↑ 关注 + 置顶 ~ 别错过小z的干货内容

| 作者:无眠
| 来源:知乎
前些天在网上冲浪的时候看到一个案例咨询,问说世界500强的数据分析要不要去,评论区一片爆炸:“楼主能分享一下文科生怎么转行做数据分析吗??”、“SQL、python这些学起来好痛苦!”我看着屏幕苦笑,数据分析岗位现在的热门程度如果要形容的话,基本就是随便抓一个微博网友都知道这个岗位了。
Anyway,言归正传,数据分析师的招聘JD你们一定不陌生:

可以说,每个数据分析岗都需要会SQL。
我本人曾在滴滴、美团、平安科技的数据分析类岗位实习过,实习期间会大量运用sql进行取数。也参与了2018年的秋招,做过网易、拼多多、新浪等等公司的数据分析笔试题,还是比较了解SQL常考的题目类型的。
写这篇文章是希望帮助还没有实战过SQL的小伙伴、或者了解一些SQL语句,但是担心自己了解的太片面的小伙伴。这篇文章主要介绍的是:如果想要面试数据分析岗位,最优先需要掌握的SQL技能是哪些呢?
读完本文,你能快速知道:
(1)除了select 这种基本的语句,我最应该马上掌握的SQL语句和知识是什么?
(2)面试中SQL题80%都在考察的语法是什么?
(3)这些语法应该怎么使用?
本文将从三大块介绍入门SQL需要掌握的语法和知识,分别是
最基础的选择(select)和连接(join/union)
最常用的函数(distinct/group by/order by等)
一些小小的进阶技巧(组内排序、取前百分之多少的值、时间函数)
从一个实习和秋招过来人的角度看,这些知识基本够面试的时候用了,如果本身也在数据分析岗位实习或者实习过,可以在评论区讨论或者补充一些也常常用到的SQL知识,大家一起交流进步~ ps. 本文主要做知识点快速突破,具体的实战练习大家必不可少还是要做!
介绍完了三大块知识后,后续会有常见的SQL面试/笔试题,可以练习和交流~
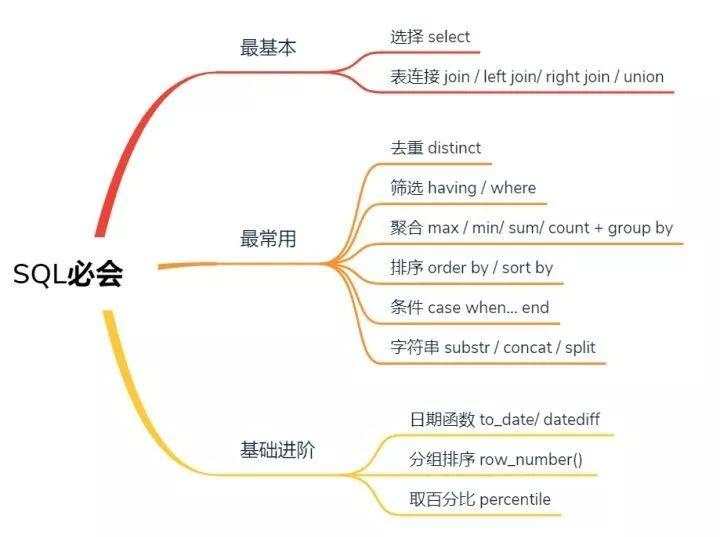 本文对于SQL知识的介绍结构
本文对于SQL知识的介绍结构1. 最基本(选数据)
-- 从table_1中选择a这一列
select a from table_1
-- table_1中有id,age; table_2中有id,sex。想取出id,age,sex 三列信息
-- 将table_1,table_2 根据主键id连接起来
select a.id,a.age,b.sex from
(select id,age from table_1) a --将select之后的内容存为临时表a
join
(select id, sex from table_2) b --将select之后的内容存为临时表b
on a.id =b.id
在这里先介绍一下几种join: (敲重点,很容易问的哦)
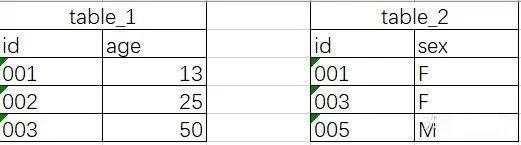
join : hive的join默认是inner join,找出左右都可匹配的记录;
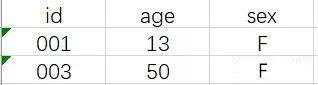
left join: 左连接,以左表为准,逐条去右表找可匹配字段,如果有多条会逐次列出,如果没有找到则是NULL;
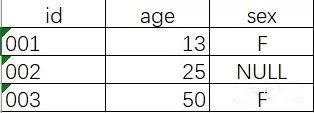
right join:右连接,以右表为准,逐条去左表找可匹配字段,如果有多条会逐次列出,如果没有找到则是NULL;

full outer join: 全连接,包含两个表的连接结果,如果左表缺失或者右表缺失的数据会填充NULL。
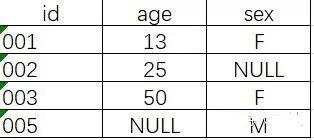
每种join 都有on ,>join 之前要确保关联键是否去重,是不是刻意保留非去重结果。
-- 不去重,合并两张表的数据
select * from
(
select id from table_1
UNION ALL
select id from table_2
)t;
union和union all 均基于列合并多张表的数据,所合并的列格式必须完全一致。union的过程中会去重并降低效率,union all 直接追加数据。union 前后是两段select 语句而非结果集。
2. 最常用(更有多重组合)
为方便大家理解每个函数的作用,先建一个表,后面以这个为示例。
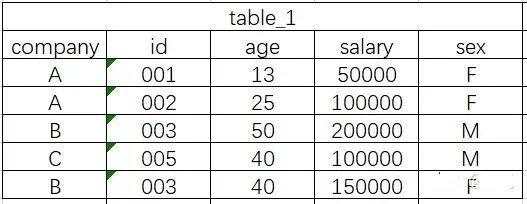
-- 罗列不同的id
select distinct id from table_1-- 统计不同的id的个数
select count(distinct id) from table_1-- 优化版本的count distinct
select count(*) from
(select distinct id from table_1) tb
distinct 会对结果集去重,对全部选择字段进行去重,并不能针对其中部分字段进行去重。使用count distinct进行去重统计会将reducer数量强制限定为1,而影响效率,因此适合改写为子查询。
-- 统计不同性别(F、M)中,不同的id个数
select count(distinct id) from table_1
group by sex
-- 其它的聚合函数例如:max/min/avg/sum-- 统计最大/最小/平均年龄
select max(age), min(age),avg(age) from
table_1
group by id
聚合函数帮助我们进行基本的数据统计,例如计算最大值、最小值、平均值、总数、求和
-- 统计A公司的男女人数
select count(distinct id) from table_1
where company = 'A'
group by sex-- 统计各公司的男性平均年龄,并且仅保留平均年龄30岁以上的公司
select company, avg(age) from table_1
where sex = 'M'
group by company
having avg(age)>30;
-- 按年龄全局倒序排序取最年迈的10个人
select id,age from table_1 order by age DESC
limit 10
-- 收入区间分组
select id,
(case when CAST(salary as float)<50000 Then &#39;0-5万&#39;
when CAST(salary as float)>&#61;50000 and CAST(salary as float)<100000 then &#39;5-10万&#39;
when CAST(salary as float) >&#61;100000 and CAST(salary as float)<200000 then &#39;10-20万&#39;
when CAST(salary as float)>200000 then &#39;20万以上&#39;
else NULL end
from table_1;
在这个例子里也穿插了一个CAST的用法&#xff0c;它常用于string/int/double型的转换。
1. concat( A, B...)返回将A和B按顺序连接在一起的字符串&#xff0c;如&#xff1a;concat(&#39;foo&#39;, &#39;bar&#39;) 返回&#39;foobar&#39;
select concat(&#39;www&#39;,&#39;.iteblog&#39;,&#39;.com&#39;) from
iteblog;
--得到 www.iteblog.com
2. split(str, regex)用于将string类型数据按regex提取&#xff0c;分隔后转换为array。
-- 以","为分隔符分割字符串&#xff0c;并转化为array
Select split("1,2,3",",")as value_array from table_1;
-- 结合array index,将原始字符串分割为3列
select value_array[0],value_array[1],value_array[2] from
(select split("1,2,3",",")as value_array from table_1 )t
3. substr&#xff08;str,0,len) 截取字符串从0位开始的长度为len个字符。
select substr(&#39;abcde&#39;,3,2) from
iteblog;-- 得到cd
3. 基础进阶
-- 按照字段salary倒序编号
select *, row_number() over (order by salary desc) as row_num from table_1;-- 按照字段deptid分组后再按照salary倒序编号
select *, row_number() over (partition by deptid order by salary desc) as rank from table_1;
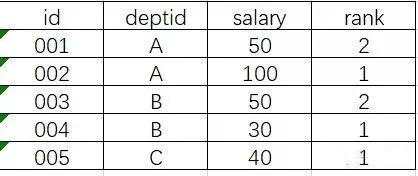
按照depid分组&#xff0c;对salary进行排序&#xff08;倒序&#xff09;除了row_number函数之外&#xff0c;还有两个分组排序函数&#xff0c;分别是rank() 和dense_rank()。
rank()排序相同时会重复&#xff0c;总数不会变 &#xff0c;意思是会出现1、1、3这样的排序结果&#xff1b;
dense_rank() 排序相同时会重复&#xff0c;总数会减少&#xff0c;意思是会出现1、1、2这样的排序结果。
row_number() 则在排序相同时不重复&#xff0c;会根据顺序排序。
-- 获取income字段的top10%的阈值
select percentile(CAST (salary AS int),0.9)) as income_top10p_threshold from table_1;-- 获取income字段的10个百分位点
select percentile(CAST (salary AS int),array(0.0,0.1,0.2,0.3,0.4,0.5,0.6,0.7,0.8,0.9,1.0)) as income_percentiles
from table_1;
-- 转换为时间数据的格式
select to_date("1970-01-01 00:00:00") as start_time from table_1;-- 计算数据到当前时间的天数差
select datediff
(&#39;2016-12-30&#39;,&#39;2016-12-29&#39;);
-- 得到 "1"
to_date函数可以把时间的字符串形式转化为时间类型&#xff0c;再进行后续的计算&#xff1b;
常用的日期提取函数包括 year()/month()/day()/hour()/minute()/second()
日期运算函数包括datediff(enddate,stratdate) 计算两个时间的时间差&#xff08;day)&#xff1b;
date_sub(stratdate,days) 返回开始日期startdate减少days天后的日期。
date_add(startdate,days) 返回开始日期startdate增加days天后的日期。
4. 常见笔试/面试题
例&#xff1a;有3个表S&#xff0c;C&#xff0c;SC&#xff1a;
S&#xff08;SNO&#xff0c;SNAME&#xff09;代表&#xff08;学号&#xff0c;姓名&#xff09;
C&#xff08;CNO&#xff0c;CNAME&#xff0c;CTEACHER&#xff09;代表&#xff08;课号&#xff0c;课名&#xff0c;教师&#xff09;
SC&#xff08;SNO&#xff0c;CNO&#xff0c;SCGRADE&#xff09;代表&#xff08;学号&#xff0c;课号&#xff0c;成绩&#xff09;
问题&#xff1a;
1. 找出没选过“黎明”老师的所有学生姓名。
2. 列出2门以上&#xff08;含2门&#xff09;不及格学生姓名及平均成绩。
3. 既学过1号课程又学过2号课所有学生的姓名。
1. -- 考察条件筛选
select sname from s where sno not in
( select sno from sc where cno in (
select distinct cno from c where cteacher&#61;&#39;黎明&#39; )
);2. -- 考察聚合函数&#xff0c;条件筛选
select s.sname, avg_grade from s
join
(select sno from sc where scgrade <60 group by sno having count(*) >&#61; 2) t1
on s.sno &#61; t1.sno
join
(select sno, avg(scgrade) as avg_grade from sc group by sno ) t2
on s.sno &#61; t2.sno;3. -- 考察筛选、连接
select sname from( select sno from sc where cno &#61; 1) a
join (select sno from sc where cno &#61; 2) b
on a.sno &#61; b.sno
做SQL题的时候注意理解每个题目希望你用的是什么知识点&#xff0c;这样有助于巩固。
当初我学SQL的时候&#xff0c;盯着《SQL必知必会》翻来覆去的看&#xff0c;但是知识点真的比较多&#xff0c;也比较零碎。在写这篇文章之前&#xff0c;也看过知乎上关于SQL学习的文章&#xff0c;有的比较广泛而全面&#xff0c;有的则很干货&#xff0c;全部是牛客上的SQL题目的解析。
基于自己的体会&#xff0c;我写了这篇SQL面试和笔试的入门文章&#xff0c;主旨是快速、清晰的把握重点。希望大家都能快快入门SQL~
延伸阅读
同同同期群分析到底是个啥&#xff1f; Pandas熟练&#xff1f;进来测测这50道题吧&#xff01; 实战解读&#xff1a;数据分析&#xff0c;如何更进一步&#xff1f;
数据不吹牛读者群已经建立&#xff0c;后台回复“入群”&#xff0c;即可加入有趣讨论&#xff0c;交流数据干货
“多来点干货&#xff01;”








 京公网安备 11010802041100号
京公网安备 11010802041100号