作者:天狼飞虎神印 | 来源:互联网 | 2023-09-07 14:47
Redisson中怎么实现Redis分布式锁,针对这个问题,这篇文章详细介绍了相对应的分析和解答,希望可以帮助更多想解决这个问题的小伙伴找到更简单易行的方法。
Redis几种架构
Redis发展到现在,几种常见的部署架构有:
我们首先基于这些架构讲解Redisson普通分布式锁实现,需要注意的是,只有充分了解普通分布式锁是如何实现的,才能更好的了解Redlock分布式锁的实现,因为Redlock分布式锁的实现完全基于普通分布式锁。
普通分布式锁
Redis普通分布式锁这个大家基本上只了解,本文不打算过多的介绍,上一篇文章《Redlock:Redis分布式锁最牛逼的实现》也讲的很细,并且也说到了几个重要的注意点。
所以直接show you the code,毕竟talk is cheap。
redisson版本
本次测试选择redisson 2.14.1版本。
单机模式
源码如下:
// 构造redisson实现分布式锁必要的Config
Config config = new Config();
config.useSingleServer().setAddress("redis://172.29.1.180:5379").setPassword("a123456").setDatabase(0);
// 构造RedissonClient
RedissonClient redissonClient = Redisson.create(config);
// 设置锁定资源名称
RLock disLock = redissonClient.getLock("DISLOCK");
boolean isLock;
try {
//尝试获取分布式锁
isLock = disLock.tryLock(500, 15000, TimeUnit.MILLISECONDS);
if (isLock) {
//TODO if get lock success, do something;
Thread.sleep(15000);
}
} catch (Exception e) {
} finally {
// 无论如何, 最后都要解锁
disLock.unlock();
}通过代码可知,经过Redisson的封装,实现Redis分布式锁非常方便,我们再看一下Redis中的value是啥,和前文分析一样,hash结构,key就是资源名称,field就是UUID+threadId,value就是重入值,在分布式锁时,这个值为1(Redisson还可以实现重入锁,那么这个值就取决于重入次数了):
172.29.1.180:5379> hgetall DISLOCK
1) "01a6d806-d282-4715-9bec-f51b9aa98110:1"
2) "1"
哨兵模式
即sentinel模式,实现代码和单机模式几乎一样,唯一的不同就是Config的构造:
Config config = new Config();
config.useSentinelServers().addSentinelAddress(
"redis://172.29.3.245:26378","redis://172.29.3.245:26379", "redis://172.29.3.245:26380")
.setMasterName("mymaster")
.setPassword("a123456").setDatabase(0);集群模式
集群模式构造Config如下:
Config config = new Config();
config.useClusterServers().addNodeAddress(
"redis://172.29.3.245:6375","redis://172.29.3.245:6376", "redis://172.29.3.245:6377",
"redis://172.29.3.245:6378","redis://172.29.3.245:6379", "redis://172.29.3.245:6380")
.setPassword("a123456").setScanInterval(5000);总结
普通分布式实现非常简单,无论是那种架构,向Redis通过EVAL命令执行LUA脚本即可。
Redlock分布式锁
那么Redlock分布式锁如何实现呢?以单机模式Redis架构为例,直接看实现代码:
Config config1 = new Config();
config1.useSingleServer().setAddress("redis://172.29.1.180:5378")
.setPassword("a123456").setDatabase(0);
RedissonClient redissonClient1 = Redisson.create(config1);
Config config2 = new Config();
config2.useSingleServer().setAddress("redis://172.29.1.180:5379")
.setPassword("a123456").setDatabase(0);
RedissonClient redissonClient2 = Redisson.create(config2);
Config config3 = new Config();
config3.useSingleServer().setAddress("redis://172.29.1.180:5380")
.setPassword("a123456").setDatabase(0);
RedissonClient redissonClient3 = Redisson.create(config3);
String resourceName = "REDLOCK";
RLock lock1 = redissonClient1.getLock(resourceName);
RLock lock2 = redissonClient2.getLock(resourceName);
RLock lock3 = redissonClient3.getLock(resourceName);
RedissonRedLock redLock = new RedissonRedLock(lock1, lock2, lock3);
boolean isLock;
try {
isLock = redLock.tryLock(500, 30000, TimeUnit.MILLISECONDS);
System.out.println("isLock = "+isLock);
if (isLock) {
//TODO if get lock success, do something;
Thread.sleep(30000);
}
} catch (Exception e) {
} finally {
// 无论如何, 最后都要解锁
System.out.println("");
redLock.unlock();
}最核心的变化就是RedissonRedLock redLock = new RedissonRedLock(lock1, lock2, lock3);,因为我这里是以三个节点为例。
那么如果是哨兵模式呢?需要搭建3个,或者5个sentinel模式集群(具体多少个,取决于你)。
那么如果是集群模式呢?需要搭建3个,或者5个cluster模式集群(具体多少个,取决于你)。
实现原理
既然核心变化是使用了RedissonRedLock,那么我们看一下它的源码有什么不同。这个类是RedissonMultiLock的子类,所以调用tryLock方法时,事实上调用了RedissonMultiLock的tryLock方法,精简源码如下:
public boolean tryLock(long waitTime, long leaseTime, TimeUnit unit) throws InterruptedException {
// 实现要点之允许加锁失败节点限制
int failedLocksLimit = failedLocksLimit();
List acquiredLocks = new ArrayList(locks.size());
// 实现要点之遍历所有节点通过EVAL命令执行lua加锁
for (ListIterator iterator = locks.listIterator(); iterator.hasNext();) {
RLock lock = iterator.next();
boolean lockAcquired;
try {
// 对节点尝试加锁
lockAcquired = lock.tryLock(awaitTime, newLeaseTime, TimeUnit.MILLISECONDS);
} catch (RedisConnectionClosedException|RedisResponseTimeoutException e) {
// 如果抛出这类异常,为了防止加锁成功,但是响应失败,需要解锁
unlockInner(Arrays.asList(lock));
lockAcquired = false;
} catch (Exception e) {
// 抛出异常表示获取锁失败
lockAcquired = false;
}
if (lockAcquired) {
// 成功获取锁集合
acquiredLocks.add(lock);
} else {
// 如果达到了允许加锁失败节点限制,那么break,即此次Redlock加锁失败
if (locks.size() - acquiredLocks.size() == failedLocksLimit()) {
break;
}
}
}
return true;
}很明显,这段源码就是上一篇文章《Redlock:Redis分布式锁最牛逼的实现》提到的Redlock算法的完全实现。
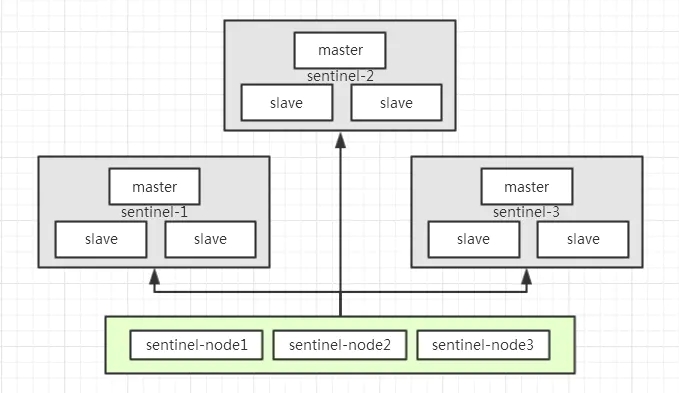
以sentinel模式架构为例,如下图所示,有sentinel-1,sentinel-2,sentinel-3总计3个sentinel模式集群,如果要获取分布式锁,那么需要向这3个sentinel集群通过EVAL命令执行LUA脚本,需要3/2+1=2,即至少2个sentinel集群响应成功,才算成功的以Redlock算法获取到分布式锁:
问题合集

根据上面实现原理的分析,这位同学应该是对Redlock算法实现有一点点误解,假设我们用5个节点实现Redlock算法的分布式锁。那么要么是5个redis单实例,要么是5个sentinel集群,要么是5个cluster集群。而不是一个有5个主节点的cluster集群,然后向每个节点通过EVAL命令执行LUA脚本尝试获取分布式锁,如上图所示。
失效时间如何设置
这个问题的场景是,假设设置失效时间10秒,如果由于某些原因导致10秒还没执行完任务,这时候锁自动失效,导致其他线程也会拿到分布式锁。
这确实是Redis分布式最大的问题,不管是普通分布式锁,还是Redlock算法分布式锁,都没有解决这个问题。也有一些文章提出了对失效时间续租,即延长失效时间,很明显这又提升了分布式锁的复杂度。另外就笔者了解,没有现成的框架有实现,如果有哪位知道,可以告诉我,万分感谢。
redis分布式锁的高可用
关于Redis分布式锁的安全性问题,在分布式系统专家Martin Kleppmann和Redis的作者antirez之间已经发生过一场争论。有兴趣的同学,搜索"基于Redis的分布式锁到底安全吗"就能得到你想要的答案,需要注意的是,有上下两篇(这应该就是传说中的神仙打架吧,哈)。
zookeeper or redis
没有绝对的好坏,只有更适合自己的业务。就性能而言,redis很明显优于zookeeper;就分布式锁实现的健壮性而言,zookeeper很明显优于redis。如何选择,取决于你的业务!
关于Redisson中怎么实现Redis分布式锁问题的解答就分享到这里了,希望以上内容可以对大家有一定的帮助,如果你还有很多疑惑没有解开,可以关注编程笔记行业资讯频道了解更多相关知识。





 京公网安备 11010802041100号
京公网安备 11010802041100号