SQL执行计划解析(2)- 基本查询的图形执行计划(上)
某种程度上,学习阅读图形执行计划和学习一门新语言很类似。不同之处是这门语言是基于图标的,而且单词(图标)非常少。每个图标代表了一个操作符,本章里,“图标”和“操作符”可以互换地使用。
前边一章我们遇到了两个操作符(select和table scan),实际上总共有79个,好在我们不需要全部学会才能开始阅读执行计划,大多数查询只用到了其中的一小部分。如果遇到了我们没有提到的图标,参阅http://msdn2.microsoft.com/en-us/library/ms175913.aspx
图形执行计划里有4中不同类型的操作符:
- 逻辑和物理操作符(logical and physical operators):蓝色图标,代表查询执行或DML声明
- 并行物理操作符(parallelism physical operators):也是蓝色图标,代表并行操作。某种意义上,它是逻辑和物理操作符的子集,之所以单独考虑是因为它承担是完全不同等级的执行计划分析。
- 游标操作符(Cursor operators):黄色图标,代表T-Sql游标操作。
- 语言元素(Language elements):绿色图标,代表T-Sql语言元素,如Assign、Declare、If、Select、While等。
本章我们主要关注逻辑和物理操作符包括并行物理操作符。
我们需要了解操作符的行为。有些操作符,sort、hash match、hash join等,它们需要一定的内存才能执行,因此,如果查询里有这种操作符,那么就可能需要等待可用的内存,对性能产生负面影响。绝大多数操作符都以阻塞方式或非阻塞方式运行。非阻塞操作符在接收到输入数据的同时就创建输出数据,阻塞式操作符必须等待所有的输入到达后才能生成输出数据。
单表查询
1. 聚集索引扫描(Clustered Index Scan)
SELECT*FROM Person.Contact
下边是实际的执行计划
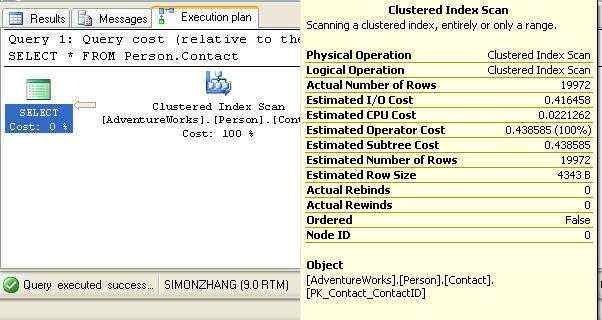
图2-1
我们可以看到,这里执行了一个聚集索引扫描操作来获取数据,使用的聚集索引是PK_Contact_ContactID,得到了19972行数据。
Sql Server里的索引存储在一个B-Tree里,而聚集索引不只是像常规索引那样存储了key structure,还存储了了数据并排序。这也是一个表只能有一个聚集索引的主要原因。
聚集索引扫描和全表扫描(table scan)概念上基本相同,整个索引或大多数的索引都被逐行地遍历来确定哪些数据是查询需要的。
如本例所示,索引扫描通常发生在优化器认为需要返回的行数太多,与其使用索引里边的key还不如简单地扫描所有数据来的快的场景。
2.聚集索引查找(clustered index seek)
给上边的查询加个where子句
SELECT*FROM Person.Contact where ContactId =1
我们就得到下边的执行计划
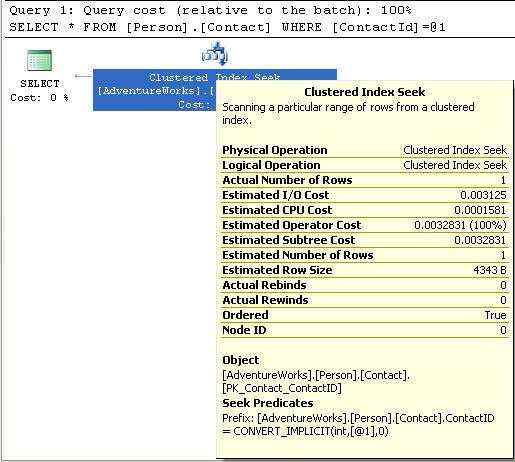
图2-2
索引查找完全不同于索引扫描,索引扫描会遍历所有的行来找需要的数据,索引查找不论是聚集索引还是非聚集索引,发生在优化器能够定位索引并且通过索引获取所需数据的场景。因此,它需要告诉存储引擎通过指定的索引的key来查找value。索引查找操作类似于从书的目录里先找到正确的页数,以便快速找到单词。聚集索引查找还有另外的好处,它不仅比索引扫描更加成本低廉,而且不需要额外的步骤去获取数据,因为数据就存储在索引里。另注意,Ordered属性这里为True。
3.非聚集索引查找(Non-Clustered Index Seek)
SELECT ContactID
FROM Person.Contact
WHERE EmailAddress LIKE'sab%'
执行计划如下图,使用了索引IX_Contact_EmailAddress.
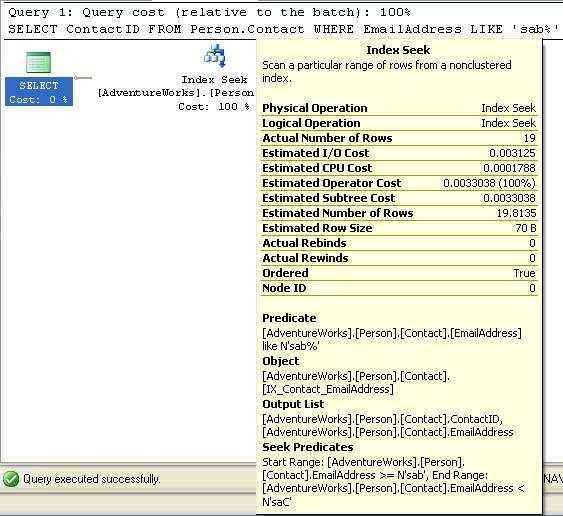
图2-3
注:非聚集索引查找的图标名字弄错了,写成了Index Seek,不过这没什么大的影响.
和聚集索引查找一样的是,非聚集索引查找也使用来查找那些行需要返回,不一样的是,非聚集索引查找使用的是非聚集索引,优化器可能在非聚集索引里找到所需的全部数据,也可能还需要从聚集索引里查找数据,这个额外的IO操作会轻微降低性能,详情如下节.
4.键查找(Key lookup)
我们稍微修改下上边的查询,取其中的多个列.
SELECT ContactID,
LastName,
Phone
FROM Person.Contact
WHERE EmailAddress LIKE'sab%'
执行计划如下
ps:我的数据库版本比较旧,没有Key Lookup而是一个lookup属性为True的聚集索引,下边这张图还有2-6是从书里截出来的,看起来模糊一点
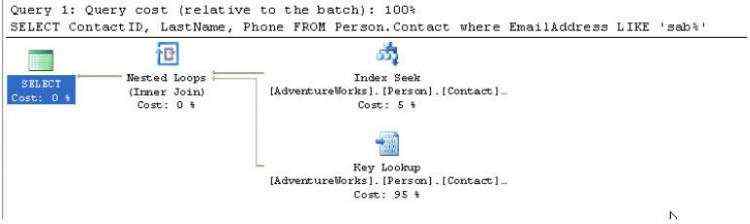
图2-4
我们终于见到了第一个有多个操作的计划.从右到坐,从上到下,第一个是对IX_Contact_EmailAddress的索引查找操作.这是一个值不唯一的、非聚集的索引,对我们这个查询来说也不是覆盖式(non-covering)。所谓非覆盖式意思就是说,索引里没有包含查询所需的所有列,必须再从聚集索引里获取数据。我们可以从Index Seek的output list里看到,里边有EmailAddress和ContactId列。
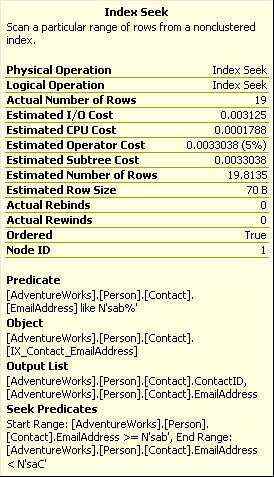
图2-5
然后Key lookup使用key的值从聚集索引PK_Contact_ContactID里找出相应的行,它的output list是LastName和Phone列。如下图
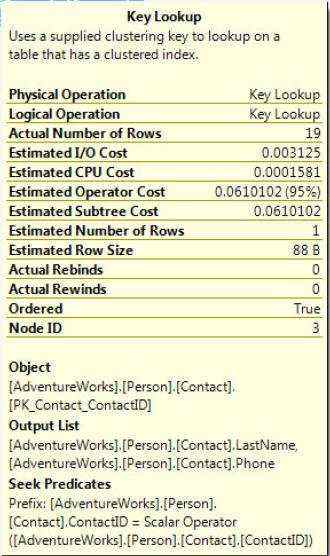
图2-6
一个Key lookup就是使用聚集索引对表进行书签查找(bookmark lookup)。Key lookup的出现表示查询能够通过覆盖式索引获得性能提升。如果索引是覆盖式的,那么Key lookup就能避免掉。伴随Key lookup出现的一定有一个嵌套循环连接(Nested loop join)操作,用于将两个操作的结果组合起来。
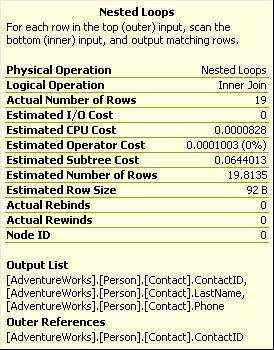
图2-7
嵌套循环连接是一个标准类型的连接,它的出现并不意味着性能问题。在我们的例子里,由于有Key lookup,那么就需要嵌套循环连接将Index Seek的行和Key lookup的行组合在一起。如果没有Key lookup,那么嵌套循环连接也就不会出现。
5.全表扫描(Table Scan)
顾名思义,全表扫描就是逐行扫描表来获取所需的数据。
SELECT*
FROM[dbo].[DatabaseLog]
计划如图
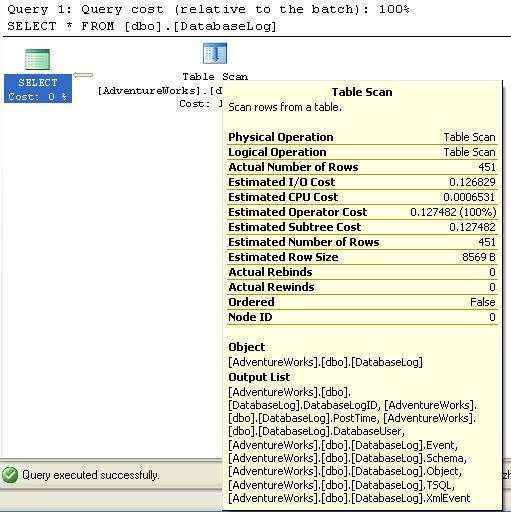
图2-8
全表扫描发生有几个原因,通常是因为没有可用的索引,优化器不得不检索所有的行。另外个常见的原因是返回表的所有行,如本例所示,不论有没有索引,扫描全部行通常都会比使用索引查找每一行要快些。还有个原因是表里的行很少,优化器认为扫描所有行比使用索引要快。
6.RID查找(RID lookup)
如果我们给上边的查询在主键列上指定过滤条件,那么就得到了一个使用RID查找的执行计划。
SELECT*
FROM[dbo].[DatabaseLog]
WHERE DatabaseLogID =1
执行计划如图
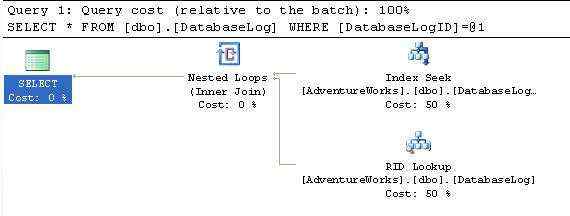
图2-9
为了返回结果,优化器首先首先在主键上执行索引查找(Index Seek),鉴定行是否符合where条件,但是索引里并不包含所需的全部数据。看上边的Index Seek的tool tips如图2-10,我们就会发现output list里边的Bmk1000,这个告诉我们,索引查找实际上是书签查找的一部分。然后优化器执行RID查找,使用行标识符找到需要返回的行,RID查找就是一种书签查找,发生在heap table(没有聚集索引的表)上。换句话说,由于表没有聚集索引,那么就必须使用链接到堆索引的一个行标识符。这就增加了磁盘IO,因为这需要执行两个不同的操作,让后通过嵌套循环组合在一起。
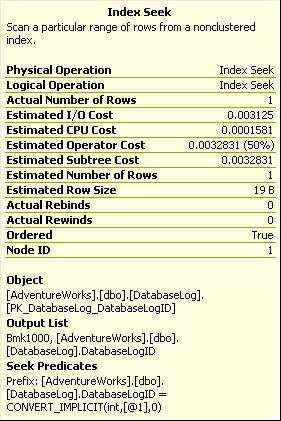
图2-10
RID查找的tool hint如下图
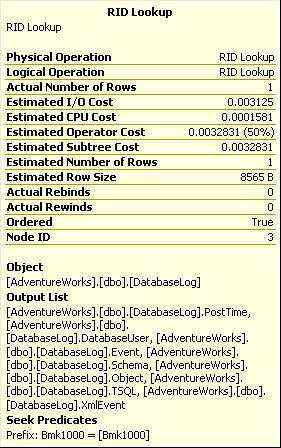
图2-11
我们又看到了Bmk1000,这次是在Seek Predicates部里边。这就意味着,查询计划使用了书签查找(我们这个例子里就是RID查找)。我们这个里只需要查找1行,性能上看不是什么大问题,如果RID查找返回很多行,那么就需要仔细考虑如何降低磁盘IO了,重写查询或者添加聚集索引或者使用覆盖式索引等。
SQL执行计划解析(2)- 基本查询的图形执行计划(中)
2.表连接(Table join)
到目前为止我们都是在和单个表打交道,下边我们看下查询中的连接。下边这个查询获取雇员信息,把FirstName和LastName连接起来,这样返回的信息显得更为友好。
SELECT e.[Title], a.[City], c.[LastName] + ', ' + c.[FirstName] AS EmployeeNameFROM [HumanResources].[Employee] eJOIN [HumanResources].[EmployeeAddress] ed ON e.[EmployeeID] = ed.[EmployeeID]JOIN [Person].[Address] a ON [ed].[AddressID] = [a].[AddressID]JOIN [Person].[Contact] c ON e.[ContactID] = c.[ContactID]; |
执行计划如图
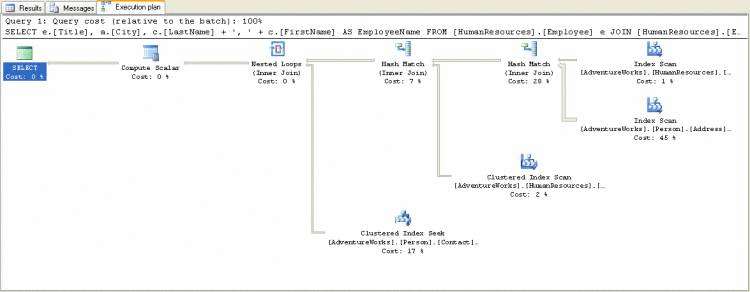
图2-12
这个查询中出现了多个的处理步骤,每个步骤的开销也不同,它们在执行树中从右到坐一步一步累计起来。其中3个开销最大的操作分别是
1.对Person.Address表的索引扫描(Index Scan),45%
2.HumanResource.EmployeeAddress表和Person.Address表之间的Hash Match Join操作,28%
3.Person.Contact表上的聚集索引扫描,17%
右上角的是对HumanResource.EmployeeAddress表的索引扫描,它的下边就是对Person.Address表的索引扫描,也就是我们的开销最大的运算符。看下ToolTip,如图2-13,我们可以看到这是对索引IX_Address_AddressLine1_AddressLine2_City_StateProvinceID_PostalCode执行的扫描,存储引擎遍历了19614行的数据来找到我们需要的。
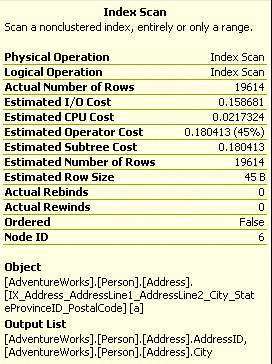
图2-13
如Output list里所示,查询优化器需要AddressId列和City列。查询优化器按照表中的索引和列的可选择性进行计算,它认为最好的方式就是遍历索引。遍历19614行的数据的开销占据了总开销的45%。
0.180413仅仅是个内部计算出的数字,优化器用于衡量各个操作的相对开销,这个数字越低操作的效率越高。
Hash Match Join
继续上边的例子,这两个索引扫描的输出通过hash match join组合起来。
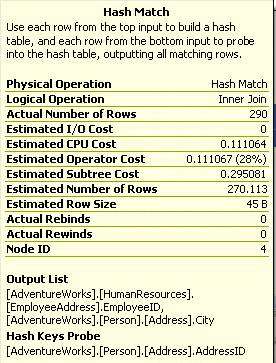
在我们讨论Hash Match Join是什么之前,需要了解两个概念,Hash运算(即散列算法) 和Hash表。
Hash运算是一种编程技术,用来把数据转换为符号形式,使数据可以更容易更快速地被检索。例如,表中的一行数据,可以通过程序转化为一个唯一的值,这个值就代表了这行数据的内容。这和数据加密很类似,一个hash值同样也可以被转换回原始数据。
Hash表是一个数据结构,它把所有的元素都切分成同等大小的“类”或“块”,允许对这些元素的快速访问。hash函数决定了元素应该进入哪个“块”。例如,你可以从表里取出一行数据,将其转换为hash值,然后将hash值存入hash表。
Hash Match Join 发生时,Sql Server连接一大一小两张表,对小表里的数据行进行hash运算,将生成的hash值插入到hash表里,然后遍历大表里的数据,每次取出一行在hash表里寻找匹配的行。对小表进行hash运算是为了降低hash表的大小,hash值可以进行快速的比较。如果两张表都很大,那么hash match jion和其他类型的join比起来就非常低效。
Hash Match Join对大数据集尤其是其中一个表比另外的一个小很多的时候效率很高。对表没有按照join列排序或者表中没有可用索引的情况,hash match join也是很有效的方式。
Hash Match Join的出现也可能意味着存在更高效的连接方式(Nested Loop或Merge),这可能是以下原因造成的:
1.索引缺失或者索引不正确
2.where语句缺失
3.where语句里有对索引列的计算或转换使得索引失效
在这些情况下,优化器认为Hash Match Join是连接两张表的最高效的方式,但是有可能可以通过增加索引、或者增加where语句来减少数据量等方式获得更高效的查询。
聚集索引查找(Clustered Index Seek)
接下来我们看占用17%的操作,是对Person.Contact表上的PK_Contact_ContactID聚集索引查找,对于这个表来说PK_Contact_ContactID既是主键又是聚集索引。
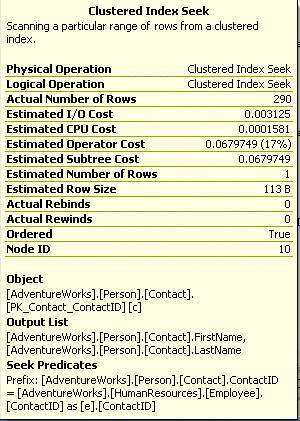
图2-15
从Seek Predicates节可以看出,这个操作直接将HumanResources.Employee表和Person.Contact表的ContactID列进行连接。
Nested Loop Join(嵌套循环连接)
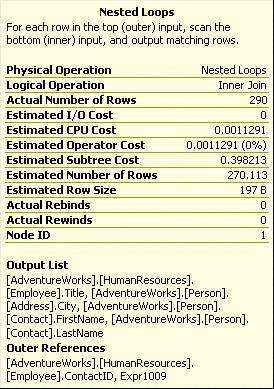
图2-16
顾名思义,Nested Loop Join这个操作使用嵌套双层循环,在我们这个计划里下边这个(17%那个)运算符的结果在外层。由于两个数据集都很小,所以这是个很高效的操作。
只要内层数据集小,外层数据集(小不小不要紧)有索引的情况下,Nested Loop Join是一种非常高效的连接机制。除非数据集超大,这种连接方式应该是你最希望看到的连接方式。
标量计算(Compute Scarlar)
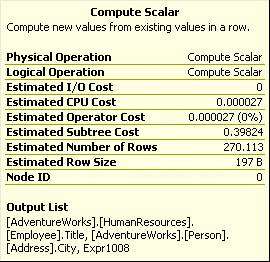
图2-17
标量计算表示此操作产生了一个标量值,通常是通过计算。我们这个例子中,假名EmployeeName组合了LastName和FirstName并用逗号连接。
Merge Join
除了Hash Match 和Nested Loop外,还有一种连接即Merge Join。执行以下查询。
SELECT c.CustomerIDFROM Sales.SalesOrderDetail odJOIN Sales.SalesOrderHeader ohON od.SalesOrderID = oh.SalesOrderIDJOIN S ales.Customer cON oh.CustomerID = c.CustomerID |
执行计划如图
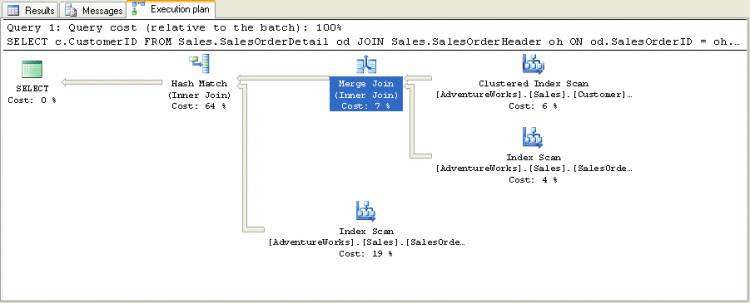
图2-18
使用Merge Join连接的两张表必须是按照连接列预先排序好了的,这中情况下Merge Join是一种高效的连接方式。如果连接的表没有按照连接列预先排序的话,查询优化器要么先排序再执行Merge
Join, 或者执行效率稍低些的Hash Match Join。
PS:以前做cobol时处理数据的一种方式,估计原理是一样的。有两组数据,都是排好序的,假设是按某个字段从小到大。设两个指针分别代表左右两个数据的当前记录位置,比较当前位置的数据大小,如果左边的小右边大,那么左边的指针向前移动一位,如果右边的小左边的大,那么右边的指针向前移动一位,如果一样大,那么这是匹配的两条数据,左右同时向前移动一位。这只是连接列的值唯一的情形,也可能是多对多的匹配,当多对多匹配时,Merge Join就必须使用cache了,原理应该是这样子,这样就避免了双层循环,所以如果是排好序的两张表连接,Merge Join的效率应该是最高的。






 京公网安备 11010802041100号
京公网安备 11010802041100号