篇首语:本文由编程笔记#小编为大家整理,主要介绍了技术|Resty-redis-cluster: 基于Openresty构建的rediscluster客户端相关的知识,希望对你有一定的参考价值。
初识OpenResty
第一次正式领略OpenResty是2017年初负责重构项目的API。原本项目基于tomcat+memcache的api latency在高峰期表现不稳定而且memcahce缓存穿透随着业务量增长也越发频繁。试测openresty+redis TPS翻了3番后(24core CPU上单节点18w tps),我们非常兴奋似乎找准了方案,但是公司之前没有太多openresty的案例。很庆幸当时的坚持以及兄弟team关于openresty一些成功经验的鼓励,最后项目的API顺利完成架构迁移并且averagetps都达到了1ms以下。
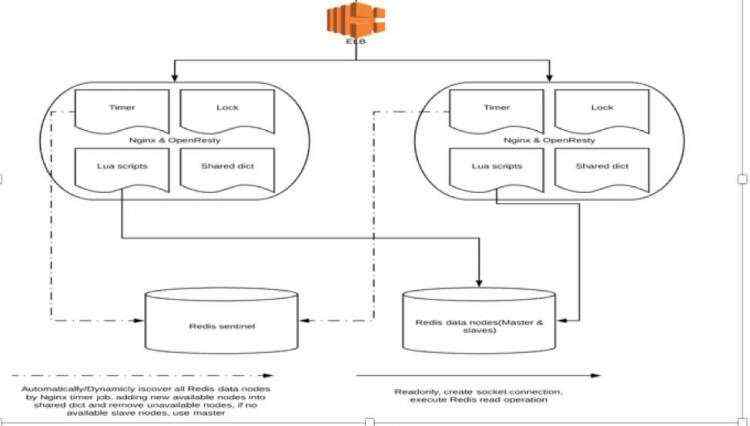
之后,team对openresty的经验积累也多了起来。我们设计了项目在AWS上的framework,以定期通过sentinel自动发现所有可用的redis节点并且存到shared dictionary里供所有openresty的process使用(ngxtimer+resty-lock+shared dictionary), 并且平稳从IDC过渡到AWS。架构图如下:
随着业务发展带来的数据量增长,master/slavesentinel的redis已经不能满足项目需要。目前官方的rediscluster已经越发成熟,优秀的横向扩展能力和无中心化架构使它被越来越多公司使用于实际生产环境,并且像常用的jedis/redisson/lettuce这样的客户端都对redis cluster支持。
问题是, openresty官方并没有支持redis cluster的client并且之后也没有明确schedule(https://github.com/openresty/lua-resty-redis/issues/43),在研究了一些第三方的client后我认为没有能满足项目实际生产可用的,那么,就自己造轮子吧,这样就有了resty-redis-cluster,目前已正式使用于生产环境并且运行稳定(https://github.com/steve0511/resty-redis-cluster)。

什么是OpenResty
"OpenResty® 是一个基于 nginx 与 Lua 的高性能Web 平台,其内部集成了大量精良的 Lua 库、第三方模块以及大多数的依赖项。用于方便地搭建能够处理超高并发、扩展性极高的动态 Web 应用、Web 服务和动态网关。
OpenResty® 通过汇聚各种设计精良的 Nginx 模块(主要由 OpenResty 团队自主开发),从而将 Nginx 有效地变成一个强大的通用Web 应用平台。这样,Web 开发人员和系统工程师可以使用 Lua 脚本语言调动 Nginx 支持的各种 C 以及 Lua 模块,快速构造出足以胜任 10K 乃至 1000K 以上单机并发连接的高性能Web 应用系统。"
目前openrestyOPM和https://github.com/bungle/awesome-resty已经收集了上百个developer贡献的module,resty-redis-cluster也是其中之一(awesome-resty Databases and Storages部分)。
OpenResty的运行原理
1. Nginx
和apache不同,openresty采用的是多进程单线程模型。对于每个worker进程来说,独立的进程,不需要加锁,没有锁和线程切换带来的开销。采用多进程模式另一个优点是进程之间不会互相影响,如果一个worker进程crash了,master进程很快会启动新的worker进程,服务并不会中断。(当然,worker进程崩溃有各种原因,比如openresty luajitVM crash,一定还是需要具体分析)
Nginx另一个优势是采用了非阻塞IO. nginx在初始化的时候会预分配出所有的网络read/write事件,每当有新连接到来时,就会把read/write事件跟对应的socket关联起来,然后放入epoll(或select/kqueue等等)事件队列中。nginx会一直(阻塞)等待事件队列 返回事件通知或者epoll_wait超时,一旦有事件触发,nginx就会调用关联的(read/write)handler处理事件。
Linux下nginx默认使用epoll模型。为了解决IO忙轮询CPU空转,Unix引入了Selector/Epoll, 在空闲的时候,会把当前线程阻塞掉,当有一个或多个流有I/O事件时,就从阻塞态中醒来。Epoll和select不同的是:从select那里仅仅知道有I/O事件发生了,但却并不知道是那几个流(可能有一个,多个,甚至全部),我们只能无差别轮询所有流,找出能读出数据,或者写入数据的流,然后对他们进行操作。这样,当并发连接很高的情况下效率自然不高。Epoll可以理解为event poll,不同于忙轮询和select,epoll会把哪个流发生了怎样的I/O事件通知我们。我们使用epoll是等待fd上的事件,你告诉epoll要接收fd上的哪些个事件,事件来了,它就留着,到你epollwait的时候发给你,显而易见效率会远高于select。
2. LuaJitVM
在支持高并发连接的nginx基础上,openresty内嵌了LuaJitVM,每个 woker 进程使用一个LuaJIT VM,对比传统的lua解释器,LuaJIT提供了interpreter和just-in-time两种模式。开始的时候,Lua 字节码总是被 LuaJIT 的解释器解释执行。LuaJIT 的解释器会在执行字节码时同时记录一些运行时的统计信息,比如每个 Lua 函数调用入口的实际运行次数,还有每个 Lua 循环的实际执行次数。当这些次数超过某个预设的阈值时,便认为对应的 Lua 函数入口或者对应的 Lua 循环足够的“热”,这时便会触发 JIT 编译器开始工作。JIT 编译器会从热函数的入口或者热循环的某个位置开始尝试编译对应的 Lua 代码路径。编译的过程是把 LuaJIT 字节码先转换成 LuaJIT 自己定义的中间码(IR),然后再生成针对目标体系结构的机器码(如 x86_64 指令组成的机器码)。
3. CoSocket=Coroutine+socket
可以看下图:
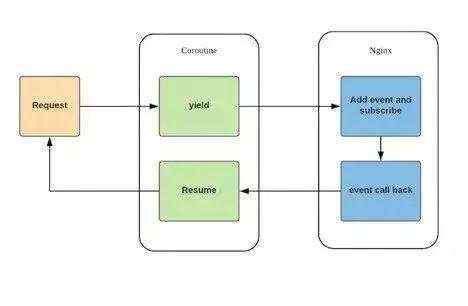
相比起nginx/luajitvm, CoSocket(协程socket)是更和实际应用相关的部分。OpenResty 中的 cosocket通过coroutine(协程)支持以及上面提到的非阻塞事件回调机制两部分结合在一起,最终保证了openresty能支持高并发网络操作的基础。用户的luascript每发起一个io request,都会伴随coroutine的 yield 以及 resume。请求的 Lua 脚本实际上都运行在独立的协程之上,当遇见网络事件时(比如ngx.socket.tcp),暂停自己,把网络事件注册到 Nginx 监听列表中,把CPU让给其它协程继续工作。当有 Nginx 注册网络事件达到触发条件时,唤醒对应的协程继续处理。创建一个协程的体量非常轻,占用内存开销极少,并且没有线程上下文的切换。

Resty-Redis-Cluster介绍及设计思路
下面,简单介绍下rediscluster。先看redismaster/slave/sentinel结构的一些局限:
单节点的redis 不建议内存太大。不只是空间使用率,RDB和AOFrewrite 过程中redis需要forkprocess, Unix fork基于copy-on-write机制所以需要复制内存页表。空间越大,复制的内存页表的cost也越大并且这时latency也会大受影响。而且在redis 4版本前,redis如果触发failover, 新的master/slave之间都需要全量同步。单节点太大会拖慢同步时间造成master/slave节点压力过大,甚至如果没有设置好client-output-buffer-limit 会造成无限循环同步问题(https://redislabs.com/blog/top-redis-headaches-for-devops-replication-buffer/)和master/slave/sentinel模式的redis结构不同,redis-cluster本身是一个多主多从,一组主从负责一段 slot的拓扑结构。Redis-cluster的结构可以被理解为一致性hashring,本身有16384个slot(虚拟节点), slot和实际节点对应。Rediskey会在做 (CRC16(key)mod 16384)后对应到slot, 从而再对应到具体的节点上。如果需要增加或者移除某个节点,可以使用redis-trib.rb工具reassign slot,这个过程被称为resharding。
Redis cluster是一种无中心化,最终一致性的架构设计,每个node间通过gossip协议发送ping/pong/meet/fail来交换节点的状态。无中心化设计的优点是没有proxy,能最大化性能(毕竟Redis cluster的设计初衷按作者说,最优先目标就是性能、水平伸缩和可用性),但是会给client设计带来复杂度。支持无中心化的Smartclient不单是简单的按照RESP协议解析redis报文,同时需要聪明地处理虚拟节点和实际节点的关系。毕竟我们不可能每次都去问redis:slot1是在哪个节点?然后再去发往这个节点处理---这样性能下降是可以预料的。自然,smart client的实现一定会cacheslot和具体节点的对应关系,这样在节点稳定时,通过cache的slotmapping可以做到快速访问。
问题是redis-cluster集群状态也不可能是一直不变的,比如上面提到的resharding。
Moved/Ask重定向:(具体可以参考https://redis.io/topics/cluster-spec)
a.如果发起的命令对应的key所在的slot不属于当前节点,rediscluster会返回一个错误response,像是这样: (error)MOVED 9842 127.0.0.1:7001
b.如果节点正在迁移中,slot对应的一部分数据已经完成迁移,一部分还在原来节点上,redis cluster则返回一个ASK重定向错误,像是这样:(error) ASK 12191 127.0.0.1:7008
Resharding的过程中,client一定会得到以上错误。对于前者,smart client除了需要感知并且到对应节点上拿到返回值,还要重新刷新slot和实际节点的对应关系。对于后者,需要发送一个ask命令给error里的节点询问,然后得到实际结果。

Redis-Cluster体系:
上面说了很多关于redis cluster和openresty的内容,很大程度上是解释 resty-redis-cluster的设计理念和一些绕不过去的细节。
Resty-redis-cluster几乎支持redis cluster所有feature,它包括:
1
初始化启动时通过cluster slots得到实际node和slot对应关系并且全局缓存。每一个request通过基于FFI(C)接口计算CRC16(key)然后对应到slot.在集群稳定时无需每次去取slot 被assign的实际节点,最大化性能。大致上,这个思路和jedis是一样的(可以参考JedisClusterInfoCache这个class)。所不同的是,lua在每个coroutine去取得这一份全局缓存的copy后,如果在产生IO事件后coroutine并没有销毁而只是暂停(yield),那这一份全局缓存的copy仍然会占用luajitVM的空间。当并发特别高时很容易引起luajitVM outofmemory从而crash掉nginx进程。所以在client里提交IO request前,一定需要释放这一份copy.
2
支持大部分redis常用命令(目前不支持的有MGET,MSET以及transaction相关命令如MULTI,DISCARD,EXEC,WATCH)
3
支持在线online-resharding,处理各种resharding带来的重定向问题。上面提过,smart client需要能感知这部分重定向带来的影响并且重新刷新slot和实际节点的 mapping关系。当前request有Moved重定向和ASK重定向发生时,需要通过不断retry得到正确的response
4
支持pipeline. Jedis等客户端并没有考虑pipeline,一是因为pipeline在redis cluster实现困难,因为不同的request本身对应的实际节点不同。二是性能也不如单点的pipeline效率高。但是,当一次RoundTrip发出命令特别多的的场景下我们仍然认为pipeline有助于性能提升。Resty-redis-cluster的实现是在一次发起pipeline之前根据request对应的实际节点提前分组,每组单独像单节点发起pipeline请求。得到每一组的返回结果后再按照请求的顺序拼接成一个完整的返回结果。当然pipeline里同样需要处理重定向错误
5
支持hashtag(关于hashtag可以参考https://redis.io/topics/cluster-spec)
6
支持从节点读。和jedis等其它客户端不同,slave节点并不只是在master宕机后promotion,同样它可以起到支撑并发读压力的作用
7
支持各种异常情况下的error-handling,包括failover, full coverage failure等等
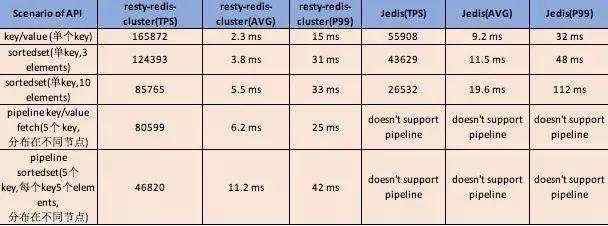
下面是我们的loadtesting以及和jedis之间的比较,(单节点openresty,3个redis节点)
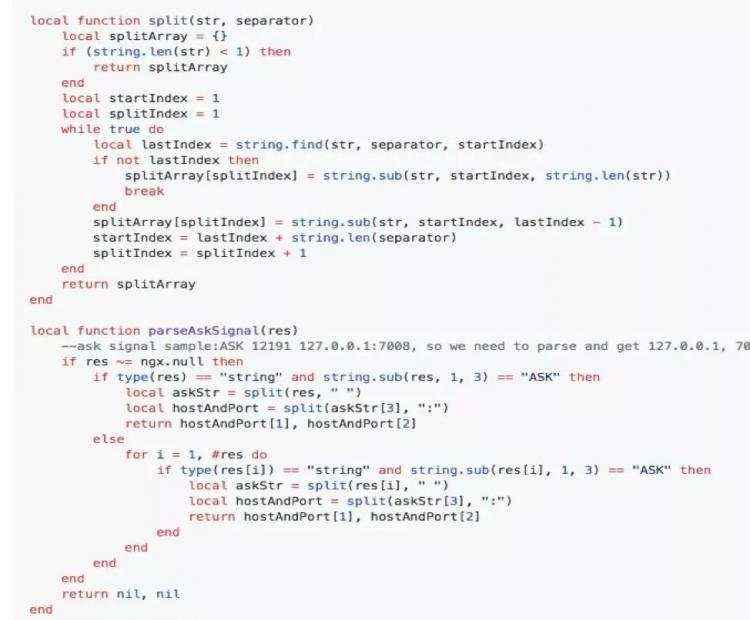
在开发过程中,非常感谢openresty group的其他开发者提的意见。比如需要解析redis cluster的ASK redirection:ASK 12191 127.0.0.1:7008, 我们需要得到127.0.0.1和7008, 如果按照lua正常的字符串split/sub还是比较慢的。
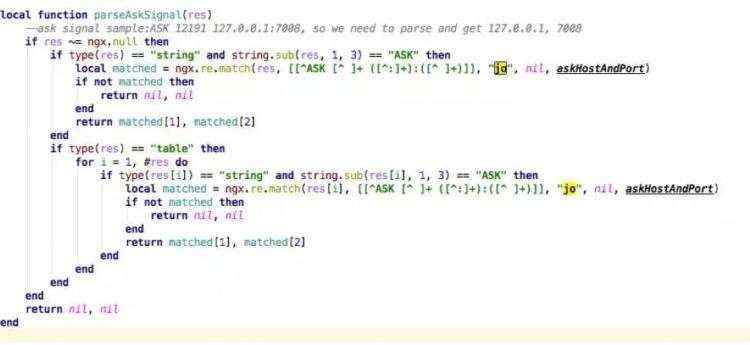
但是相反,如果使用ngx.re.match并且打开JO选项,性能就提高了一倍多:
我个人并不喜欢比较每门开发语言的优劣,每个开发语言在不同场景下都有自己的优势。但是在开发resty-redis-cluster过程中,确实觉得lua作为动态语言的灵活性有时可以让代码更加精简优雅。比如Jedis为每个redis命令都定义了interface,整块代码还是给人很臃肿的感觉:
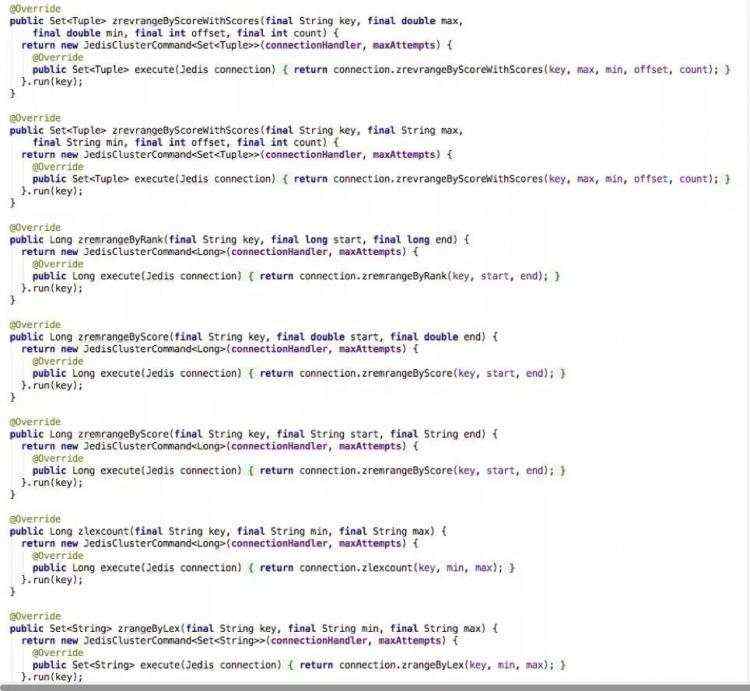
而在lua里,就可以使用lua特有的特性:惰性生成动态方法,以最精简的方式cache下所有redis的命令, 并且甚至为将来redis版本可能添加的方法预留了位置:(有兴趣的同学可以看下lua元表里的__index)
这里要为公司的OSS行动号召一下,coupang已在GitHub开账号:
https://github.com/coupang
Resty-redis-cluster也准备移到下面,如果大家有作品无论和公司业务相关与否都可以联系Coupang的OSS committee 贡献自己的项目。
Coupang是一家布局全球化战略规划+发展速度极快的公司。我们秉承“顾客第一”的理念,为顾客提供优惠价格和丰富的产品选择,并提供便捷和个性化的购物体验。我们不断创新,2016年曾被《麻省理工科技评论》评为“全球50家最智能公司”之一,并入选《福布斯》“全球30家格局改变者”。迄今为止,只有9家公司(如亚马逊,谷歌,Facebook和Coupang)同时入选两个名单。作为全球企业,我们的办公室分布在上海、北京、首尔、硅谷、西雅图等地。
点击【阅读原文】了解更多岗位信息,我在酷胖等你~





 京公网安备 11010802041100号 | 京ICP备19059560号-4 | PHP1.CN 第一PHP社区 版权所有
京公网安备 11010802041100号 | 京ICP备19059560号-4 | PHP1.CN 第一PHP社区 版权所有