作者:Jessica_猪猪到_697 | 来源:互联网 | 2023-08-17 10:54
1、数据分区
1.1 通过时间列将大表分为多个小表,缩小数据范围,减少扫描纪录数,这样添加分区索引后存在多个B+索引,单分区查询时相对应索引树也小
1.1.1 在本地任意盘符下创建存放小表的文件夹
1.1.2 通过SQLServerManagement创建数据库文件组
数据库右键--属性--文件组--添加文件组 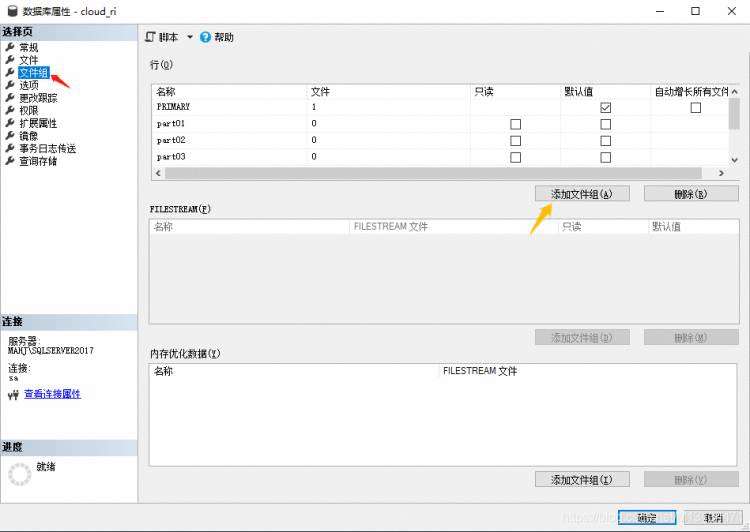
1.1.3 创建数据库文件
数据库右键--属性--文件组--添加文件组--添加文件逻辑名称--选择文件对应存放的文件组--选择文件存放路径

1.1.4 创建分区函数,告诉SQLServer以什么规则对分区表进行分区
分区表1:2020-1-1以前的数据(不包含2020-1-1)。
分区表2:2020-1-1(包含2020-1-1)到2020-1-31之间的数据。
分区表3:2020-2-1(包含2020-2-1)到2020-2-29之间的数据。
分区表4:2020-3-1(包含2020-3-1)到2020-3-31之间的数据。
分区表5:2020-4-1(包含2020-4-1)到2020-4-30之间的数据。
分区表6:2020-5-1(包含2020-5-1)之后的数据。
CREATE PARTITION FUNCTION part(datetime)
AS RANGE RIGHT FOR VALUES ('20200101','20200201','20200301','20200401','20200501')
CREATE PARTITION FUNCTION是创建一个分区函数。
part为分区函数名称。
AS RANGE RIGHT为设置分区范围的方式为Right,也就是右置方式。
FOR VALUES ('xx','xx','xx','xx','xx')为按这几个值来分区,分区条件。
为什么值“ 20200201”会放在表2中,而不是表1中,这是由AS RANGE RIGHT中的RIGHT所决定的,RIGHT的意思是将等于这个值的数据放在右边的那个表里,也就是表2中。如果您的SQL语句中使用的是Left而不是RIGHT,那么就会放在左边的表中,也就是表1中。
1.1.4 创建分区方案,分区方案的作用是将分区函数生成的分区映射到文件组中去,告诉SQLServer已分区的数据放在那个文件组下。
CREATE PARTITION SCHEME partsch
AS PARTITION part
TO ( part01, part02, part03, part04, part05,part06)
CREATE PARTITION SCHEME意思是创建一个分区方案。
partschSale为分区方案名称。
AS PARTITION partfunSale说明该分区方案所使用的数据划分条件(也就是所使用的分区函数)为partfunSale。
TO后面的内容是指partfunSale分区函数划分出来的数据对应存放的文件组。
1.1.4 查看方案与函数
脚本执行完成后展开数据库目录,“存储”下的分区方案、分区函数中查看。
1.1.5 创建分区表
CREATE TABLE Sale(
[Id] [int] IDENTITY(1,1) NOT NULL,
[time][datetime] NOT NULL
) ON partsch([time])
ON partsch 表明关联名为partsch的分区方案,括号中为分区条件字段。
1.1.4 普通表转为分区表
--删掉主键
ALTER TABLE 表名 DROP constraint 主键名
--创建主键,但不设为聚集索引
ALTER TABLE 表名 ADD CONSTRAINT 主键名 PRIMARY KEY NONCLUSTERED
(
[ID] ASC
) ON [PRIMARY]
--创建一个新的聚集索引,在该聚集索引中使用分区方案
CREATE CLUSTERED INDEX 索引名 ON 表名(列名) ON 分区方案名([分区索引列名])
1.1.4 查询
每个物理分区表中存放了哪些记录,可以使用$PARTITION函数。
2、索引
2.1 SQLServer索引分类
索引就类似于中文字典前面的目录,按照拼音或部首都可以很快的定位到所要查找的字。
唯一索引(UNIQUE):每一行的索引值都是唯一的(创建了唯一约束,系统将自动创建唯一索引)
主键索引:当创建表时指定的主键列,会自动创建主键索引,并且拥有唯一的特性。
聚集索引(CLUSTERED):聚集索引就相当于使用字典的拼音查找,因为聚集索引存储记录是物理上连续存在的,即拼 音 a 过了后面肯定是 b 一样。
非聚集索引(NONCLUSTERED):非聚集索引就相当于使用字典的部首查找,非聚集索引是逻辑上的连续,物理存储并 不连续。
聚集索引一个表只能有一个,而非聚集索引一个表可以存在多个。
2.2 添加位置
单表查询在where列添加对应索引。
多表关联查询在关联表的两列分别对应索引,where条件列添加索引,根据条件数量选择对应索引,不易添加过多索引占 用索引空间,会导致添加、修改时的效率底下。
注意:部分sql函数以及条件判断式,多变关联查询时主表、子表逻辑顺序前后等sql语句写法都会导致索引失效。
目的是为了减少sql语句执行时全盘扫描的现象,按照定义好的逻辑以最小开销查询出期望数据才能显著提高查询语句的 效率。
3、完
主表一千万左右数据,子表一千四百多万数据加五张关联表,多表联查时sql效率显著提升!



![[c++基础]STL](https://img.php1.cn/3c972/1edc8/c5a/a04ecc977fd8ed28.jpeg)





 京公网安备 11010802041100号
京公网安备 11010802041100号