作者:王言 | 来源:互联网 | 2023-05-16 07:31
本文主要分享【mongodb数据库基本操作】,技术文章【MongoDB数据接入实践】为【Thoughtworks思特沃克中国】投稿,如果你遇到Data相关问题,本文相关知识或能到你。mongodb数
本文主要分享【mongodb数据库基本操作】,技术文章【MongoDB数据接入实践】为【Thoughtworks思特沃克中国】投稿,如果你遇到Data相关问题,本文相关知识或能到你。
mongodb数据库基本操作
把数据导入数据平台是挖掘数据价值的第一步,如果做不好,数据分析将收到很大影响。所以,快速、高质量、稳定的将数据从业务系统接入到数据平台是至关重要的一环。
数据平台最常见的一个数据源是关系型的数据库,然而随着软件技术的发展,越来越多的业务系统基于非关系型数据库开发,所以,非关系型数据库的数据接入时数据平台必备的能力之一。
我们的数据仓库基于Hive构建,Hive的设计可以很好的兼容关系型数据库,如果数据源是关系型数据库,数据接入会相对容易。如何从非关系型数据库中接入数据呢?这里面有没有什么经验值得分享呢?
我们项目最近就碰到这种情况,需要接入一个业务数据库的数据,这些数据存储在MongoDB中。本文将就非关系型数据库接入数据平台分享一些我们实践中的一些故事和经验。
MongoDB的特点

先了解一下MongoDB的特点。MongoDB是一个流行的文档型数据库,内部的一条数据也称为一个文档。MongoDB是NoSQL数据库的一个典型代表,与关系型数据库相比,有如下特点:
支持嵌套类型的字段,比如数组类型字段、字典类型字段,其中字典下又可以嵌套其他字典或数组;非常容易的添加新字段,添加字段时,如果旧数据只需要有一个默认值,则无需数据迁移,在程序中设置默认值即可;可自动生成带排序特性的ID;通过对ID进行hash,可以很容易的支持分布式扩展;多文档、多表间的事务一致性不容易保证。
从上面的分析可以看出,作为NoSQL数据库的代表,MongoDB在易用性上有不错的优势,它支持更广泛的数据结构,扩展起来非常方便。这些大概是它得以流行的原因。
使用Spark读取MongoDB数据
如何将MongoDB的数据接入Hive呢?经过上面的分析可知,我们首先要解决的问题就是数据在Hive中要以什么样的结构存储的问题。
查阅Hive的文档可以知道,Hive其实也可以支持嵌套的数据结构。Hive的某一个字段可以是数组类型或Map类型,Map下也可以嵌套Map或数组。这是一个非常有吸引力的特性,看起来与MongoDB支持的数据结构可以进行无缝转换。
在项目中,我们也首先进行了这样的尝试,将MongoDB的Spark连接器jar包加入到Spark的classpath下就可以使用Spark读取MongoDB的数据了。
数据类型问题
我们的数据源中最复杂的一张表有大约100个字段,超过1000w数据量。事实上,在读取这张表时却不尽如人意,程序总是运行到一定的时候就报错java.lang.IllegalArgumentException: Can’t parse category at …,看起来是由于Spark不能正确的将读取到的数据解析到之前预设的结构上。
经过一番研究之后,我们了解到,如果使用Spark的DataFrame API读取数据,在读之前就需要指定数据类型。MongoDB的数据类型如何确定呢?查阅MongoDB的文档可知,这是通过以下步骤完成的:
Spark连接器会先进行文档抽样;解析每个抽样文档可以得到一系列的文档结构;合并所有的结构得到来组合成为一个最终结构。
到这里,上面的错误就很清楚了。抽样结果不会覆盖到所有文档,一旦有某一个文档的结构不能兼容抽样得到的结构,Spark程序就会出错。
如何修复这个错误呢?我们可以提高抽样比例,但是这样一来,有几个可能的副作用:
数据读取过程更慢;给业务系统数据库造成更大的压力;新数据如果使用了更新的结构依然可能报错。
虽然不是一个好的方案,我们还是进行了尝试,毕竟改个参数没什么成本。然而,在尝试了多组抽样率参数也没有带来很好的效果。
探索其他方案
看起来我们低估了从MongoDB进行数据接入的难度啊。
如何解决这个问题呢?有两个办法可以继续尝试:
将错误数据反馈给业务系统,以便从源头解决问题;读数据时忽略出错的数据。
第一个方案不是一个好的方案,因为会引入额外的人工流程,数据接入没法自动化稳定的完成。这将带来巨大的维护成本,可以想象,我们需要隔三差五的找业务系统的开发团队反馈问题,等他们问题修复了,我们再重新接入数据。不仅人力成本协作成本都很高,而且想要每天稳定的输出指标基本上不可能了,随机的数据接入失败会导致随机的指标输出失败。
第二个方案我们也调研了一段时间,然而结论是需要修改MongoDB的Spark连接器才能实现。这里并没有一个相关参数可以让我们忽略读取数据过程中的错误!
这时,MongoDB的数据接入几乎陷入僵局。上面这个问题实际上更为严重,因为被我们捕捉到的只是一个特例,类似的错误可能还很多,比如Spark读取到的结构显示某一个字段应该是数字,但却读取到了一个字符串,或者显示是数组的却读取到了一个字典等等。这样的数据类型不匹配的情况实在太多了,几乎无法穷举。这就让这种方式存在极大的不确定性。
使用ELT的方式读取MongoDB数据
如何解决这个棘手的问题呢?讨论了很久,最后我们转换了一下思路。在大数据下进行数据处理时,除了大家都非常熟悉的ETL,不是还有一种实践是ELT么?我们能不能这样做呢:
在接入时直接保存原始文档不进行schema解析;在使用数据时根据需要进行解析。
这正是ELT的数据处理方式,先extract提取数据,然后并不进行transform操作,而是直接通过load将数据存下来,最后在使用数据时执行transform解析数据。
MongoDB作为一款成熟的数据库,数据读取应该不是难事,我们可以使用python将数据读取出来存为json文件(实际上是按行存储的json文件,每行对应一条json格式的数据),然后用Spark读取文件写入到Hive。
日期数据问题
使用pymongo客户端库,可以用python读取MongoDB的数据。我们一开始以为这样的方案应该可以很顺利的完成。没想到还是有一些意外。在读完数百万的数据之后,突然程序报错,日期无法解析,错误消息类似bson.errors.InvalidBSON: year 20215 is out of range。很奇怪的错误,有一个错误的日期成功的写入了MongoDB,但是无法正确读取。
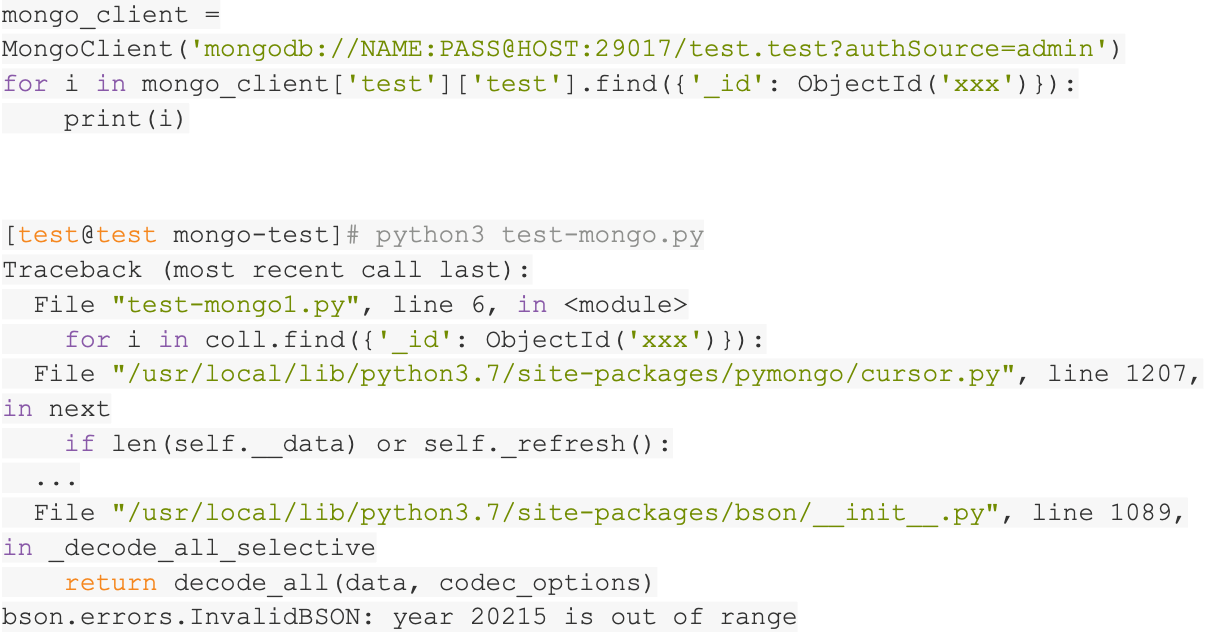
我们尝试把出问题的数据找出来看看。使用MongoDB的cli工具连接数据库,可以执行查询。但是由于错误信息很少,我们花费了一番工夫才真正找到出问题的数据。原来是这个字段存储的不是业务合法的日期,而是一个错误日期!

经过一番调查,有了结论,原来使用java客户端可以成功将此类日期写入MongoDB,因为在java中这个日期是一个合法的日期。MongoDB使用bson格式进行数据存储,同样可以合法的存储此类日期。但是python无法读取此日期,因为python读取到bson的date之后,会将其转化为python的datetime对象,而python的datetime要求year值必须在1到9999之间。
尝试解决日期数据问题
MongoDB的数据接入之路真是有点曲折。如何解决这个问题呢?我们可以循环读取数据,捕捉这类异常,然后跳过异常数据继续往下读取。
于是我们编写如下代码,在遇到错误的时候打印对应的错误文档id,然后继续。

在满以为可以正常运行的时候,又遇到了新的问题。在MongoDB的客户端里可以根据错误文档的id查询到该文档,可是当我们去查看该文档的时候,却并没有发现错误的数据。该文档对应的数据是正常的!这是为什么???
再次尝试解决日期数据问题
没办法了,只能研究研究pymongo库的源代码了。仔细读了一下API的参数,发现一个可疑的地方,读取数据的API里面有一个参数batch_size,默认值情况将返回不多于101个文档或1MB的数据大小。这么说来,pymongo在读取数据的时候是批量读取的,这应该可以提升不少性能。在读取到一批数据之后,pymongo会开始进行数据解析,转化为python的数据结构,此时如果这一批数据中某一条数据有问题,则会触发异常。原来如此,所以我们之前打印的错误文档的id并不是真正的错误文档的id,而是该批次文档的第一个文档的id!
有了这个认识,我们可以使用如下流程来读取数据:
用较大批次读取数据;在遇到错误的时候,将批次大小改为1,并跳过错误的文档;将批次大小改回原来的值继续读取其他文档。
参考代码如下:

经过了重重困难之后,终于可以比较稳定的读取MongoDB数据接入了。
其他优化
后续的工作中,我们将错误的文档记录了下来,这可以反馈给业务系统开发人员进行修复。
我们还发现了数据读取超时的问题,这个可以通过重试解决,于是代码里面还多了自动重试一定次数的逻辑。
总结
回顾整个MongoDB的数据接入流程,可以看到,对于数据类型非常灵活的NoSQL数据库,数据接入并不是件容易的事。
总结起来,有以下经验可能值得大家借鉴:
数据接入过程需要保证尽可能的稳定,否则可能由于错过数据接入时机而丢失掉部分历史数据,还可能带来更多的耗时的跨团队协作问题(比如,协调业务系统人员补数);对于无schema或者schema比较自由的数据库,在接入数据到数据平台时,考虑用json格式存储原始数据,这可以避免在接入数据时进行数据解析带来的问题,使得数据接入过程更稳定;处理数据接入过程中的错误时,考虑将错误对应的数据id保存下来,以便反馈给业务系统修复。
–
基于在多家企业多个项目的经验总结,我们沉淀出一套企业数据开发工作台,可以帮助团队高效交付数据需求,帮助企业快速构建数据能力,工作台地址:https://data-workbench.com/
我们开源了其中的核心模块–ETL开发语言,开源项目地址:https://github.com/easysql/easy_sql
本文《MongoDB数据接入实践》版权归Thoughtworks思特沃克中国所有,引用MongoDB数据接入实践需遵循CC 4.0 BY-SA版权协议。







 京公网安备 11010802041100号
京公网安备 11010802041100号