验就是一种特征的筛选,获得的)
2.举例:有一堆瓜,对他的特征收集,判断,选择模型,训练样本,判断是否一个好瓜
损失函数:评估我们当前模型的评估结果,选择合适的参数,减少误差,得到准确的模型
目标函数:最终的模型
首先,一些数据(训练集)

画出图发现复合线性模型



1.了解特征
2。明白目标
为了让L(w,b)最小
3.求偏导
4.写代码

5.梯度下降算法
由于上述的箭头地方不好理解,数据的多的话就不行,换了另一种算法——梯度下降算法

6.梯度下降算法的代码

问题:超参数难以设置
参数的设定会影响误差,参数的变化

1 2可能需要增加迭代次数
也可以改变学习率:
1,就学习率不行
如果数据error变化左右来回,那么学习率太大,如果变化太小,那么就是学习率太小
(我们现在的数据是不符合实际的,是唯一大坑的数据,梯度下降的时候局部最优一次迭代就可以进入整体最优,而有的数据是大波浪线,有小坑,所以可能进入小坑后就判断为最优化,所以学习率选择靠经验很重要)一般为0.001~0.003
平衡一个样本的不足,考虑了算法的不足
增加参数

发现损失函数值太大了,过拟合,所以我们的模型不是最优的(梯度下降算法还是目标函数存在的问题),判断发现参数,学习率,迭代次数,损失函数都没有问题(严格按照正常流程进行),所以就是目标函数出现问题,所以模型选择存在问题,把不应该选择线性模型
机器学习不仅可以使用原有特征,还可以根据已有特征进行创造特征,比如男,二十岁,可以创造一个二十岁的男性这一特征,如下,我们不只有x还可以创造出x的次方,三次等等
增加特征以后,那么x的次方哪个最好呢?二次?三次?

尽可能选择参数合适,有好拟合的模型
1.过拟合












 京公网安备 11010802041100号 | 京ICP备19059560号-4 | PHP1.CN 第一PHP社区 版权所有
京公网安备 11010802041100号 | 京ICP备19059560号-4 | PHP1.CN 第一PHP社区 版权所有