作者:阿芙2011 | 来源:互联网 | 2024-10-11 18:49
一、为什么要持久化:
防止消息丢失。
二、rmq消息持久化方式 :
在rmq中采用 CommitLog和ConsumeQueue 2个文件结合来持久化消息。其中CommitLog是用来存放消息实体的,文件位置在store/commitLog目录下,一个broker共用同一个commitlog目录下所有文件。consumeQueue是消息的索引文件,用来指示消息在commitLog中的具体位置,文件位置在store/consumeQueue目录下,在consumeQueue目录下,会根据topic和topic包含的queueId创建二级目录,然后在该目录下创建consumeQueue索引文件。
commitLog目录结构:
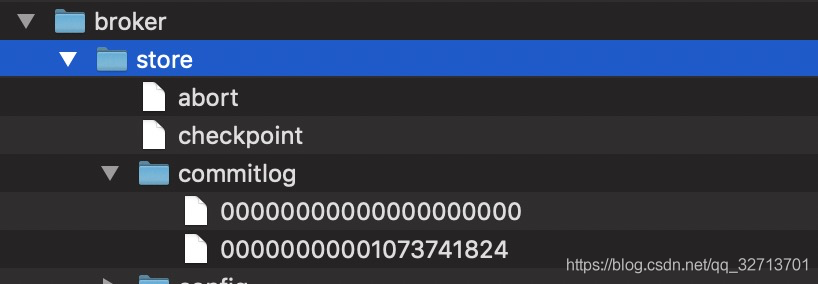
commitLog文件以文件起始字节数命名,图片中第二个文件的起始字节数为1073741824=2^30=1G,说明commitLog每个文件大小为1G,把文件大小控制在1G,和java NIO中MappperedByteBuffer文件内存映射限制有关系。
commitLog文件持久化协议:
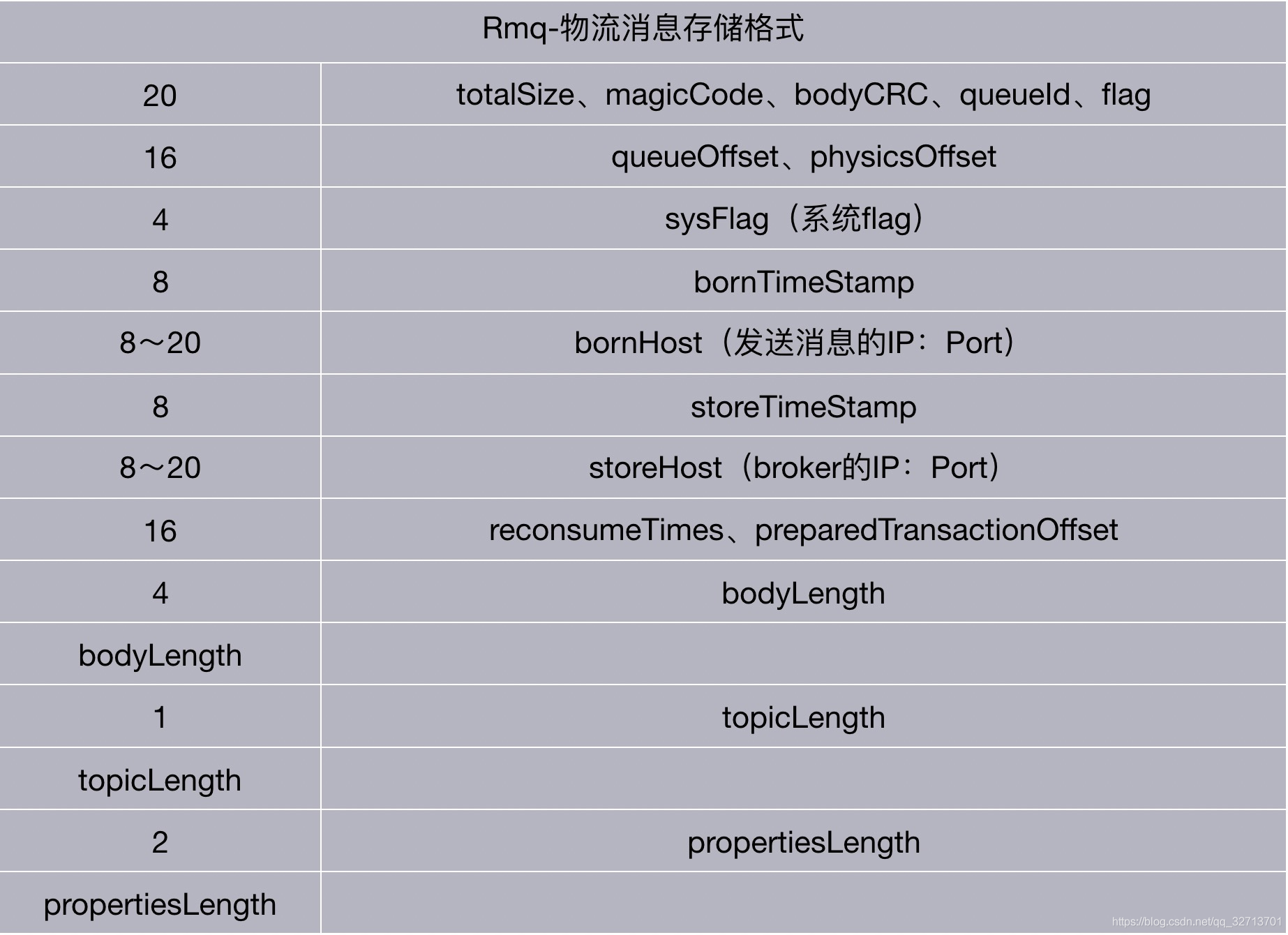
其中存放bodyLength为4个字节,可以计算出我们可以发送的最大消息体为2^23/2^20=4M
consumeQueue目录结构:
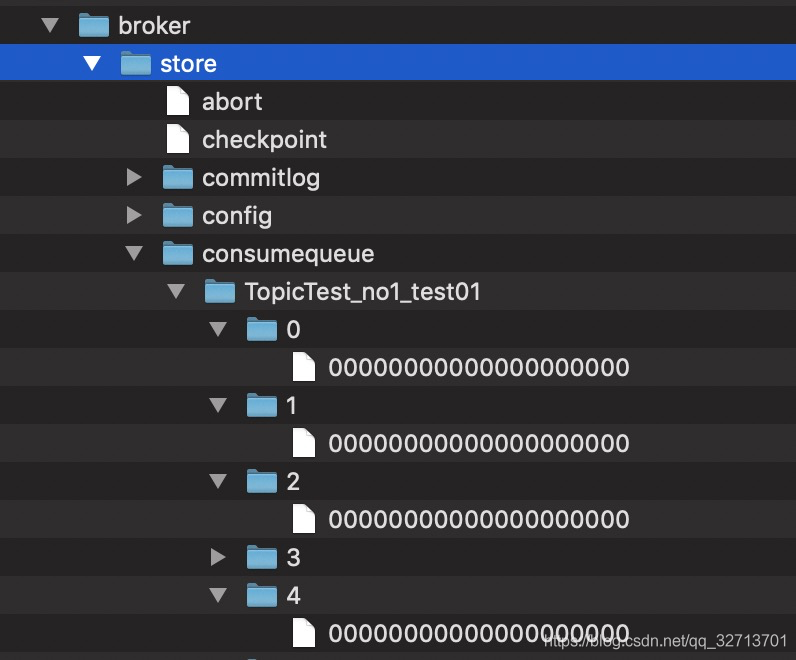
consumeQueue文件通过topic和queueId目录来加快索引速度,每个文件可以存放30W个消息索引,每个索引大小20Byte,那么每个索引文件大小为30 0000 * 20 Byte / 2^ 20 = 5.7M。
consumeQueue文件持久化协议:

consumeQueue文件中数据是以块存储的,每个块固定20Byte,其中offset为消息在CommitLog文件中的偏移量占8个Byte,size为消息体的大小占4个Byte,tagCode为消息体中tag的哈希值占8个Byte。
三、根据索引文件后去消息:
1、当我们拿到索引文件的一个数据块后,先取出前面八个字节 offset(消息在commitLog中起始地址。
2、计算消息所在的commitLog文件,offset / 1G (commitLog文件大小)获取到commitLog文件的序号。
3、通过序号获取对应的commitLog文件,计算相对起始位置,pos = offset - commitLog.formOffset (commitLog的起始字节数)。
4、通过起始位置和size获取对应的消息。
四、持久化和索引分开的目的:
1、设计初衷,顺序写入,随机读取。
2、顺序写入提升写入速度。
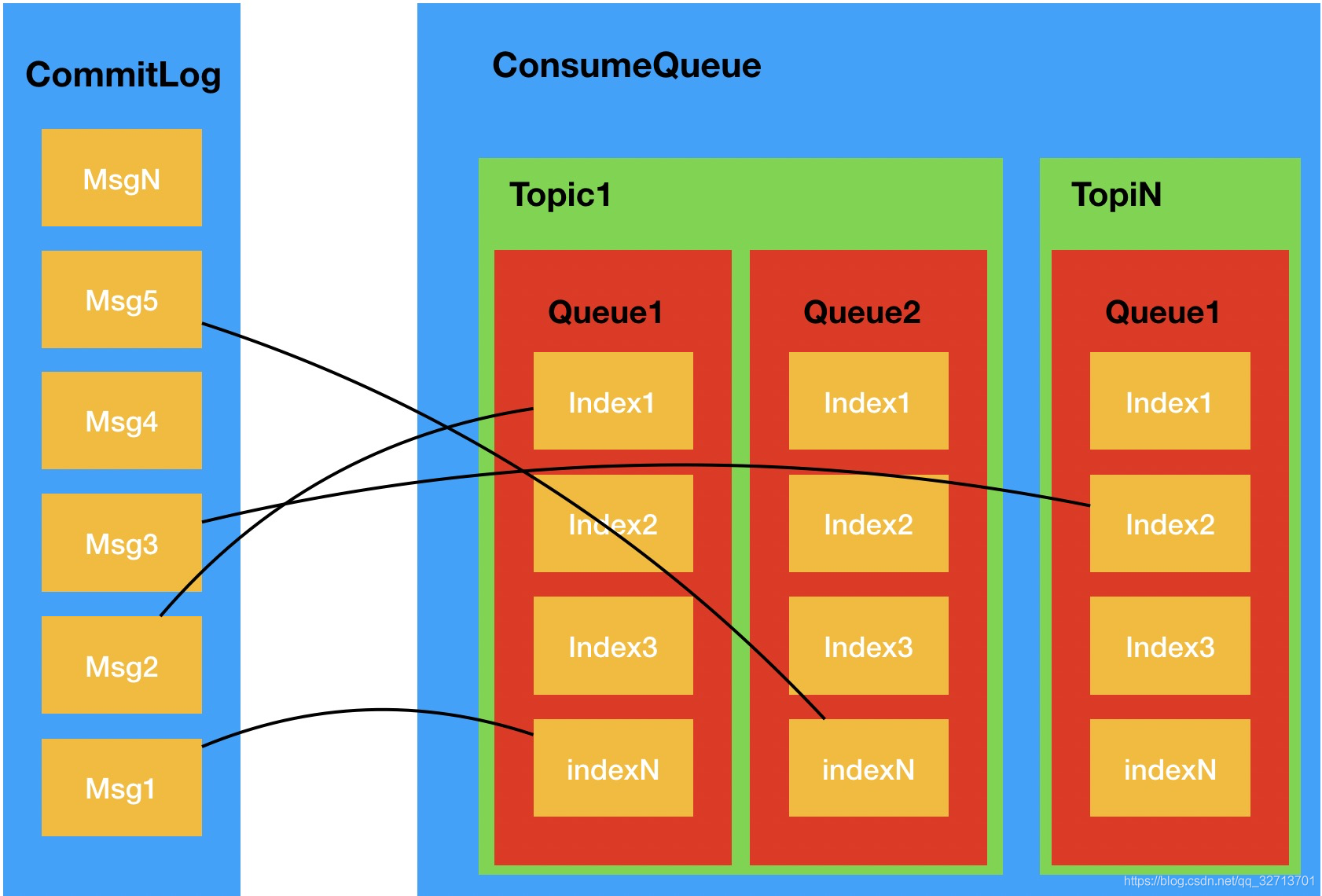
五、架构图:








 京公网安备 11010802041100号
京公网安备 11010802041100号