作者:归向大海_651 | 来源:互联网 | 2024-11-14 20:57
前言:本文旨在帮助读者深入了解Redis中字典的实现原理,涵盖字典的数据结构、哈希表与哈希节点的关系、元素添加方法及rehash操作等内容。
Redis 是用C语言编写的,它并没有使用内置的字典数据结构,而是自行实现了字典。Redis 服务器中的数据库底层数据结构就是字典,哈希键在某些特定情况下也会使用字典作为底层设计。
(特定情况:哈希对象的编码可以是ziplist或hashtable,
1. 哈希对象保存的所有键值对的键和值的字符串长度都小于64字节,
2. 哈希对象保存的键值对数量小于512个,
不能同时满足这两个条件的哈希对象使用hashtable编码)
代码版本:3.0.504
1. 哈希表与哈希节点的关系
Redis 字典由哈希表构成,哈希表由哈希节点构成。参考源码 dict.h

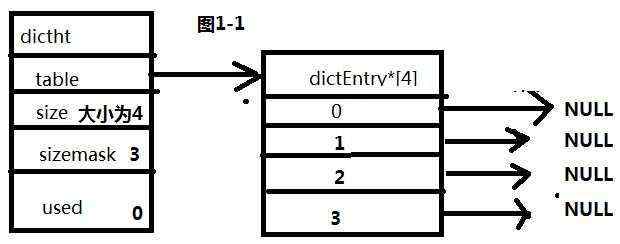
图1-1所示结构,为一个初始大小为4的空的哈希表。
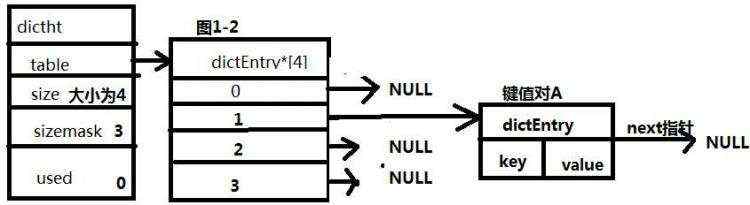
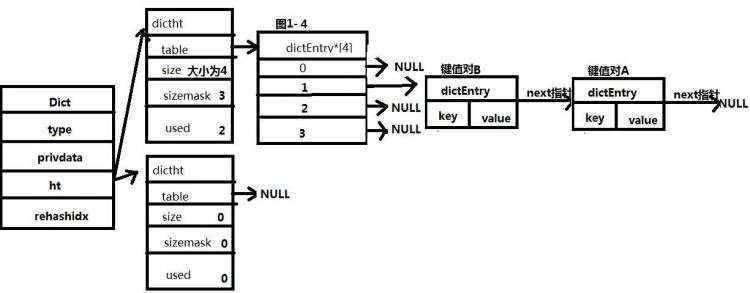
假设向其中存入键值对A,保存后如图1-2所示,具体如何保存到索引位置上,后文有详细介绍。
2. Redis字典与哈希表、哈希节点的关系
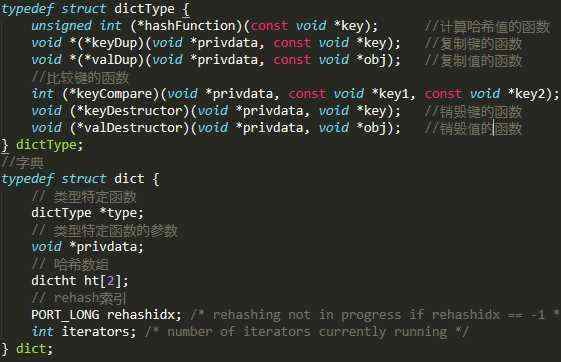
字典中ht保存了两个哈希表,通常情况下,字典使用ht[0]哈希表,ht[1]哈希表仅在对ht[0]进行rehash时使用。rehashidx通常为-1,如果正在进行rehash,则值大于-1。
type指向的dictType结构提供了特定类型的函数,privdata为特定类型函数的可选参数。例如,计算键的哈希值时,使用hash=dict->type->hashfunction(key)。
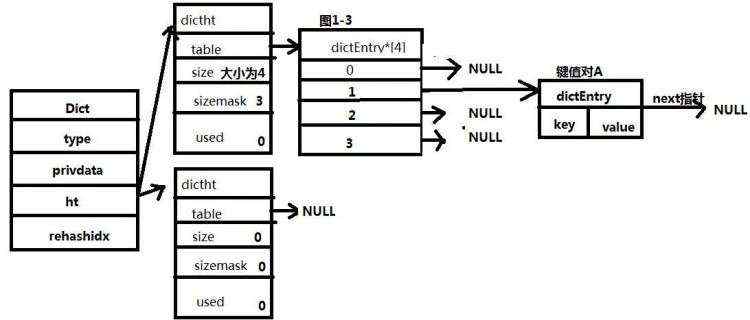
如图1-3所示,为一个字典的结构,字典中保存了一个元素。
3. 如何将元素添加到Redis字典中
元素A是如何保存的?首先计算元素A的哈希值:hash = dict->type->hashfunction(元素A的key)
通过哈希表中的sizemask与hash值,计算出索引值:index = hash & dict->ht[0].sizemask(不发生rehash时为ht[0],发生rehash时可能为ht[0]或ht[1])。
若此时再加入元素B,且元素B最终计算出的索引值与元素A相同,则将B插入A的前面。如图1-4所示。
TIPs:
初学哈希表时可能会有疑问:为什么哈希表中的sizemask值为 size-1?为什么索引值是通过hash & sizemask?以及为何哈希表的大小都为2的幂?
通过&运算计算出当前哈希表大小(0~size-1)范围内的索引值,通过2的幂保证了索引值的均匀分布。
例如,哈希表大小为16,则sizemask为15,sizemask二进制为1111,此时只要保证hash值均匀分布就能保证索引值的均匀分布。
Redis将字典作为数据库底层实现时,使用的Murmurhash计算键的哈希值。
4. rehash的执行
1) 何时开始rehash操作
字典中的哈希表随着保存元素越来越多,当负载因子load_factor = ht[0].used / ht[0].size 满足某些值时,开始对哈希表执行扩展操作。
具体情况如下:
a. 如果redis服务器正在进行BGSAVE或BGREWRITEAOF命令,且负载因子大于等于5,则开始扩展。
b. 如果redis服务器没有进行BGSAVE或BGREWRITEAOF命令,且负载因子大于等于1,则开始扩展。
服务器进行BGSAVE或BGREWRITEAOF命令时,创建子进程执行命令,此时采用写时复制技术优化子进程效率,所以此时负载因子调大,避免执行扩展操作,节约内存。
2) rehash流程
a. 当rehash执行扩容时,为ht[1]分配空间,具体分配多大空间呢?ht[1]的大小为第一个大于等于ht[0].used x 2的2的n次幂。例如,此时used为8,则扩容应分配16≤2的n次幂,所以16就满足。
b. 当rehash执行收缩时,分配空间为ht[1]的大小为第一个大于等于ht[0].used的2的n次幂。例如,此时used为8,则2的3次幂就满足要求,即ht[1]空间为8。
c. 空间分配之后,就是元素的重新哈希,将ht[0]中的元素重新哈希计算添加到ht[1]中,并且从ht[0]中删除。
d. 全部元素都迁移完成后释放ht[0],将ht[1]设置为ht[0],并在ht[1]重新创建一个空白哈希表,为下一次hash做准备。
3) rehash并不是一次就完成的
rehash操作如果一次处理几百万个或几千万个键值对,服务器将无法处理其他任务。为了避免这种大批量的rehash,redis采用渐进式rehash,一次处理少量的键值对。
rehashidx平时为-1,开始rehash后,rehashidx设置为0,标志着从ht[0]哈希表的索引0开始进行rehash。
索引0上的键值对都rehash完成后,rehashidx值+1,继续下一索引值的rehash。
完成的rehash过程:
a. 为ht[1]分配空间。
b. 将rehashidx设置为0,开始rehash。
c. rehash期间,对字典的CRUD操作还会顺带将rehashidx索引上的键值对rehash到ht[1]上。(新键值对的添加只会在ht[1]上操作,其余操作会在两个哈希表都进行操作)。
d. 随着操作不断进行,某个时间点全部rehash结束,将rehashidx值设置为-1,表示完成这次rehash。
分而治之的渐进式rehash避免了集中式rehash带来的巨大计算量。





 京公网安备 11010802041100号
京公网安备 11010802041100号