作者:大眼妹886 | 来源:互联网 | 2023-08-28 17:40
本系列文章主要介绍 RocketMQ 的相关知识,并通过示例代码介绍 RocketMQ 的使用方法。
本文为系列文章的第一篇,主要介绍 RocketMQ 的概要知识。
说明:本文的部分内容参考了 https://www.jianshu.com/p/3afd610a8f7d 文章的相关内容。
1 概述
首先,给出 GitHub 上 RocketMQ 项目的描述,内容如下:
Apache RocketMQ is a distributed messaging and streaming platform with low latency, high performance and reliability, trillion-level capacity and flexible scalability.
It offers a variety of features:
- Pub/Sub messaging model
- Scheduled message delivery
- Message retroactivity by time or offset
- Log hub for streaming
- Big data integration
- Reliable FIFO and strict ordered messaging in the same queue
- Efficient pull&push consumption model
- Million-level message accumulation capacity in a single queue
- Multiple messaging protocols like JMS and OpenMessaging
- Flexible distributed scale-out deployment architecture
- Lightning-fast batch message exchange system
- Various message filter mechanics such as SQL and Tag
- Docker images for isolated testing and cloud isolated clusters
- Feature-rich administrative dashboard for configuration, metrics and monitoring
RocketMQ 作为一款分布式的消息中间件,经历了 Metaq1.x、Metaq2.x 的发展和淘宝双十一的洗礼,证明其在功能和性能上远超 ActiveMQ。GitHub 上关于 RocketMQ 诞生的原因中,也说明了随着交易量的大幅度增长,ActiveMQ 到达了性能瓶颈,而其他流行的消息解决方案(如 Kafka)都不能满足其需求的情况下,才诞生了 RocketMQ。
RocketMQ 的优点如下:
- RocketMQ 原生就是支持分布式的,而 ActiveMQ 原生为单点性;
- RocketMQ 可以保证严格的消息顺序,而 ActiveMQ 无法保证;
- RocketMQ 提供亿级消息的堆积能力,这不是重点,重点是堆积了亿级的消息后,依然保持写入低延迟;
- 丰富的消息拉取模式(Push or Pull)。Push 模式好理解,比如在消费者端设置 Listener 回调;而 Pull 模式,控制权在于消费者,即消费者需要主动地调用拉消息方法从 Broker 获取消息,这里面就存在一个消费位置记录的问题(如果不记录,会导致消息重复消费);
- 在 Metaq1.x/2.x 的版本中,分布式协调采用的是 Zookeeper,而 RocketMQ 自己实现了一个 NameServer,这使得 RocketMQ 的分布式架构更加轻量级,性能更好;
- 消息失败重试机制、高效的订阅者水平扩展能力、强大的API、事务机制。
2 Producer/Consumer Group
ActiveMQ 中并没有 Group 这个概念,而在 RocketMQ 中存在 Group 的机制,理解该机制对于深入理解 RocketMQ 非常重要。
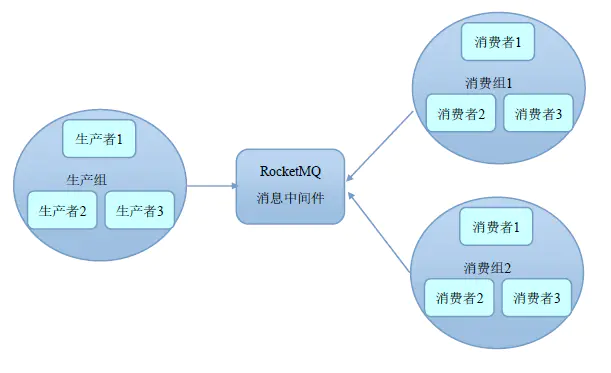
RocketMQ 通过 Group 机制,天然地支持了消息负载均衡。例如,某个 Topic 有 9 条消息,其中一个 Consumer Group 有 3 个实例(3 个进程/3 台机器),那么每个实例将均摊 3 条消息,由此实现了负载均衡。(注意:RocketMQ 只有一种模式,即发布订阅模式)
3 集群模式
RocketMQ 有多种 Broker 集群部署模式,常见的包括:单 Master 模式、多 Master 模式、多 Master 多 Slave 模式(异步复制)、多 Master 多 Slave 模式(同步双写)等。这里需要强调一下:RocketMQ 的 Slave 只能被消费者读取,不可以被生产者写入,类似于 MySQL 的主从机制。下面分别介绍这几种 Broker 集群部署模式。
3.1 单Master模式
很显然,单 Master 模式部署风险较大,一旦这个 Broker 重启或宕机,会导致整个服务不可用,通常线上环境都不会使用此模式。
3.2 多Master模式
集群中全是 Master,没有 Slave,例如 2 个 Master 或 3 个 Master。此时,如果某一个 Broker 重启或宕机,对应用是无影响的。此模式的缺点在于,当某个 Master 宕机时,该 Master 上未被消费的消息在 Master 恢复之前是不可以订阅的,消息的实时性会受到影响。
3.3 多Master多Slave模式(异步复制)
此模式下,有多个 Master,每个 Master 会配置一个或多个 Slave,由此实现了系统的高可用性。同时,Master 与 Slave 之间的消息同步,采用异步复制的方式,主备之间会短暂的消息延迟,这种延迟是 MS 级别的。如果 Master 宕机,消费者可以从 Slave 上进行消息消费,不影响消息实时性,但是由于 Master 的宕机,会导致丢失掉极少量(尚未同步到 Slave 上)的消息。
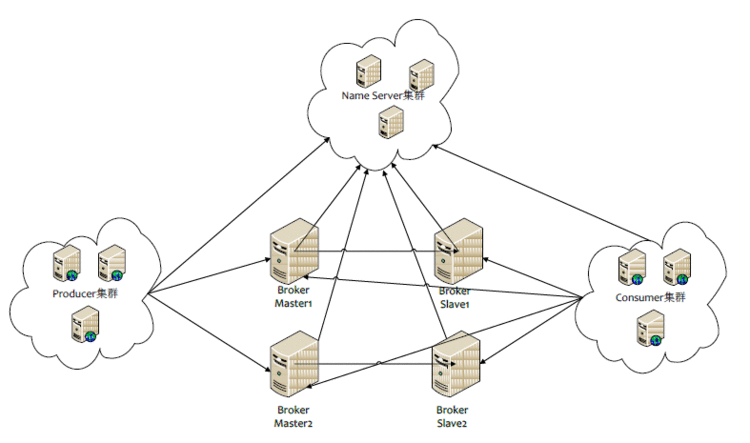
3.4 多Master多Slave模式(同步双写)
此模式下,有多个 Master,每个 Master 会配置一个或多个 Slave,由此实现了系统的高可用性。同时,Master 与 Slave 之间的消息同步,采用同步双写的方式,也就是在 Master 和 Slave 都写成功的前提下,才会向应用(生产者)返回成功。显然,此种模式下,无论是数据还是服务都不是单点的,所以服务与数据的可用性都非常高。此模式的缺点在于,性能会比异步复制稍低。
多 Master 多 Slave 模式的部署架构图,如下所示:
4 RocketMQ vs ActiveMQ vs Kafka
下面给出一张 RocketMQ、ActiveMQ 和 Kafka 的技术和特性的对比表,表内容如下:
| Messaging Product | Client SDK | Protocol and Specification | Ordered Message | Scheduled Message | Batched Message | BroadCast Message | Message Filter | Server Triggered Redelivery | Message Storage | Message Retroactive | Message Priority | High Availability and Failover | Message Track | Configuration | Management and Operation Tools |
|---|
| ActiveMQ | Java, .NET, C++ etc. | Push model, support OpenWire, STOMP, AMQP, MQTT, JMS | Exclusive Consumer or Exclusive Queues can ensure ordering | Supported | Not Supported | Supported | Supported | Not Supported | Supports very fast persistence using JDBC along with a high performance journal,such as levelDB, kahaDB | Supported | Supported | Supported, depending on storage,if using kahadb it requires a ZooKeeper server | Not Supported | The default configuration is low level, user need to optimize the configuration parameters | Supported |
| Kafka | Java, Scala etc. | Pull model, support TCP | Ensure ordering of messages within a partition | Not Supported | Supported, with async producer | Not Supported | Supported, you can use Kafka Streams to filter messages | Not Supported | High performance file storage | Supported offset indicate | Not Supported | Supported, requires a ZooKeeper server | Not Supported | Kafka uses key-value pairs format for configuration. These values can be supplied either from a file or programmatically. | Supported, use terminal command to expose core metrics |
| RocketMQ | Java, C++, Go | Pull model, support TCP, JMS, OpenMessaging | Ensure strict ordering of messages,and can scale out gracefully | Supported | Supported, with sync mode to avoid message loss | Supported | Supported, property filter expressions based on SQL92 | Supported | High performance and low latency file storage | Supported timestamp and offset two indicates | Not Supported | Supported, Master-Slave model, without another kit | Supported | Work out of box,user only need to pay attention to a few configurations | Supported, rich web and terminal command to expose core metrics |
5 Pull&Push模式
首先介绍一下 Push 和 Pull 两种消费模式,内容如下:
- Push 模式:由消息中间件(MQ 消息服务器代理)主动地将消息推送给消费者。采用 Push 方式的情况下,broker 可以尽可能实时地将消息发送给消费者进行消费,但是,在消费者的处理消息的能力较弱时(比如消费者端的业务系统处理一条消息的流程比较复杂、其中的调用链路比较多导致消费时间比较久,概括起来就是“慢消费问题”),broker 不断地向消费者 Push 消息,会导致消费者端的缓冲区溢出,从而产生异常;
- Pull 模式:由消费者主动向消息中间件(MQ 消息服务器代理)拉取消息。采用 Pull 方式时,重点是如何设置 Pull 消息的频率。例如,生产者可能在 1 分钟内连续生产了 1000 条消息,然后 2 小时内没有新消息产生,在这种情况下,如果每次 Pull 的时间间隔比较久,就会增加消息的延迟,即消息到达消费者的时间会加长,MQ 中消息的堆积量变大;反之,如果每次 Pull 的时间间隔较短,但是在一段时间内 MQ 中并没有任何消息可以消费,那么又会产生很多无效的 Pull 请求的 RPC 开销,影响 MQ 整体的网络性能(即“消息延迟与忙等待”)。
介绍完一般的 Push 与 Pull 消费方式后,再来看一下 RocketMQ 的这两种消费方式,内容如下:
- RocketMQ 的 Pull 方式下,Consumer 主动获取 MessageQueue 的 Set(集合),遍历该集合中的每一个队列,发送 Pull 的请求(参数中带有队列中的消息偏移量),同时需要 Consumer 端自己保存消息消费的 offset(偏移量)至本地变量中。由此可见,在 Pull 模式下,需要业务应用自身去完成比较多的事情,所以在实际应用中,Pull 方式用的较少;
- RocketMQ 的 Push 方式下,Consumer 注册了一个监听器,当 Consumer 收到消息时,会主动调用这个监听器完成消费,并进行相关的业务逻辑处理。由此可见,在 Push 方式下,业务应用代码只需要完成消息消费的代码逻辑即可,无需参与 MQ 本身的一些任务处理。
说明:RocketMQ 的 Push 方式本质上也属于 Pull 方式,因为当 Consumer 从 broker 成功获取到消息后,Consumer 需要调用监听器,主动去 broker 轮询拉取消息完成消费。这种 Push 方式既解决了普通的 Push 方式的“慢消费问题”,同时相对于纯 Pull 模式来说,在代码实现上又简单了许多。
正如上面的说明所述,RocketMQ 的消费方式(Pull 方式 和 Push 方式)本质上都是基于 Pull 方式的,即都是采用 consumer 轮询从 broker 拉取消息。而在轮询过程中,加入了一种长轮询机制(对普通轮询的一种优化),来平衡 Push/Pull 模型的各自缺点。长轮询机制的基本设计思路是:消费者如果第一次尝试 pull 消息失败(如 Broker 端没有可以消费的消息),Broker 并不立即给消费者客户端返回 Response 响应消息,而是先 hold 并挂起该请求(将请求保存至 pullRequestTable 本地缓存变量中),然后 Broker 端的后台独立线程 PullRequestHoldService 会从 pullRequestTable 本地缓存变量中不断地去取,具体的做法是查询待拉取消息的偏移量是否小于消费队列最大偏移量,如果条件成立则说明有新消息达到 Broker 端(这里,在 RocketMQ 的 Broker 端会有一个后台独立线程 ReputMessageService 不停地构建 ConsumeQueue/IndexFile 数据,同时取出 hold 住的请求并进行二次处理),则通过重新调用一次业务处理器 PullMessageProcessor 的处理请求方法 processRequest(),来重新尝试拉取消息(此处,每隔 5s 重试一次,默认长轮询整体的时间设置为 30s)。
RocketMQ 使用的这种长轮询机制(Pull 方式和 Push 方式都具有),解决了一般的 Push 方式的“慢消费问题”,同时,解决了一般的 Pull 方式的“消息延迟与忙等待问题”,并且,使用 RocketMQ 的 Push 机制,还可以减小消费者端的代码逻辑复杂度,所以 RocketMQ 的 Push 方式同时具有三个优点。
综上所述,在实际应用中,我们一般会采用 RocketMQ 的 Push 方式进行消息消费。
关于 RocketMQ 具体的部署方法,请参考本系列文章的第二篇。







 京公网安备 11010802041100号
京公网安备 11010802041100号