上一篇博客中介绍了Redis服务器的初始化流程,而这一节中我们来介绍Redis事件循环的主流程。1.事件循环主流程(aeMain)2.
上一篇博客中介绍了Redis 服务器的初始化流程,而这一节中我们来介绍Redis事件循环的主流程。
1. 事件循环主流程(aeMain)
2. 创建连接事件处理器(acceptTcpHandler)
3. 可读事件处理器(readQueryFromClient)
4. 可写事件处理器(sendReplyToClient)
5. 每次事件循环回调(beforeSleep)
6. 时间事件处理器(serverCron)
1. 事件循环主流程(aeMain)
redis是一个事件驱动程序,服务器需要处理以下两类事件,分别是时间事件和文件事件。redis服务器在启动之后,开始执行事件循环,就可以接受客户端的连接请求并处理客户端发来的命令请求了。一图胜千言,事件循环的流程如下图所示(基于redis 3.0 版本):
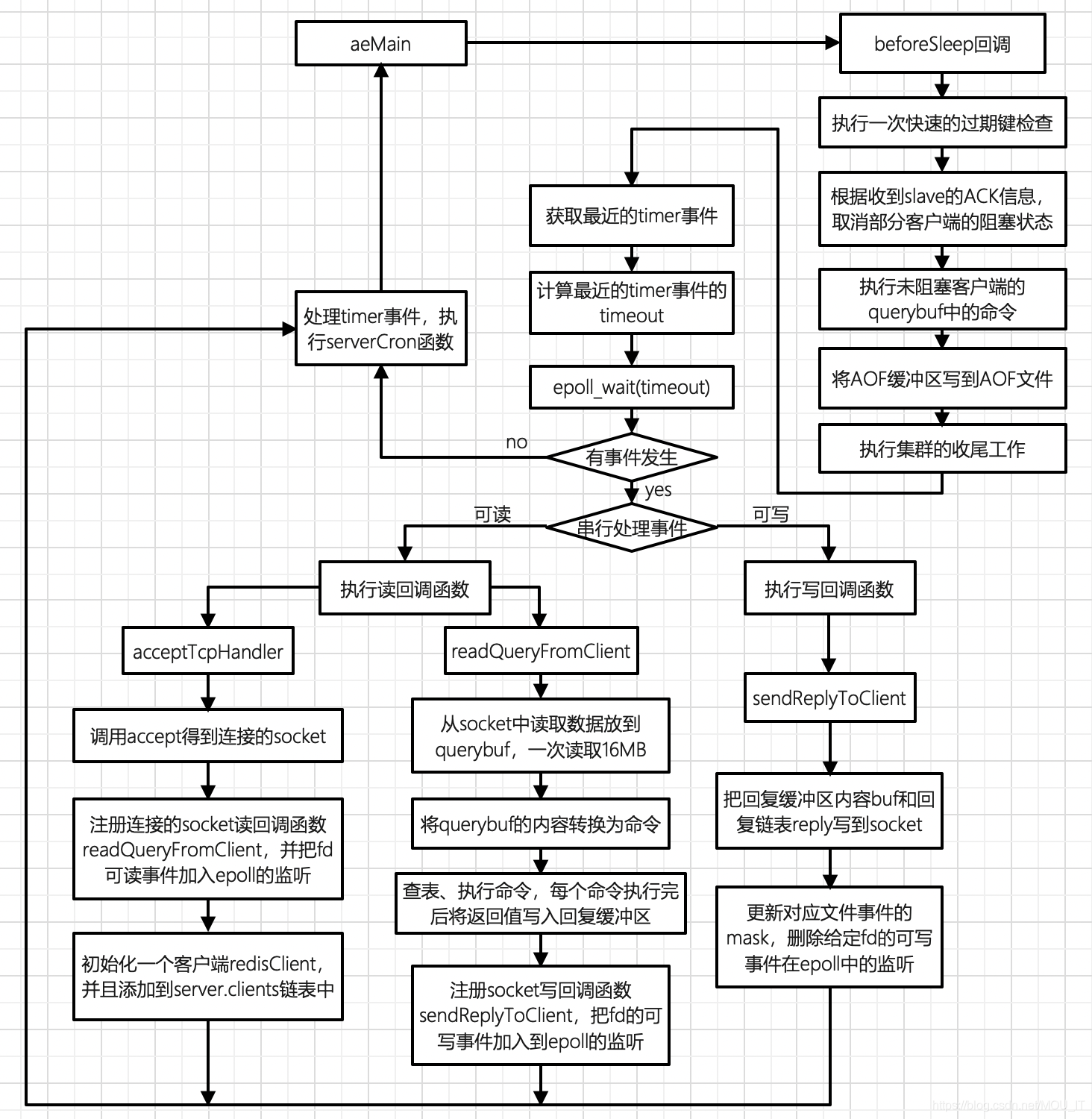
(1)事件循环中,每次迭代都需要执行一次beforeSleep回调函数;
(2)事件循环开始时,首先需要计算最近的时间事件的timeout,然后把这个timeout作为epoll_wait的参数传入,等待文件事件的发生;
(3)如果没有文件事件发生,则执行时间事件,然后进入到下一轮事件循环;
(4)如果有文件事件发生,则根据文件事件是否可读和可写,调用相应的事件处理器:
- 在事件可读时,如果是监听端口产生的,则需要调用acceptTcpHandler函数创建一个新的客户端连接,并且把新创建的socket的可读事件加入到epoll的监听队列中,并且注册相应的可读事件回调函数readQueryFromClient。
- 事件可读时,如果可读事件是其它端口产生的,则调用readQueryFromClient函数处理客户端的命令请求,处理完成之后把该socket的可写事件加入到epoll的监听队列中,并且注册相应的可写事件回调函数sendReplyToClient。
- 事件可写时,需要调用sendReplyToClient函数把写回缓冲区中的内容写到socket中,并且删除该socket的可写事件在epoll中的监听。
整个事件循环中,有几个函数非常关键,分别是创建连接的事件处理器、可读文件事件处理器、可写文件事件处理器、每次事件循环的回调函数和时间事件处理函数,下面分别进行介绍。
2. 创建连接事件处理器(acceptTcpHandler)
在redis服务器初始化的时候,会为监听端口server.port创建一个socket,并且将这个socket的可读事件加入到epoll的监听队列中,而且为这个socket的可读事件注册回调函数acceptTcpHandler,当在事件循环中检测到该端口可读时,就会调用acceptTcpHandler对该socket进行处理。acceptTcpHandler的功能如下:
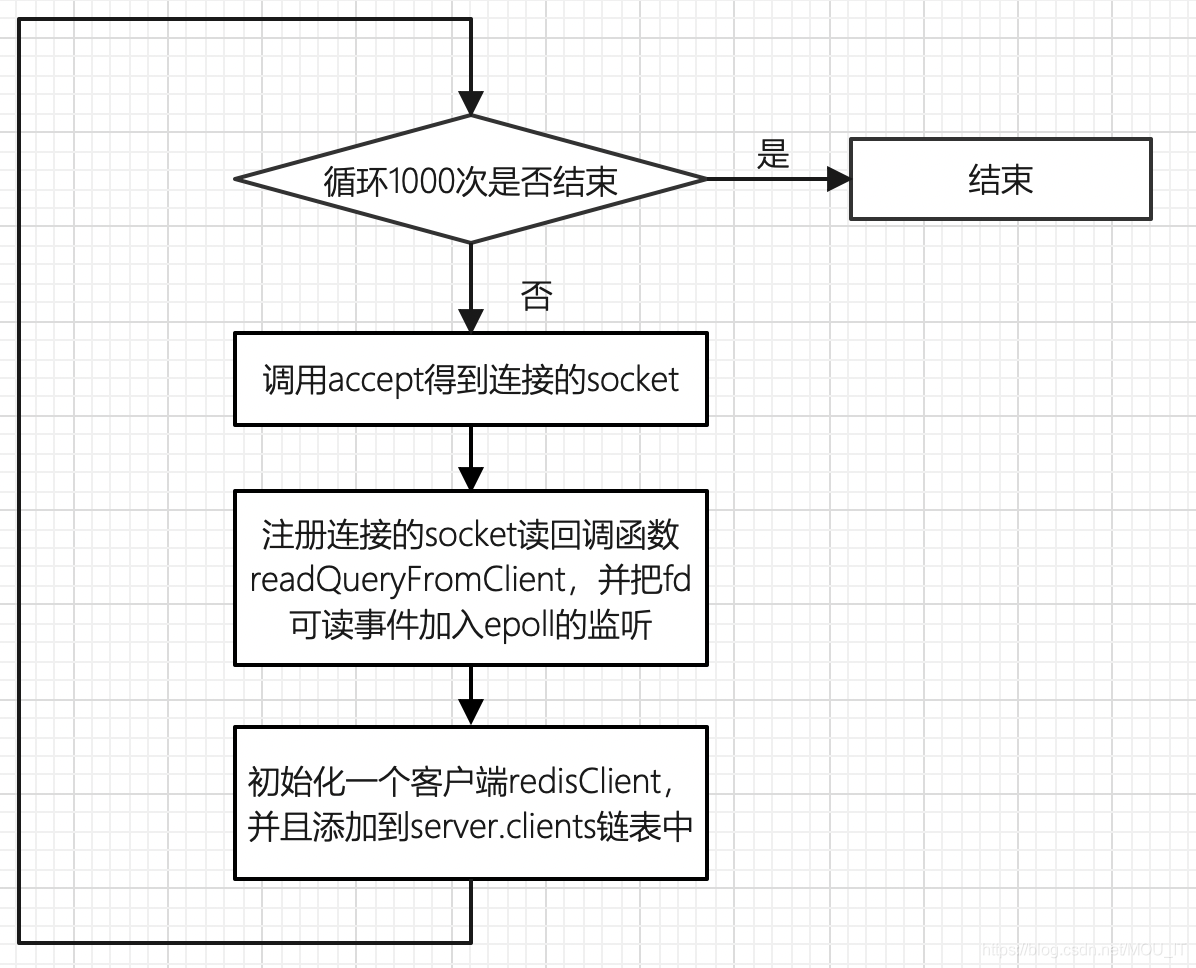
(1)这个函数主要功能是从TCP的已连接队列中取出已经建立TCP三次握手的socketfd,因此这里循环调用了1000次,为的就是一次性尽可能多的取出已经建立的客户端连接。
(2)接着需要为已建立的连接创建一个redisClient,接着设置这个建立的socket fd为非阻塞模式,禁用Nagle算法,设置keep alive,注册连接的socket fd读回调函数readQueryFromClient,并把fd可读事件加入epoll的监听。
(3)最后再初始化redisClient结构体中的其它属性值,然后把这个结构体添加到server.clients的链表中
(4)如果创建的客户端的数量超过了服务器的最大客户端数量server.maxclients,则向这个socket fd写回错误信息,并且释放这个redisClient。
3. 可读事件处理器(readQueryFromClient)
在acceptTcpHandler函数中创建一个新的socket fd时,会将readQueryFromClient函数注册给socket fd的可读事件,当在事件循环中检测到socket fd可读时,就会调用这个函数处理客户端发送过来的命令请求,这个函数的功能如下:
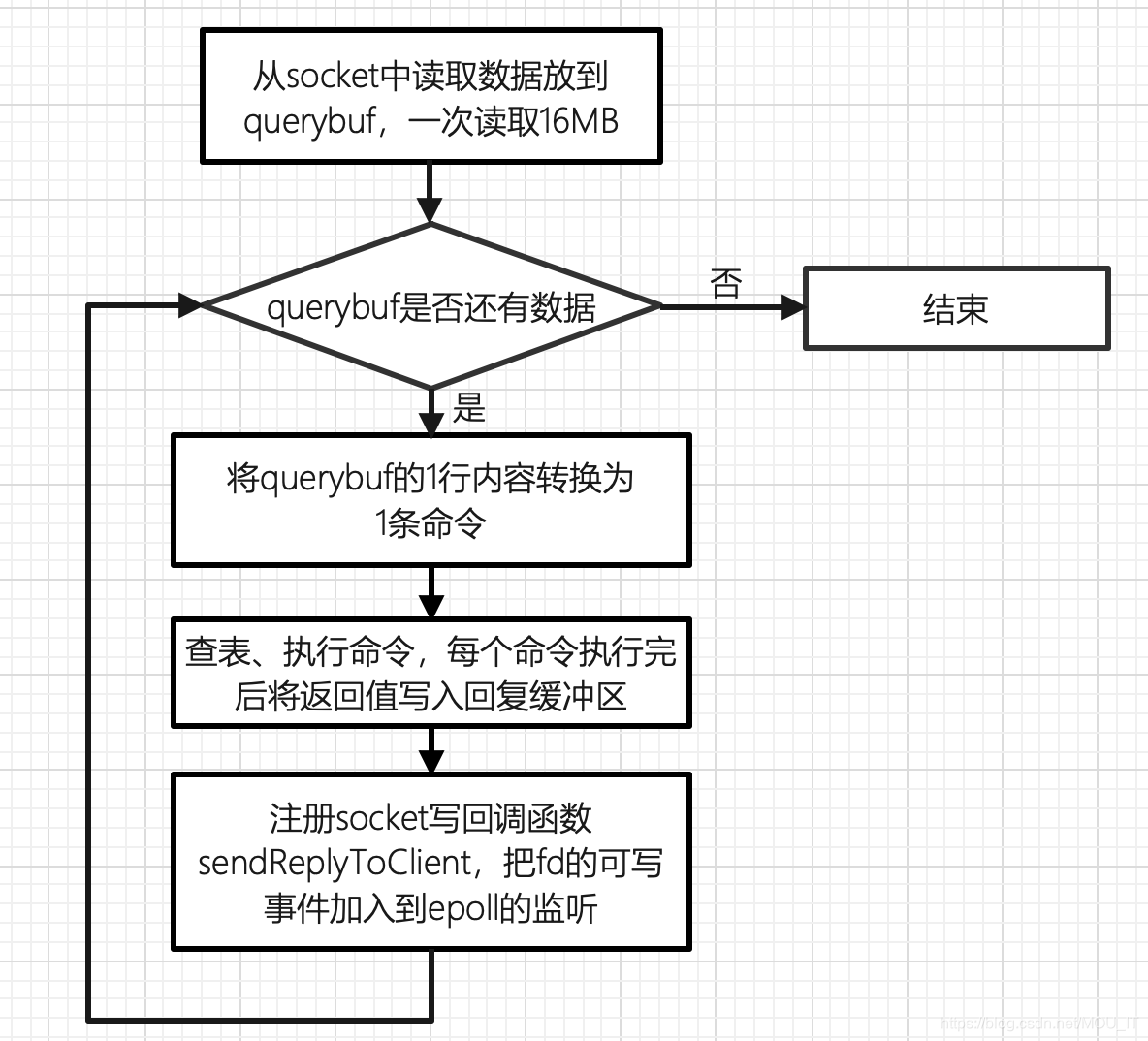
(1)如果socket fd可读时,首先需要从socket fd中读取数据到redisClient的queryBuf中,这里一次性从网络中最大读取16MB的数据。在读取数据的过程中,如果读取出现错误,或者queryBuf的长度超过服务器最大缓冲区长度server.client_max_querybuf_len,都会立即释放这个客户端。
(2)把数据从socket读取到querybuf之后,接着进入一个循环,每次循环处理querybuf中的一行内容。在处理时,客户端的请求一般分为两种类型,一种类型是内联查询(REDIS_REQ_INLINE),内联查询是 TELNET 发送来的,一种是多条查询(REDIS_REQ_MULTIBULK),多条查询是一般客户端发送来的。首先需要把querybuf的一行内容转换为redis的一条命令,并且把转换后的内容保存在redisClient.argc和redisClient.argv中,这两个参数类似命令行参数,前者保存命令的参数个数,后者保存命令及命令的参数。
(3)把内容解析出来之后,最后一步就是执行该条命令了:
- 根据redisClient.argv[0]查询命令表,然后保存命令表中的命令到redisClient.cmd之中,并且检查命令的参数个数是否有误
- 如果服务器开启server.requirepass,则检查认证信息是否有误
- 如果开启了集群模式,则需要在这里进行转向操作,即告诉客户端处理该键的真正集群节点
- 如果内存已超过限制,那么尝试通过删除过期键来释放内存
- 如果这是一个主服务器,并且这个服务器之前执行 BGSAVE 时发生了错误,那么不执行写命令
- 如果服务器没有足够多的状态良好服务器并且 min-slaves-to-write 选项已打开,那么不执行写命令
- 如果这个服务器是一个只读 slave 的话,那么拒绝执行写命令
- 在订阅于发布模式的上下文中,只能执行订阅和退订相关的命令
- 如果服务器正在载入数据到数据库,那么只执行带有 REDIS_CMD_LOADING,标识的命令,否则将出错
- Lua 脚本超时,只允许执行限定的操作,比如 SHUTDOWN 和 SCRIPT KILL
- 在事务上下文中,除 EXEC 、 DISCARD 、 MULTI 和 WATCH 命令之外,其他所有命令都会被入队到事务队列中
- 真正开始执行命令,每个命令执行完后将返回值写入回复缓冲区redisClient.buf,注册socket写回调函数sendReplyToClient,把fd的可写事件加入到epoll的监听
- 将命令复制到 AOF 和 slave 节点
4. 可写事件处理器(sendReplyToClient)
写事件处理器在读事件处理器没执行完一条命令时,都会给socket fd注册写事件处理器的处理函数sendReplyToClient,该函数在socket fd可写的时候,将客户端的写回缓冲区redisClient.buf和redisClient.reply中的内容写回socket,并且取消epoll中对该socket fd的写事件的监听。
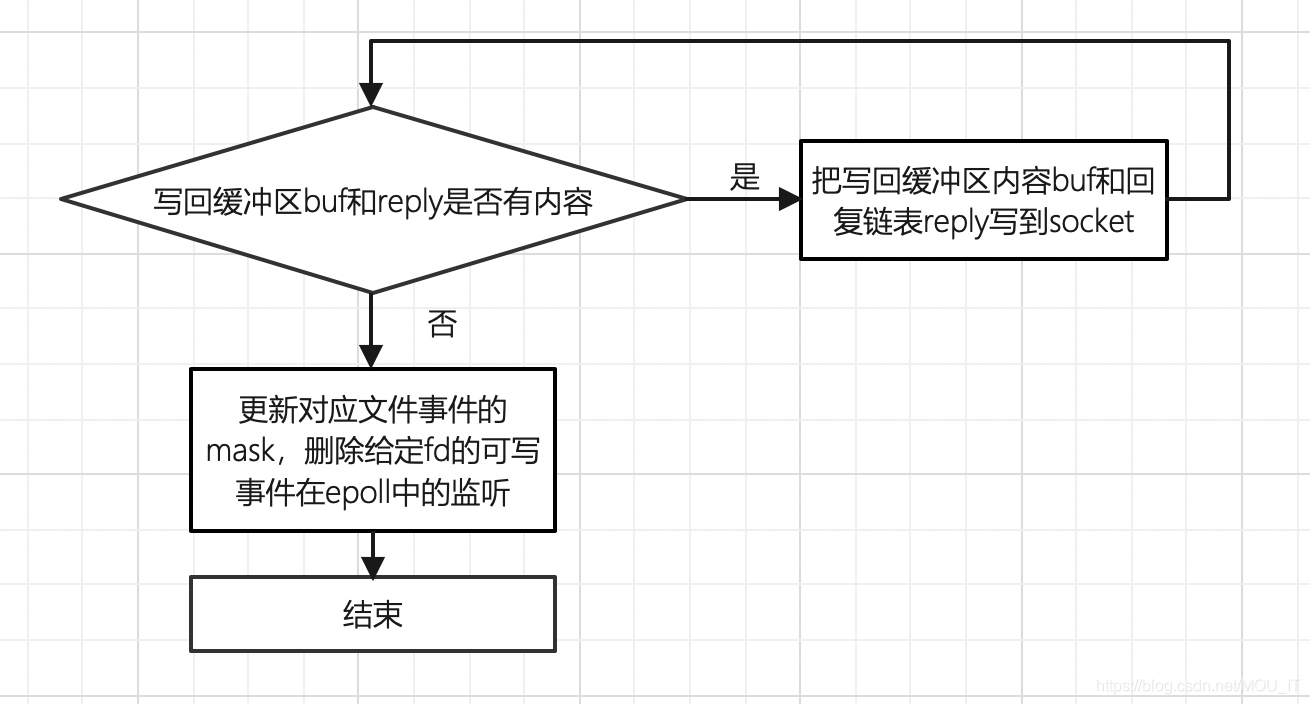
(1)把写回缓冲区写到socket时,会优先写buf中的内容,然后再写reply中的内容。buf主要用于保存长度较小的回复内容,大小为16KB,而reply是一个链表,用于保存长度较长的内容。
(2)写完之后更新对应文件事件的mask,删除给定fd的可写事件在epoll中的监听;
5. 每次事件循环回调(beforeSleep)
每次事件循环都会执行一次beforeSleep函数,这个函数用于做一些必要性工作,如下图所示:
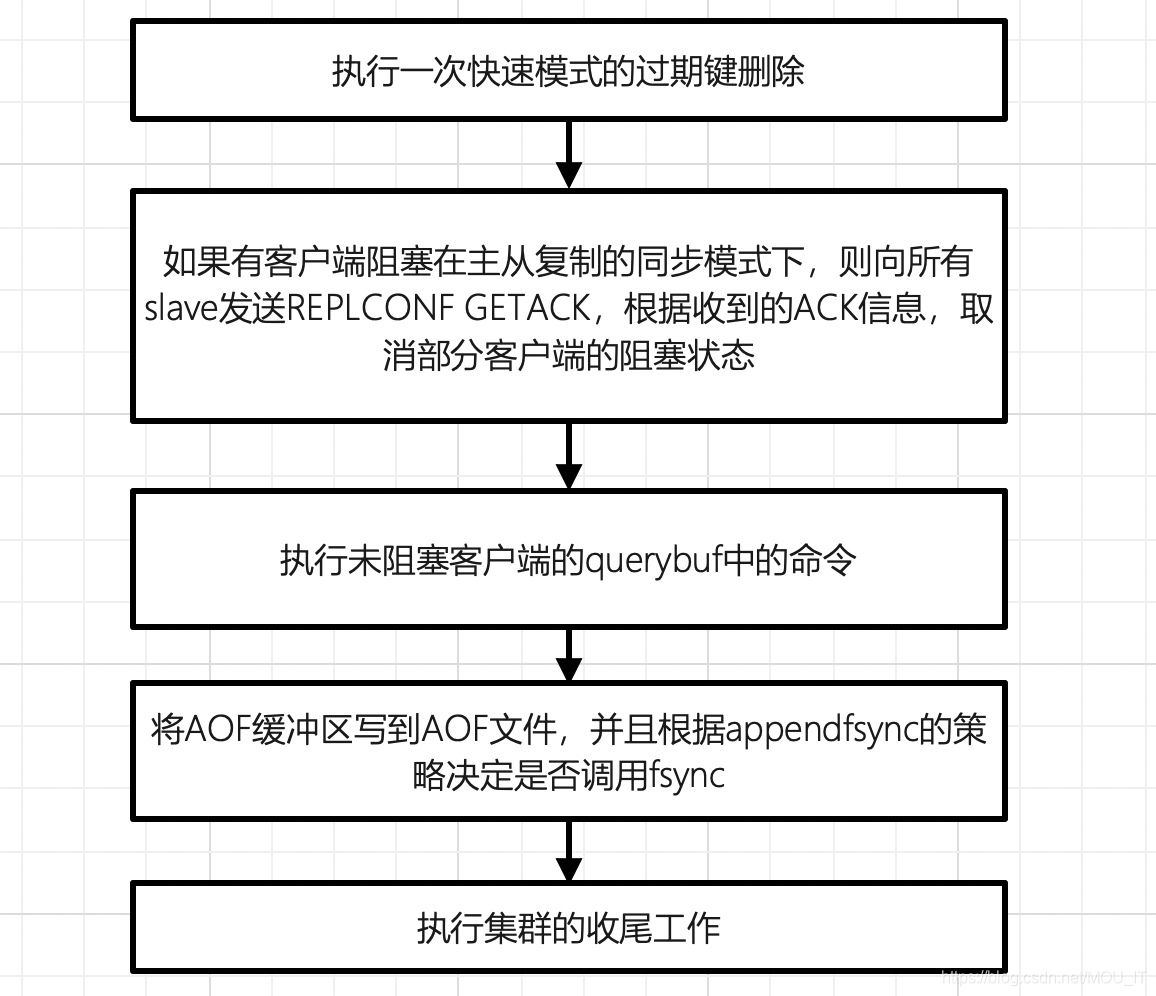
(1)执行一次快速模式的过期键删除:
进行过期键删除时,通常有两种策略,分别是快速模式(ACTIVE_EXPIRE_CYCLE_FAST)和正常模式(ACTIVE_EXPIRE_CYCLE_SLOW):
- 在快速模式下,执行的时间不会长过 1000(EXPIRE_FAST_CYCLE_DURATION )微秒,并且在 1000(EXPIRE_FAST_CYCLE_DURATION )微秒之内不会再重新执行。
- 在正常模式下,执行的时间不会超过CPU时间的25%,即100ms * 25%,为25ms,这里的100ms表示serverCron函数1s调用10次;
每个数据库每次最多处理20(ACTIVE_EXPIRE_CYCLE_LOOKUPS_PER_LOOP)个过期键,处理时,需要从数据库的过期键字典中中随机选择一个过期键,如果键已经过期,那么删除这个过期键,并且传播过期命令。
(2)根据收到slave的ACK信息,取消部分客户端的阻塞状态:
redis的复制默认是异步的,如果需要同步复制,那么客户端可以用WAIT命令来实现。每当有命令执行时,redis都会记录当前的复制偏移量到客户端状态里。当调用WAIT命令时,用户指定至少多少个replication成功以及超时时间。redis会把客户端加到等待slave响应的队列server.clients_waiting_acks里,并把客户端状态设置为REDIS_BLOCKED_WAIT。处于该状态的客户端无法处理socket的输入数据,后续命令会在输入缓冲区堆积,直到WAIT之前的命令复制完成或者超时。
如果有客户端阻塞在WAIT命令上,此时服务器将会把server.get_ack_from_slaves置为true,此时会向所有slave发送命令:REPLCONF GETACK,收到该命令的slave会马上发送自己的复制偏移量给master,服务器根据收到slave的ACK信息,检查等待slave响应队列里是否有客户端的有足够多的slave的复制偏移量不少于要求的值,足够的话就解除block,把客户端状态设为REDIS_UNBLOCKED,并且把客户端添加到server.unblocked_clients链表中。
(3)执行未阻塞客户端的querybuf中的命令
如果server.unblocked_clients链表中存在未阻塞的客户端,那么执行所有未阻塞客户端中查询缓冲区querybuf中的命令。
(4)将AOF缓冲区写到AOF文件,并且根据策略是否调用fsync:
因为程序需要在回复客户端之前对 AOF 执行写操作,而客户端能执行写操作的唯一机会就是在事件 loop 中,因此,程序将所有 AOF 写累积到缓存server.aof_buf中,并在重新进入事件 loop 之前,将缓存写入到文件中。这里的写AOF缓冲区到文件的策略有三种,分别是:
- AOF_FSYNC_NO 0:将AOF缓冲区的所有内容写入到AOF文件,不调用fsync(),由OS决定什么时候flush数据到磁盘;
- AOF_FSYNC_ALWAYS 1:将AOF缓冲区的所有内容写入到AOF文件,同时调用fsync()函数,每次有数据写入就调用一次,最安全但是最慢;
- AOF_FSYNC_EVERYSEC 2:将AOF缓冲区的所有内容写入到AOF文件,fsync()每秒调用一次,此时的fsync()由线程池中的异步线程专门负责处理;
(5)执行集群的收尾工作:
执行故障迁移,更新节点的状态,保存 nodes.conf 配置文件等,集群的内容将在后面的博客中进行介绍。
6. 时间事件处理器(serverCron)
serverCron函数需要在给定的时间点执行,而时间事件就是服务器对这类定时操作的抽象。Redis服务器初始化时,会将serverCron函数指针和时间组成一个时间事件,然后放入事件循环aeEventLoop的时间事件的链表中。serverCron函数默认每隔100ms执行一次,这个函数负责管理服务器的资源,并保持服务器自身的良好运转。该函数的主要功能如下:
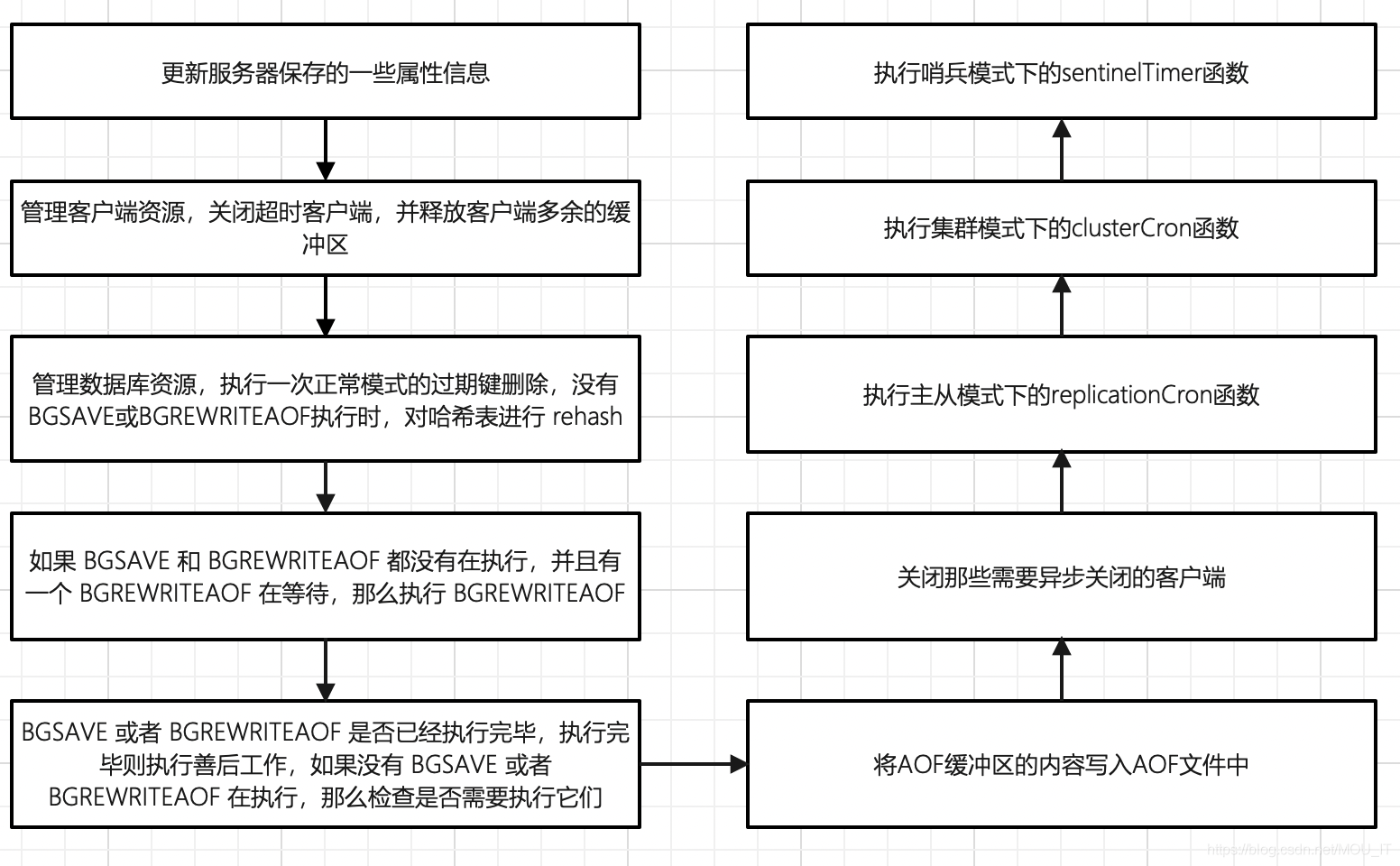
(1)更新服务器时间缓存
redis有不少功能需要获取系统当前时间,而每次获取系统时间都需要进行一次系统调用,为了减少系统调用次数,服务器状态中的server.unixtime和server.mstime属性被用作当前时间的缓存。unixtime保存了秒级精度的时间戳,mstime保存了毫秒级精度的时间戳。
(2)更新LRU时钟
服务器状态的server.lruclock属性保存了服务器的LRU时钟,用于计算键的空转时常。每个redis对象都有一个lru属性,这个lru属性保存了对象最后一次被命令访问的时间。当服务器要访问一个键的空转时间时,就会用lruclock减去对象的lru属性记录的时间。
(3)更新服务器每秒执行命令次数
serverCron函数中的trackOperationPerSecond函数会以每100毫秒一次的执行频率,估计并记录服务器最近一秒种处理的命令请求数量。trackOperationPerSecond函数和服务器状态中的四个ops_sec_开头的属性有关,分别是:
- server.ops_sec_last_sample_time:上一次抽样的时间
- server.ops_sec_last_sample_ops:上一次抽样时服务器已执行的命令数量
- server.ops_sec_samples[REDIS_OPS_SEC_SAMPLES]:REDIS_OPS_SEC_SAMPLES为16,数组中每一项都记录了一次抽样结果
- server.ops_sec_idx:ops_sec_samples数组的索引,每次抽样时增1,到16时归零。
(4)更新服务器内存峰值记录
服务器状态中的server.stat_peak_memory属性记录了服务器的内存峰值大小,每次serverCrom函数执行都会更新这个值。
(5)处理SIGTERM信号
服务器启动时,redis会为服务器进程的SIGTERM信号关联处理器sigtermHander函数,这个信号负责在服务器收到SIGTERM信号时,打开服务器的server.shutdown_asap标识。每次serverCrom函数运行时,程序都会对服务器状态的shutdown_asap属性进行检查,并根据属性值决定是否关闭服务器。
(6)管理客户端资源
serverCrom的clientCron函数会对客户端进行检查,如果客户端和服务器的连接已经超时,那么程序释放这个客户端。如果客户端上一次命令执行完了以后,输入缓冲区的大小超过了一定的长度,那么程序就会释放客户端当前的输入缓冲区,并重新创建一个默认大小的输入缓冲区,从而防止客户端的输入缓冲区耗费了过多的内存。
(7)管理数据库资源
serverCrom函数中的databaseCron函数会对数据库进行检查,执行一次正常模式下的过期键删除,并在没有BGSAVE或BGREWRITEAOF执行时,对字典进行rehash操作。
(8)执行被延迟的BGREWRITEAOF
服务器执行BGSAVE期间,如果客户端发来BGREWRITEAOF命令,那么服务器会将BGREWRITEAOF命令的执行时间延迟到BGSAVE命令之后,每次serverCron函数的执行都会检查。如果 BGSAVE 和 BGREWRITEAOF 都没有在执行,并且有一个 BGREWRITEAOF 在等待,那么执行 BGREWRITEAOF。
(9)检查持久化操作的运行状态
服务器使用server.rdb_child_pid和server.aof_child_pid属性记录了BGSAVE命令和BGREWRITEAOF的子进程的ID。每次执行serverCron函数时,程序都会检查这两个PID,只要其中的一个不为-1,程序就会执行一次wait3函数,检查子进程是否有信号发来服务器进程:
- 如果有信号到达,说明RDB文件已生成或者AOF文件已生成,服务器需要执行后续操作。
- 如果没有信号到达,则不做任何操作。
如果这两个PID都为-1,表示没有在执行持久化操作,此时,程序需要执行以下三个检查:
- 查看BGREWRITEAOF是否被延迟,被延迟则执行
- 检查服务器的自动保存条件是否满足,满足则调用BGSAVE操作。
- 检查AOF重写条件是否满足,配置文件中auto-aof-rewrite-percentage这个参数设置自动重写的条件,满足则执行一次新的BGREWRITEAOF操作
(10)将AOF缓冲区的内容写入AOF文件中
如果服务器开启了AOF持久化功能,并且AOF缓冲区还有待写入的数据,那么serverCron函数会调用相应的程序,将AOF缓冲区的内容写入到AOF文件里面。
(11)关闭异步客户端
关闭输出缓冲区大小超出限制的客户端。
(12)执行主从模式下的replicationCron函数,将在后面的博客中介绍
(13)执行集群模式下的clusterCron函数,将在后面的博客中介绍
(14)执行哨兵模式下的sentinelTimer函数,将在后面的博客中介绍
(15)增加cronloops计数器的值
服务器状态中的server.cronloops记录了serverCrom函数执行的次数。






 京公网安备 11010802041100号
京公网安备 11010802041100号