作者:美甲控Alily | 来源:互联网 | 2023-09-25 18:10
Scrapy爬虫实战:百度搜索找到自己 背景 分析 怎么才算找到了自己 怎么才能拿到百度搜索标题 怎么爬取更多页面 baidu_search.py 声明BaiDuSearchItem Item Pipeline 配置Pipeline 运行测试
这里我们演示从百度找到我自己来让大家理解了解爬虫的魅力。
背景
有啥不懂的问度娘,百度搜索引擎可以搜到我们想要的内容,这里我们可以尝试爬取百度搜索引擎搜出来的东西,然后找到我们想要的内容。
例如:我们可以这样来搜索 https://www.baidu.com/s?wd=灵动的艺术
当然,因为我的博客是新开的,第一个自然不是我,并且能排名第一的必然也是要花钱的,大家懂的。
并且不但第一个不是我,可能第一页也可能都找不到我。我们需要不断过滤更多页才能找到我自己
分析
这里我演示找到我自己的博客就算是找到了我自己,判定方法有多种,比如找到了标题为【灵动的艺术的博客】新开始,新旅程 - CSDN博客就可以算是找到了我,或者百度连接为 http://www.baidu.com/link?url=9MdeR3DMon9bNvI8_loZk8MWb2s8zApEZx43oiOQgcsKAiSF3mvOD98YE811awwwm6NXYm8w7bVwfCF-a5VDerAiCmJyM1qFM9u5YrVraIO 这个,也算是找到了我自己。
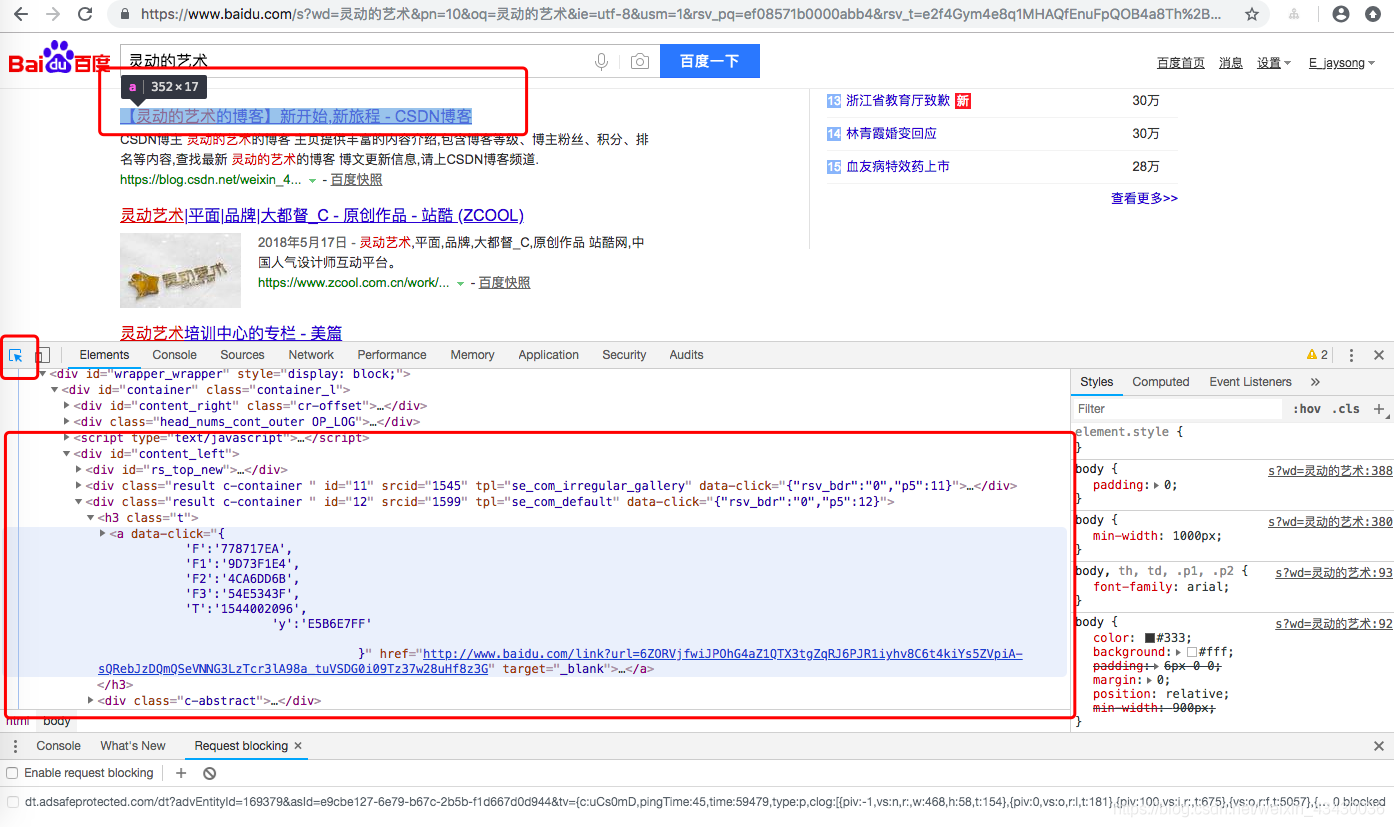
怎么才能拿到百度搜索标题 如下图,我们利用浏览器的检查功能,利用选择工具,选中标题,我们就可以看到当前页面的内容
这里我们可以知道我们的标题内容在'//div[@class="result c-container "]/h3/a'标签里面,那么我们需要获取这类标签的内容。
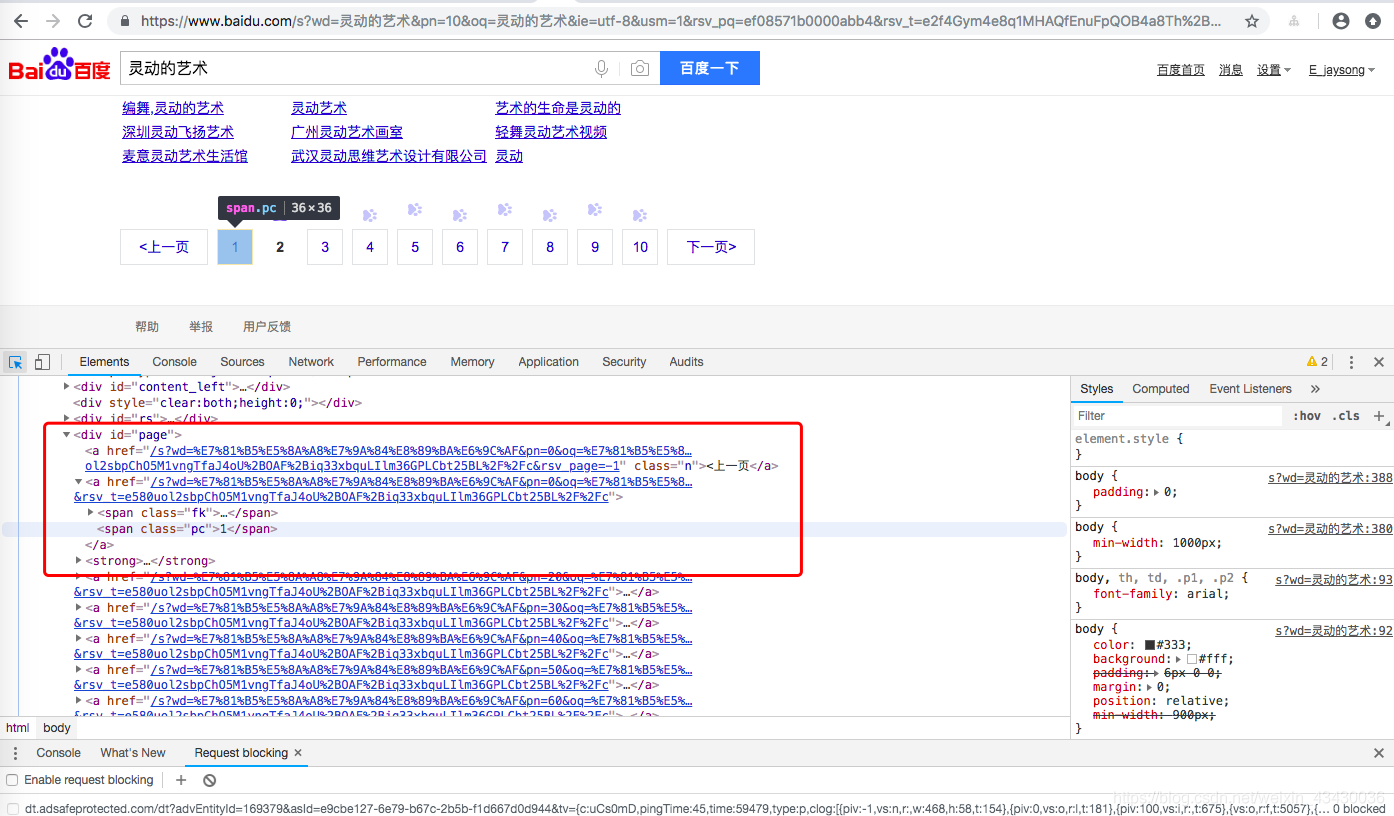
同样的,如果我们希望爬取更多页面,我们需要拿到更页面的连接,并且继续访问它们。
那么我们可以知道//div[@id="page"]/strong/span[@class="pc"]/text()标签可以拿到当前页。//div[@id="page"]/a/@href可以拿到更多页面的跳转连接。
baidu_search.py
这里我们修改之前的baidu_search.py
import scrapyfrom tutorial. items import BaiDuSearchItemclass BaiduSearchSpider ( scrapy. Spider) : = 'baidu_search' = [ 'www.baidu.com' ] = [ 'http://www.baidu.com/s?wd=灵动的艺术' ] def parse ( self, response) : = int ( response. xpath( '//div[@id="page"]/strong/span[@class="pc"]/text()' ) . extract_first( ) ) for i, a in enumerate ( response. xpath( '//div[@class="result c-container "]/h3/a' ) ) : = '' . join( a. xpath( './em/text() | ./text()' ) . extract( ) ) if title. find( '灵动的艺术的博客' ) > - 1 : = BaiDuSearchItem( ) [ 'visit_url' ] = a. xpath( '@href' ) . extract( ) [ 'page' ] = current_page[ 'rank' ] = i+ 1 [ 'title' ] = titleyield itemfor p in response. xpath( '//div[@id="page"]/a' ) : = 'http://www.baidu.com' + str ( p. xpath( './@href' ) . extract_first( ) ) yield scrapy. Request( p_url, callback= self. parse_other_page) def parse_other_page ( self, response) : = int ( response. xpath( '//div[@id="page"]/strong/span[@class="pc"]/text()' ) . extract_first( ) ) for i, a in enumerate ( response. xpath( '//div[@class="result c-container "]/h3/a' ) ) : = '' . join( a. xpath( './em/text() | ./text()' ) . extract( ) ) if title. find( '灵动的艺术的博客' ) > - 1 : = BaiDuSearchItem( ) [ 'visit_url' ] = a. xpath( '@href' ) . extract( ) [ 'page' ] = current_page[ 'rank' ] = i+ 1 [ 'title' ] = titleyield item
代码比较简单,简单明了
声明BaiDuSearchItem
爬取的主要目标就是从非结构性的数据源提取结构性数据,例如网页。 Scrapy spider可以以python的dict来返回提取的数据.虽然dict很方便,并且用起来也熟悉,但是其缺少结构性,容易打错字段的名字或者返回不一致的数据,尤其在具有多个spider的大项目中。。
为了定义常用的输出数据,Scrapy提供了 Item 类。 Item 对象是种简单的容器,保存了爬取到得数据。 其提供了 类似于词典(dictionary-like) 的API以及用于声明可用字段的简单语法。
许多Scrapy组件使用了Item提供的额外信息: exporter根据Item声明的字段来导出数据、 序列化可以通过Item字段的元数据(metadata)来定义、 trackref 追踪Item实例来帮助寻找内存泄露 (see 使用 trackref 调试内存泄露) 等等。
import scrapyclass BaiDuSearchItem ( scrapy. Item) : = scrapy. Field( ) = scrapy. Field( ) = scrapy. Field( ) = scrapy. Field( )
当Item在Spider中被收集之后,它将会被传递到Item Pipeline,一些组件会按照一定的顺序执行对Item的处理。
每个item pipeline组件(有时称之为“Item Pipeline”)是实现了简单方法的Python类。他们接收到Item并通过它执行一些行为,同时也决定此Item是否继续通过pipeline,或是被丢弃而不再进行处理。
以下是item pipeline的一些典型应用:
清理HTML数据 验证爬取的数据(检查item包含某些字段) 查重(并丢弃) 将爬取结果保存到数据库中 class BaiDuSearchPipeline ( object ) : def process_item ( self, item, spider) : print ( 'BaiDuSearchPipeline' , item) return item
我们需要在settings.py中配置Pipeline
= { 'tutorial.pipelines.BaiDuSearchPipeline' : 1 , }
cd /data/code/python/venv/venv_Scrapy/.. /bin/python3 .. /bin/scrapy crawl baidu_search
结果表明,百度搜索出来的结果,我们在第2页第一个和第5页第八个都找到了我自己。
GitHub源码







 京公网安备 11010802041100号
京公网安备 11010802041100号