看到了kylin关于cube的设计,难以抑制的觉得这部分设计得太巧妙了,确实比我们的产品要好上很多,不得不学习一下!!!
本文不是从实例的角度,来分析如何构建一个数据立方体,而是从BI的产品角度出发,如何构建起一个更好的数据立方体系统。
概念部分
本部分以概念介绍为主,了解的同学请跳过。
数据立方体是一种多维数据模型,下面介绍一下多维模型的相关概念:
• 多维数据模型:为了满足用户从多角度多层次进行数据查询和分析的需要而建立起来的基于事实表和维度表的数据库模型,其基本的应用是为了实现OLAP(Online Analytical Processing)
• 立方体:它是由维度构建出来的多维空间,包含了所要分析的基础数据,所有的聚合数据操作都在它上面进行
• 维度:观察数据的一种角度,比如在上图中address、item、time都可以被看作一个维度,直观上来看维度是一个立方体的轴,比如三个维度可以构成一个立方体的空间
• 维度成员:构成维度的基本单位,比如对于time维,包含Q1、Q2、Q3、Q4四个维度成员
• 层次:维度的层次结构,它存在两种:自然层次和用户自定义层次。比如对于时间维,可以分为年、月、日三个层次,也可以分为年、季度、月三个层次。一个维可以有多个层次,它是单位数据聚集的一种路径
• 级别:级别组成层次,比如年、月、日分别是时间维的三个级别
• 度量:一个数值函数,可以对数据立方体空间中的每个点求值;度量值自然就是度量的结果
• 事实表:存放度量值得表,同时存放了维表得外键,所有分析所用得数据最终都来自事实表
• 维表:对于维度的描述,每个维度对应一个或多个维表,一个维度对应一个表的是星型模式,对应多个表的是雪花模式
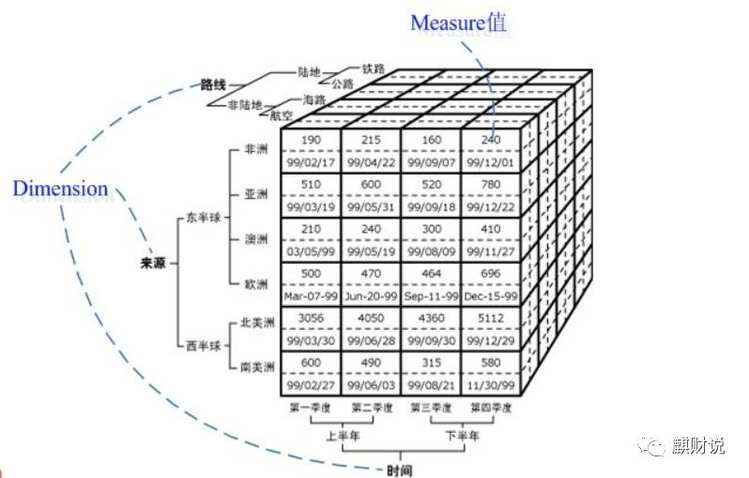
数据立方体只是多维模型的一种形象的说法,它只有三维,但多维数据模型不仅限于三维,它可以是n维的。之所以这么叫是为了让用户更容易想象,方便解释和说明,同时也为了和传统的关系数据库中的二维表进行区分。所以,我们可以把任意的n维数据立方体看做是(n-1)维立方体的序列,比如可以将4-D立方体看做是3-D立方体的序列

多维数据模型的模式主要有星形模式、雪花模式和事实星座模式。
星形模式
它是最常见的模式,它包括一个大的中心表(事实表),包含了大批数据但是不冗余;一组小的附属表(维表),每维一个。如下所示,从item、time、branch、location四个维度去观察数据,中心表是Sales Fact Table,包含了四个维表的标识符(由系统产生)和三个度量。
每一维使用一个表表示,表中的属性可能会形成一个层次或格。

雪花模式
它是星模式的变种,将其中某些表规范化,把数据进一步的分解到附加的表中,形状类似雪花。
如下所示,item这个维表被规范化,生成了新的item表和supplier表;同样location也被规范化为location和city两个新的表。

事实星座
允许多个事实表共享维表,可以看作是星形模式的汇集。如下所示,Sales和Shipping两个事实表共享了time、item、location三个维表。

总体来说,在数据仓库中多用事实星座模式,因为它能对多个相关的主题建模;而在数据集市流行用星形或雪花模式,因为它往往针对于某一个具体的主题。
OLAP的多维分析操作包括:钻取(Drill-down)、上卷(Roll-up)、切片(Slice)、切块(Dice)以及旋转(Pivot),下面还是以上面的数据立方体为例来逐一解释下:

钻取(Drill-down):在维的不同层次间的变化,从上层降到下一层,或者说是将汇总数据拆分到更细节的数据,比如通过对2010年第二季度的总销售数据进行钻取来查看2010年第二季度4、5、6每个月的消费数据,如上图;当然也可以钻取浙江省来查看杭州市、宁波市、温州市……这些城市的销售数据。
上卷(Roll-up):钻取的逆操作,即从细粒度数据向高层的聚合,如将江苏省、上海市和浙江省的销售数据进行汇总来查看江浙沪地区的销售数据,如上图。
切片(Slice):选择维中特定的值进行分析,比如只选择电子产品的销售数据,或者2010年第二季度的数据。
切块(Dice):选择维中特定区间的数据或者某批特定值进行分析,比如选择2010年第一季度到2010年第二季度的销售数据,或者是电子产品和日用品的销售数据。
旋转(Pivot):即维的位置的互换,就像是二维表的行列转换,如图中通过旋转实现产品维和地域维的互换。
Kylin的Cube算法
以下内容为全文引用,有兴趣的同学可以去参考连接查看原文。
Layer Cubing算法
也可称为“逐层算法”,通过启动N+1轮MapReduce计算。第一轮读取原始数据(RawData),去掉不相关的列,只保留相关的。同时对维度列进行压缩编码,第一轮的结果,我们称为Base Cuboid,此后的每一轮MapReuce,输入是上一轮的输出,以重用之前的计算结果,去掉要聚合的维度,计算出新的Cuboid,以此向上,直到最后算出所有的Cuboid。

如上图所示,展示了一个4维的Cube构建过程
此算法的Mapper和Reducer都比较简单。Mapper以上一层Cuboid的结果(Key-Value对)作为输入。由于Key是由各维度值拼接在一起,从其中找出要聚合的维度,去掉它的值成新的Key,并对Value进行操作,然后把新Key和Value输出,进而Hadoop MapReduce对所有新Key进行排序、洗牌(shuffle)、再送到Reducer处;Reducer的输入会是一组有相同Key的Value集合,对这些Value做聚合计算,再结合Key输出就完成了一轮计算。
每一轮的计算都是一个MapReduce任务,且串行执行;一个N维的Cube,至少需要N次MapReduce Job。
算法优点
此算法充分利用了MapReduce的能力,处理了中间复杂的排序和洗牌工作,故而算法代码清晰简单,易于维护;
受益于Hadoop的日趋成熟,此算法对集群要求低,运行稳定;在内部维护Kylin的过程中,很少遇到在这几步出错的情况;即便是在Hadoop集群比较繁忙的时候,任务也能完成。
算法缺点
当Cube有比较多维度的时候,所需要的MapReduce任务也相应增加;由于Hadoop的任务调度需要耗费额外资源,特别是集群较庞大的时候,反复递交任务造成的额外开销会相当可观;
由于Mapper不做预聚合,此算法会对Hadoop MapReduce输出较多数据; 虽然已经使用了Combiner来减少从Mapper端到Reducer端的数据传输,所有数据依然需要通过Hadoop MapReduce来排序和组合才能被聚合,无形之中增加了集群的压力;
对HDFS的读写操作较多:由于每一层计算的输出会用做下一层计算的输入,这些Key-Value需要写到HDFS上;当所有计算都完成后,Kylin还需要额外的一轮任务将这些文件转成HBase的HFile格式,以导入到HBase中去;
总体而言,该算法的效率较低,尤其是当Cube维度数较大的时候;时常有用户问,是否能改进Cube算法,缩短时间。
Fast(in-mem) Cubing算法
也被称作“逐段”(By Segment) 或“逐块”(By Split) 算法
从1.5.x开始引入该算法,利用Mapper端计算先完成大部分聚合,再将聚合后的结果交给Reducer,从而降低对网络瓶颈的压力。
主要思想
对Mapper所分配的数据块,将它计算成一个完整的小Cube 段(包含所有Cuboid);
每个Mapper将计算完的Cube段输出给Reducer做合并,生成大Cube,也就是最终结果;下图解释了此流程

与旧算法的不同之处
举一个例子
一个cube有4个维度:A,B,C,D;每个Mapper都有100万个源记录要处理;Mapper中的列基数是Car(A),Car(B),Car(C)和Car(D);
当将源记录聚集到base cuboid(1111)时,使用旧的“逐层”算法,Mapper将向Hadoop输出1百万条记录;使用快速立方算法,在预聚合之后,它只向Hadoop输出[distinct A,B,C,D]记录的数量,这肯定比源数据小;在正常情况下,它可以是源记录大小的1/10到1/1000;
当从父cuboid聚合到子cuboid时,从base cuboid(1111)到3维cuboid 0111,将会聚合维度A;我们假设维度A与其他维度是独立的,聚合后,cuboid 0111的维度约为base cuboid的1 / Card(A);所以在这一步输出将减少到原来的1 / Card(A)。
总的来说,假设维度的平均基数是Card(N),从Mapper到Reducer的写入记录可以减少到原始维度的1 / Card(N); Hadoop的输出越少,I/O和计算越少,性能就越好。
子立方体生成树(Cuboid Spanning Tree)的遍历次序
在旧算法中,Kylin按照层级,也就是广度优先遍历(Broad First Search)的次序计算出各个Cuboid;在快速Cube算法中,Mapper会按深度优先遍历(Depth First Search)来计算各个Cuboid。深度优先遍历是一个递归方法,将父Cuboid压栈以计算子Cuboid,直到没有子Cuboid需要计算时才出栈并输出给Hadoop;最多需要暂存N个Cuboid,N是Cube维度数。
采用DFS,是为了兼顾CPU和内存:
从父Cuboid计算子Cuboid,避免重复计算;
只压栈当前计算的Cuboid的父Cuboid,减少内存占用。

上图是一个四维Cube的完整生成树;
按照DFS的次序,在0维Cuboid 输出前的计算次序是 ABCD -> BCD -> CD -> D -> , ABCD, BCD, CD和D需要被暂存;在被输出后,D可被输出,内存得到释放;在C被计算并输出后,CD就可以被输出;ABCD最后被输出。
使用DFS访问顺序,Mapper的输出已完全排序(除了一些特殊情况),因为Cuboid ID位于行键的开始位置,而内部Cuboid中的行已排序:
1 2 3 4 5 6 7 8 9 10 11 12 13 | 0000
0001[D0]
0001[D1]
....
0010[C0]
0010[C1]
....
0011[C0][D0]
0011[C0][D1]
....
....
1111[A0][B0][C0][D0]
....
|
由于mapper的输出已经排序,Hadoop的排序效率会更高,
此外,mapper的预聚合发生在内存中,这样可以避免不必要的磁盘和网络I / O,并且减少了Hadoop的开销;
在开发阶段,我们在mapper中遇到了OutOfMemory错误;这可能发生在:
我们意识到Kylin不能认为Mapper总是有足够的内存;Cubing算法需要自适应各种情况;
当主动检测到OutOfMemory错误时,会优化内存使用并将数据spilling到磁盘上;结果是有希望的,OOM错误现在很少发生;
优缺点
优点
它比旧的方法更快;从我们的比较测试中可以减少30%到50%的build总时间;
它在Hadoop上产生较少的工作负载,并在HDFS上留下较少的中间文件;
Cubing和Spark等其他立方体引擎可以轻松地重复使用该立方体代码;
缺点
该算法有点复杂;这增加了维护工作;
虽然该算法可以自动将数据spill到磁盘,但它仍希望Mapper有足够的内存来获得最佳性能;
用户需要更多知识来调整立方体;
By-layer Spark Cubing算法
我们知道,RDD(弹性分布式数据集)是Spark中的一个基本概念。N维立方体的集合可以很好地描述为RDD,N维立方体将具有N + 1个RDD。这些RDD具有parent/child关系,因为parent RDD可用于生成child RDD。通过将父RDD缓存在内存中,子RDD的生成可以比从磁盘读取更有效。下图描述了这个过程

改进
Spark中Cubing的过程
下图DAG,它详细说明了这个过程:
在“Stage 5”中,Kylin使用HiveContext读取中间Hive表,然后执行一个一对一映射的“map”操作将原始值编码为KV字节。完成后Kylin得到一个中间编码的RDD。
在“Stage 6”中,中间RDD用一个“reduceByKey”操作聚合以获得RDD-1,这是base cuboid。接下来,在RDD-1上做一个“flatMap”(一对多map),因为base cuboid有N个子cuboid。以此类推,各级RDD得到计算。在完成时,这些RDD将完整地保存在分布式文件系统,但可以缓存在内存中用于下一级的计算。当生成子cuboid时,它将从缓存中删除。

性能测试


在所有这三种情况下,Spark都比MR快,总体而言,它可以减少约一半的时间。
不同Cubing算法的对比

参考连接:
https://blog.csdn.net/bbbeoy/article/details/79073725
https://blog.csdn.net/Forlogen/article/details/88634117
http://cxy7.com/articles/2018/06/09/1528549073259.html








 京公网安备 11010802041100号
京公网安备 11010802041100号