一、什么Mysql的主从复制
MySQL数据库自身提供的主从复制功能就可以方便的实现数据的多处自动备份,实现数据库的拓展。多个
数据备份不仅可以加强数据的安全性,通过实现读写分离还能进一步提升数据库的负载性能。
二、Mysql 主从复制分类
2.1 从硬件实现主从复制架构区分
1. 一主一从
最简单的主从复制架构,一台主机一台从机
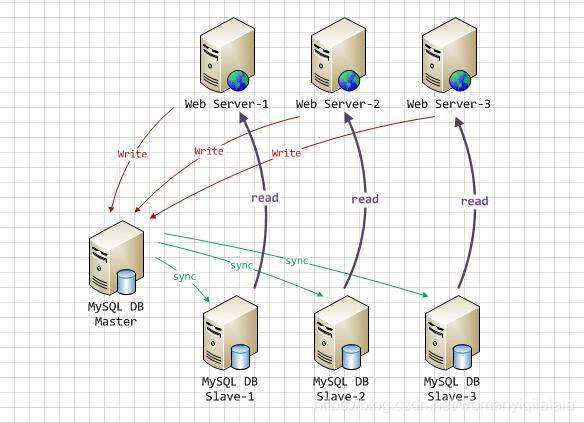
2. 一主多从
在一主多从的数据库体系中,多个从服务器默认采用异步的方式更新主数据库的变化,业务服务器在执行写或者相关修改数据库的操作是在主服务器上进行的,读操作则是在各从服务器上进行(多从需要考虑相应的负载均衡)
3. 多主无从
多个master,所有的master全部会负责读+写,master和master之间会建立一个主主复制,就不在是简单的主从复制,一般情况下只在解决"高可用性"(High availability, HA)使用多主无从
多主涉及到2中模式:
- 主备:active-passive模式,active服务器对外提供正常服务,当active宕机时,passive中进行选举一个升级为新的active对外提供服务,active 和 passive 进行主主复制保证数据一致性
- 互为主从:active-active 模式,也可以理解为互为主从,所有的maste都是activer全部会负责读+写,业务场景更多的是写多读少,master对于代码来说是透明的,请求经过负载均衡之后分发到相应的某一个master上,master和master之间也是通过主主复制保证数据一致性。
无论是active-active还是active-passive, 都是为了解决"高可用性"(High availability, HA)问题. 就是说尽量不要让你的服务挂掉.
4. 主到从到从
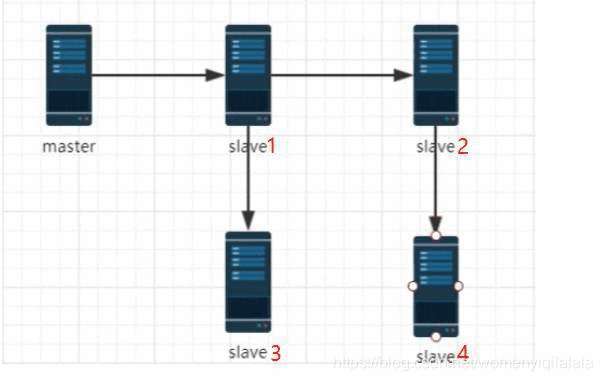
链式复制:主从从模式,maste 和 slave1、slave2 进行主从复制,但是 slave1、slave2两台服务器既做主又做从,需要与 slave3、slave4同步数据
5. 环形多主
服务器互为主从,业互为主从结构只不过是在master1于master2上互相设置主服务器为对方。务场景更多的是写多读少,master对于代码来说是透明的,请求经过负载均衡之后会发到相应的某一个master上,master之间再进行主主复制。属于active-active 模式
7. 多主多从
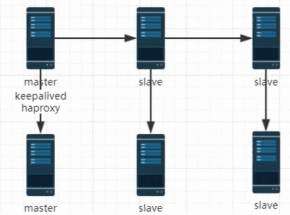
主从之间主从复制,主主互为主从进行主主复制
2.2 复制方式区分
1. 异步复制
My SQL复制默认是异步复制, Master:将事件写入 bingo,提交事务,自身并不知道save是否接收是否处理;这样就会有一个问题,主如果 crash掉了,此时主上已经提交的事务可能并没有传到从上,如果此时强行将从提升为主,可能导致新主上的数据丢失
缺点:牺牲了强一致性,不能保证所有事务都被所有save接收
2. 同步复制
所有的从库都执行了该事务才返回给客户端,也就是说 Maste提交事务,直到事务在所有save都已提交,才会返回客户端事务执行完毕信息;
缺点:需要等待所有从库执行完该事务才能返回,所以全同步复制的性能必然会受到严重的影响
3. 半同步复制
当 Master上开启半同步复制功前时,至少有一个save开启其功能。当 Master向 slave提交事务,且事务已写入 relay-og中并刷新到磁盘上,Save才会告知 Maste已收到;若 Master提交事务受到阻塞,出现等待超时,在一定时间内 Master没被告知已收到,此时 Master自动转换为异步复制机制。
介于异步复制和全同步复制之间,主库在执行完客户端提交的事务后不是立刻返回给套户端,而是等待至少一个从库接收到并写到 relay log中才返回给客户端。
缺点:
此时,客户端会收到事务提交失败的信息,客户端会重新提交该事务到新的主上,当岩机的主库重新
启动后,以从库的身份重新加入到该主从结构中,会发现,该事务在从库中被提交了两次,一次是之前作为主的时候,一次是被新主同步过来
此时,从库已经收到并应用了该事务,但是客户端仍然会收到事务提交失败的信息,重新提交该事务到新的主机上
半同步复制(mysql5.5以上支持),5.7 中半同步复制已经解决了2次写入的缺点
三、主从复制实现原理
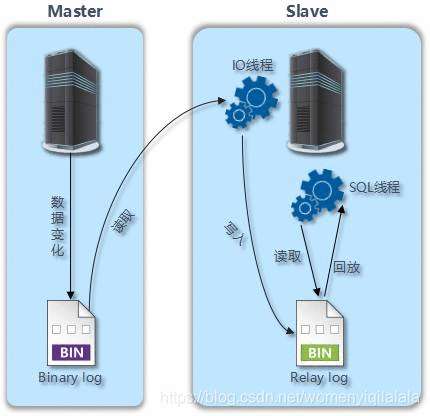
复制过程:
- Master必须启用二进制日志,将任何修改了数据库数据的事件(insert,alert,create…)记录到二进制日志( binary log)中
- Slave开启一个线程(I/O Thread)把自己扮演成 mysql 的客户端,通过 mysql 协议,请求Master的二进制日志文件中的事件
- Master启动一个线程(dump Thread),检查自己二进制日志中的事件,跟对方请求的位置对比,如果不带请求位置参数,则Master就会从第一个日志文件中的第一个事件一个一个发送给Slave。
- Slave接收到Master发送过来的数据把它放置到中继日志(Relay log)文件中。并记录该次请求到Master的具体哪一个二进制日志文件内部的哪一个位置(主节点中的二进制文件会有多个)
- Slave启动另外一个线程(sql Thread ),把 Relay log 中的事件读取出来,并在本地再执行一次。
四、Mysql 主从复制简单实现
一般情况下,mysql都是通过主从复制实现数据同步,再通过读写分离实现数据库高可用能力。这里实现的模型简单的一主一从
4.1 准备环境
准备两个版本相同的mysql服务器,搭建的时候是在同一台服务器中创建了2个mysql容器,master 3306:3306 ,slave 4306:3306
docker安装mysql 5.7:https://blog.csdn.net/womenyiqilalala/article/details/105712766

4.2 修改Master配置文件(my.cnf)
master 添加两个配置(容器配置文件挂载主机路径:/etc/mysql/conf/my.cnf):
[mysql] 设置配置的前置组 ,否则会重启数据库服务加载配置文件异常
[mysqld]
## 同一局域网内注意要唯一
server-id=100
## 开启二进制日志功能,可以随便取(关键)
log-bin=mysql-bin
配置完成之后,需要重启mysql服务使配置生效。使用service mysql restart完成重启。重启mysql服务时会使得docker容器停止,我们还需要docker start mysql启动容器(主机重启服务:systemcel restart mysql)。
如果配置文件配置错误,service mysql restart会提示“[ERROR] Found option without preceding group in config file /etc/my.cnf at line 1!”
4.3 Master 创建同步复制的用户并赋权
查看容器信息:
docker inspect 容器ID/NAME
查看容器的ip地址:
docker inspect --format='{{.NetworkSettings.IPAddress}}' 容器ID/NAME

创建同步复制的用户并赋权(ip可以直接为’%’):
create user 'lqw'@'172.17.0.%' identified by '123456';
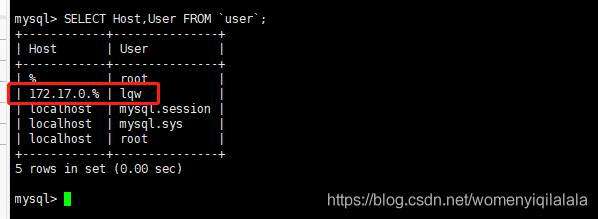
GRANT REPLICATION SLAVE ON *.* to 'lqw'@'172.17.0.%' identified by '123456';
4.4 修改Slave配置文件
slave 添加两个配置(容器配置文件挂载主机路径:/etc/mysqlslave/conf/my.cnf):
[mysqld]
设置server_id,注意要唯一
server-id=101
## 开启二进制日志功能,以备Slave作为其它Slave的Master时使用
log-bin=mysql-slave-bin
## relay_log配置中继日志
relay_log=mysql-relay-bin
配置完成后也需要重启mysql服务和docker容器,操作和配置Master(主)一致。
4.5 链接Master(主)和Slave(从)
在Master进入mysql(),执行
show master status;
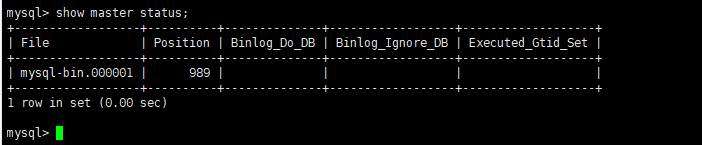
File和Position字段的值后面将会用到,在后面的操作完成之前,需要保证Master库不能做任何操作,否则将会引起状态变化,File和Position字段的值变化。
在Slave 中进入 mysql,执行三条语句
stop slave;
change master to master_host='172.17.0.2', master_user='lqw', master_password='123456', master_port=3306, master_log_file='mysql-bin.000001', master_log_pos= 989, master_connect_retry=30;
start slvae;
- master_port:Master的端口号,指的是容器的端口号,如果mster 端口为3306 可以省略不写
- master_user:用于数据同步的用户
- master_password:用于同步的用户的密码
- master_log_file:指定 Slave 从哪个日志文件开始复制数据,即上文中提到的 File 字段的值
- master_log_pos:从哪个 Position 开始读,即上文中提到的 Position 字段的值
- master_connect_retry:如果连接失败,重试的时间间隔,单位是秒,默认是60秒
- 在Slave 中的mysql终端执行show slave status \G;用于查看主从同步状态。
在Slave 中的mysql终端执行show slave status \G;用于查看主从同步状态。
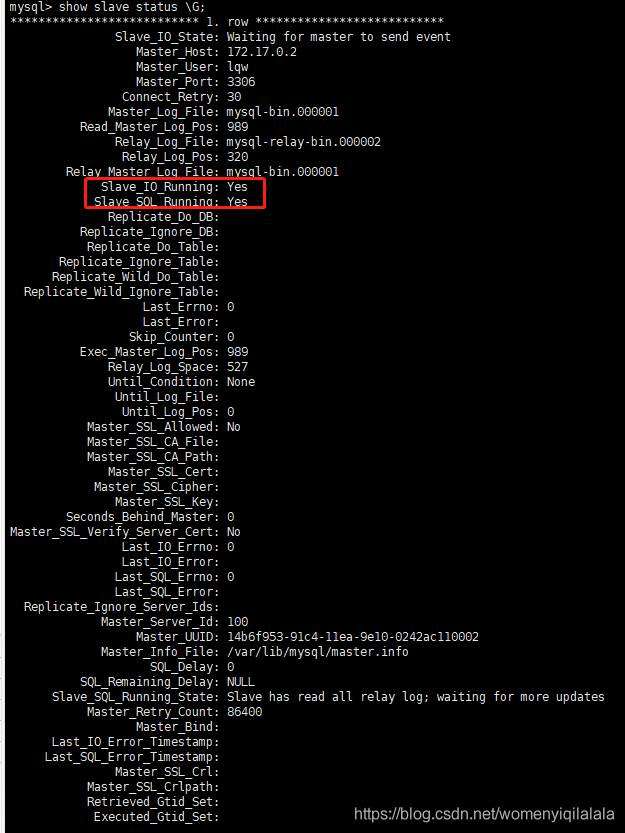
使用start slave开启主从复制过程,,SlaveIORunning 和 SlaveSQLRunning 的值为YES;
可以在Master查看主从关系
show processlist;

4.6 主从复制排错
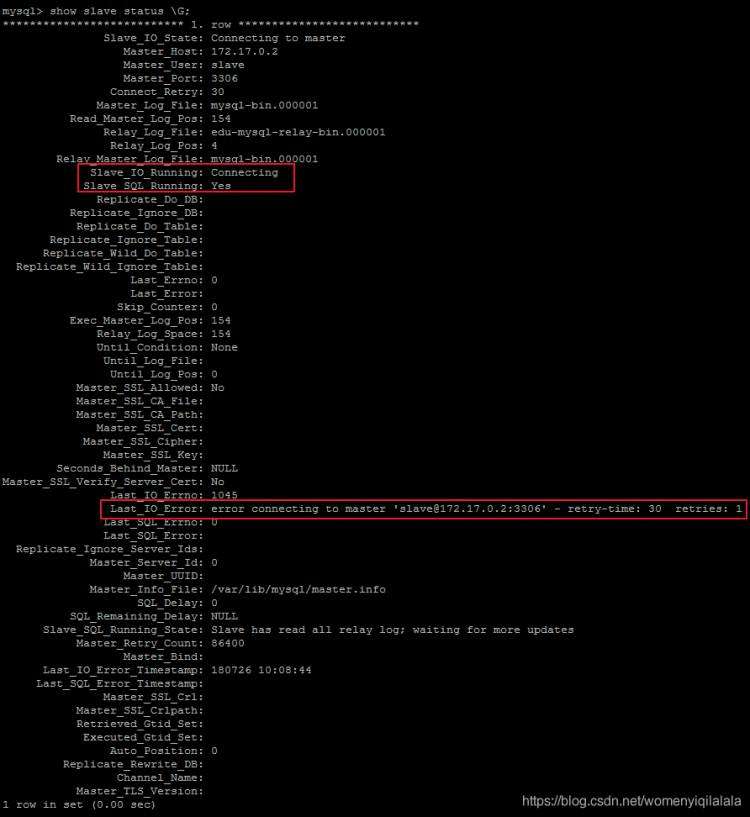
使用start slave开启主从复制过程后,如果SlaveIORunning一直是Connecting,则说明主从复制一直处于连接状态,这种情况一般是下面几种原因造成的,我们可以根据 Last_IO_Error提示予以排除。
- 网络不通
检查ip,端口
- 密码不对
检查是否创建用于同步的用户和用户密码是否正确
- pos不对
检查Master的 Position
4.7 测试主从复制
测试主从复制方式就十分多了,最简单的是在Master创建一个数据库,然后检查Slave是否存在此数据库。
主Master:
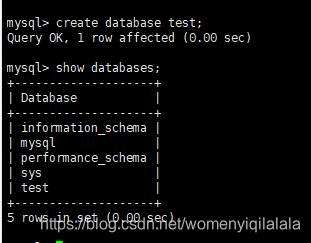
从Slave:

主Master查看二进制文件:
show binlog events in 'mysql-bin.000001' from 989;
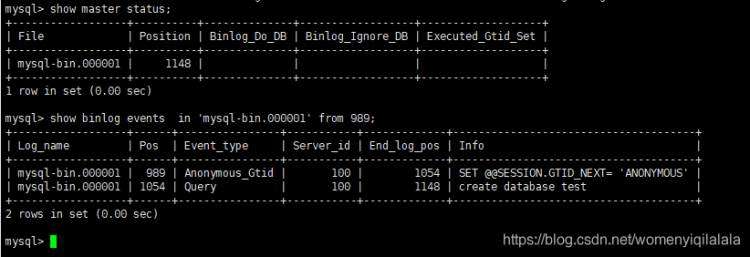
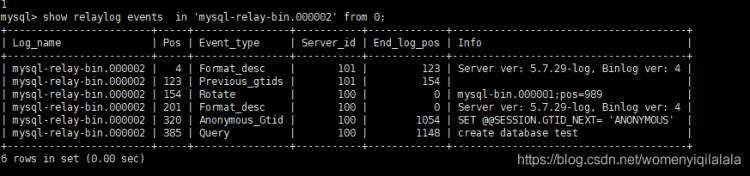
从Slaver 查看中继日志:
show relaylog events in 'mysql-relay-bin.000002' from 0;
五、Sharding JDBC 读写分离配置
Sharding-JDBC、Mycat 目前版本都是不负责主从同步,需要自己运维搭建Mysql 主从复制集群(https://blog.csdn.net/womenyiqilalala/article/details/105816031)
引入Sharing JDBC 相关依赖:
org.mybatis.spring.boot
mybatis-spring-boot-starter
1.3.2
com.zaxxer
HikariCP
io.shardingsphere
sharding-jdbc-spring-boot-starter
3.1.0
mysql
mysql-connector-java
5.1.32
com.alibaba
druid
1.1.9
配置application.properties:
# 数据源名称定义
sharding.jdbc.datasource.names=ds0,ds1
# 主数据源
sharding.jdbc.datasource.ds0.type=com.alibaba.druid.pool.DruidDataSource
sharding.jdbc.datasource.ds0.driver-class-name=com.mysql.jdbc.Driver
sharding.jdbc.datasource.ds0.url=jdbc:mysql://127.0.0.1:3306/test?characterEncoding=utf-8
sharding.jdbc.datasource.ds0.username=root
sharding.jdbc.datasource.ds0.password=root
# 从数据源
sharding.jdbc.datasource.ds1.type=com.alibaba.druid.pool.DruidDataSource
sharding.jdbc.datasource.ds1.driver-class-name=com.mysql.jdbc.Driver
sharding.jdbc.datasource.ds1.url=jdbc:mysql://127.0.0.1:4306/test?characterEncoding=utf-8
sharding.jdbc.datasource.ds1.username=root
sharding.jdbc.datasource.ds1.password=root
# 读写分离配置
# dataSource 随意给masterslave 设置一个名字
sharding.jdbc.config.masterslave.name=dataSource
# 负载均衡算法 round_robin随机(内置算法)
sharding.jdbc.config.masterslave.load-balance-algorithm-type=round_robin
# 主库
sharding.jdbc.config.masterslave.master-data-source-name=ds0
# 从库
sharding.jdbc.config.masterslave.slave-data-source-names=ds1
# 日志打印SQL语句
sharding.jdbc.config.props.sql.show=true
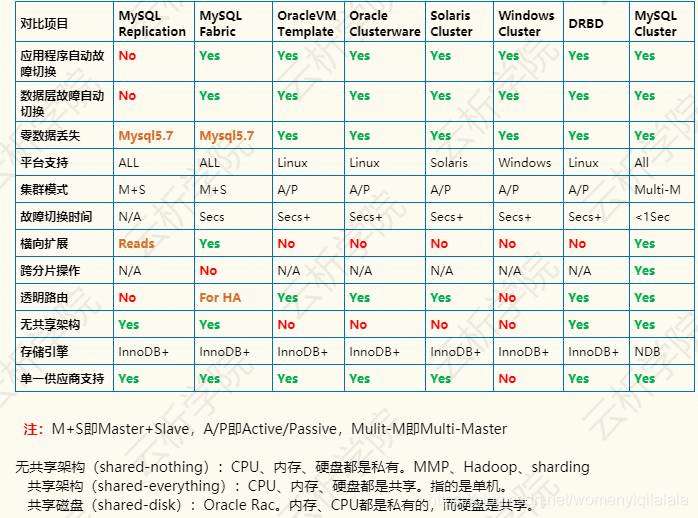
六、Mysql 高可用方案比较












 京公网安备 11010802041100号
京公网安备 11010802041100号