作者:平凡屋之换 | 来源:互联网 | 2023-02-03 17:36
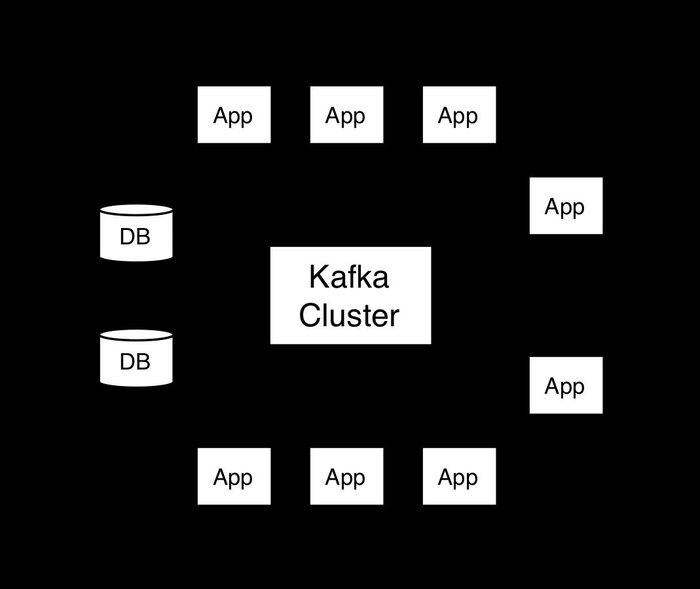
今天就跟大家聊聊有关如何验证 Kafka 系统的可靠性,可能很多人都不太了解,为了让大家更加了解,小编给大家总结了以下内容,希望大家根据这篇文章可以有所收获。
当通过 Kafka 构建的系统需要提供特定的可靠性,我们对 Kafka 做了相应配置,对生产者和消费者的应用做了必要的处理之后,如何验证整个系统确实实现了期望的可靠性呢?
1. 概述
仍然是那句话,可靠性不是一个可以轻易获得的东西,验证的方法也不简单,分为三个阶段:
在没有生产者和消费者参与的情况下,对 Kafka 的配置进行验证,确认 Kafka 的表现与预期一致;
加入生产者和消费者的应用,确认生产者和消费者的表现和预期一致;
应用上线后,对应用和 Kafka 的指标、日志等进行监控,发现与可靠性有关的问题,进行修复。
2. 验证配置
验证:其实就是测试,实际效果和预期效果是否一致,因此在验证前必须确认期望看到的结果,如果这一步有误差,验证可能很难成功。
验证配置不是指用肉眼去确认配置文件是否正确,而是使用 Kafka 提供的工具,Kafka 在 org.apacha.kafka.tools 包下有两个类:VerifiableProducer 和 VerifiableConsumer,这两个类既可以通过命令行运行,也可以在各种测试框架中使用。
VerifiableProducer 可以按照我们指定的参数来发送一定数量的消息,消息内容为从 1 开始递增的数字,参数包括 acks,重试次数和发送速率等等,运行时会打印每条消息发送成功或失败。VerifiableConsumer 消费 VerifiableProducer 生产的消息,按照消费顺序打印消息内容,并且打印提交 offset 和分区重分配的消息。
下面来实战一下,先看下这两个命令行工具都有哪些参数:


因为我也是第一次使用,所以我就随便选几个参数设置一下:
使用 VerifiableProducer 发送数据:

然后用 VerifiableConsumer 接收收据:

因为将 max-messages 设置为 10,而 topic 中只有 5 条消息,所以没有退出。
以上只是演示,因为 broker 只有一台,而且非常稳定,实际测试时需要构建更复杂的场景:
leader 选举,关掉 leader 所在的 broker,producer 和 consumer 需要多长时间恢复?
controller 选举,重启 controller,整个系统需要多长时间恢复?
滚动重启,一台一台的重启 broker,能否做到一条消息都不丢失?
脏 leader 选举,当发生了脏 leader 选举时,producer 和 consumer 会发生什么,能否接受后果?
根据实际的需要去构建测试场景,当测试都通过之后可以进入下一步。
3. 验证应用
其实这一步的验证方法和上一步非常类似,唯一的区别是:生产者和消费者替换成了自己开发的应用代码,保持 Kafka 的配置不变,启动应用中的生产和消费者,在构建的场景中测试,比如:
生产者和消费者与 Kafka 集群断开网络
发生了 leader 选举
broker 进行滚动重启
消费者进行滚动重启
生产者进行滚动重启
如果测试结果不符合预期,找到原因,修复它,全部验证通过后,进入下一步。
4. 线上监控
这一步非常重要,因为万一前两步有所疏漏,或者来不及做,监控可以确保及时发现问题,避免损失。
监控的内容可以包括:JMX、日志以及其它更复杂的自定义的指标。
JMX 监控
Kafka 自带了 JMX 监控,对于broker,生产者和消费者,分别有不同的指标可以关注。
对于 broker,值得监控的指标很多,比如达不到 ISR 最小副本数的分区个数,正在同步的分区副本数,下线分区数,controller 数量,失败的生产请求数,leader 选举次数和时间等等,都很重要。
对于生产者,两个和可靠性相关的指标是每条消息的平均错误率和平均重试率,这两个指标如果上升了,表明系统肯定是出了问题。
对于消费者,最重要的指标是消费 lag,它表明了这个消费者当前消费到的位置落后于这个 topic 的各个分区最新消息有多远,理想情况是在 0 和一个很小的值之间波动,如果增大到一定的阈值,则需要进行处理。
日志监控
Kafka 的日志监控和其它应用的日志监控区别不大,关注日志中出现的 WARN 和 ERROR,任何异常都有可能影响可靠性。
其它监控
如果不满足于 JMX 监控和日志监控,可以自己扩展或增加其它的监控,JMX 报告的指标是可以扩展的,日志的内容也是可以增加的,但可能需要修改源码。
监控系统
一般来说,Kafka 的监控任务应当由专门的监控和运维故障管理系统来完成,我用过两个系统来监控 Kafka:小米的 Open-Falcon 和 InfluxData 的 Telegraf + InfluxDB + Grafana 套件。都还行,可以比较灵活的定制想要监控的内容,同时支持多种报警方式,比如 Open-Falcon 支持邮件和微信报警,而 Grafana 的页面美观性相当不错,其它应当还有不少,但是我没有用过就不胡扯了。
看完上述内容,你们对如何验证 Kafka 系统的可靠性有进一步的了解吗?如果还想了解更多知识或者相关内容,请关注编程笔记行业资讯频道,感谢大家的支持。





 京公网安备 11010802041100号
京公网安备 11010802041100号