作者:淘宝杂谈网z | 来源:互联网 | 2023-08-14 14:04
目录
论文认为的问题:
主要解决办法:
BERT的缺陷:
模型架构:
基于策略的强化学习(policy-based RL):
对目标函数求导
模型的loss:
测试阶段:
结果:
补充:
机构为:伊利诺伊大学厄巴纳-香槟分校、微软AI、腾讯AI。
论文认为的问题:
认为当前输入文本的长度是固定的(bert最大为512),而且预测答案是每段文本独立进行预测,获取的文本信息只能局限于本段。故提出了Recurrent Chunking Mechanisms。
主要解决办法:
提出通过增强学习让模型学习决定输入每段的长度。同时通过循环机制让每段文本流动,让机器做决定的时候可以参考除本段之外的信息。循环机制实现可使用gated recurrence和LSTM recurrence。通过上述方法可以在CoQA,QuAC以及TriviaQA数据集上取得较好的效果。
BERT的缺陷:
固定分割,Bert源码举例:

我们来一步一步的计算切分过程:
- 首先start_offset=0,length=700>max_tokens_for_doc=500,所以第一次的切分就是[0-500],由于length=500>doc_stride=128,所以start_offset=128
- 第二次start_offset=128,length=700-128=572>max_tokens_for_doc=500,所以第二次的切分就是[128-628],由于length=500>doc_stride=128,所以start_offset这时等于256
- 第三次start_offset=256,length=700-256=444,所以第三次的切分就是[256-700]
因此第一次切分的文章长度为500,第二次切分的文章长度为500,第三次剩下的文章长度为444

切分后的每一篇segment与问题构成一个样本作为BERT的输入,比如在文章长度为700,doc_stride为128的情况下,会切分出来3个segment,于是也就和同一个问题组成了三个example,需要注意的是如果某个segment不包含有答案,那么这个segment是不用的。
所以出现问题:1.以固定长度分割文章,那么就可能导致某些分割后的文章所包含的答案的上下文不充分,也就是说答案在分割后的位置靠近边缘。

上图指出当答案的中心词位置与切分文章的中心词位置之间的距离影响着模型预测答案位置的准确率。
论文提出的第二个问题就是当文章分段送入bert中去,那么模型在阅读了第一个分割片段后的语义信息,应该是是对第二段阅读提取答案有所帮助。但是之前是忽略了这个问题。
首先bert的输入形式如下:

我们重点关注CLS,bert原文中对CLS的描述为:
The final hidden state corresponding to this token is used as the aggregate sequence representation for classification tasks.
也就是说CLS这个token的最终的hidden state聚集了整个sequence的表示,这篇论文的模型的循环机制的原理就是:
将CLS的hidden state通过LSTM/Gate达到循环的目的,具体做法就是将前一个segment的LSTM/Gate的输出作为当前LSTM的hidden state 
在论文源代码中,train_model、val_model、test_model都有这句 for t in range(args.max_read_times) 通过这行代码,我们了解到模型是固定了分割次数的,也就是说模型会在一篇document上分割max_read_times次数。

同样在这三个model中都有下面这行代码:

利用上述代码,实现循环机制。
因为步幅actions的选择是连续的决策过程,通过强化学习来训练分块策略是很自然的。
因此难点在于如何通过强化学习来解决分割document的问题
基于策略的强化学习(policy-based RL):
RL的思想是:环境environment输入给智能体agent一个状态s,agent根据策略 
其中环境与agent交互,环境给agent的是状态和奖励,agent做出的行为会改变环境的状态。在深度学习中应用强化学习时,策略policy就是神经网络NN。

好的接下来我们定义目标函数:
我们从agent与环境交互所产生的轨迹的角度来定义目标函数:

参照上图,分别解释每一行公式:
首先,给定一个初始状态 
第一行我们已经知道,它的含义就是对策略下 
这里的第一行公式就是指一条轨迹的产生的概率为:初始状态
在已知上面的公式后,我们对目标函数求导:

第一行公式就是对目标函数求导数,奖励是环境给的,与策略无关,因此只需要计算
即使不看上述推导过程,也没关系,我们只要知道
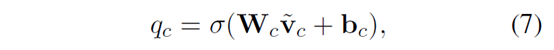
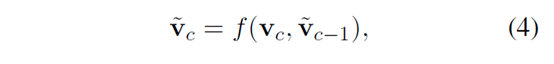
而
模型的loss有三个,第一个是答案提取器(Answer Extractor)的loss,它的值是模型预测的答案位置与真实位置的交叉熵:
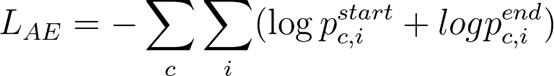


BERT产生第c个segment中的第i个token产生的vector representation 

前两个的损失函数都是交叉熵损失函数,属于监督学习,有明确的标签,但是第三个损失值:

不过根据前面推导,我们已经推导出该损失函数的导数为:
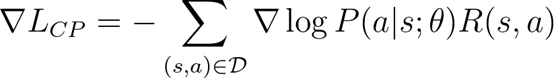
所以现在我们只需要计算出
定义:
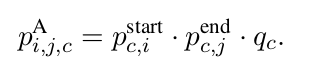
作为当前的segment预测答案位置的分数
然后根据当前状态下所作出的行为
总计会有max_read_times个,我们取出来其中值最大的作为模型在切分了一篇文章max_read_times后所作出的综合预测。

结果:
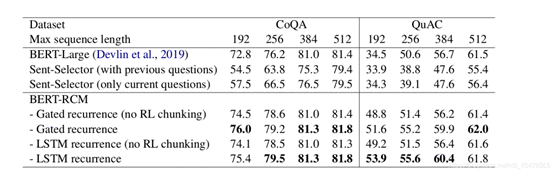
根据此表我们可以看出来,当最大长度max_seq_len限制为512的时候,其实这种循环切分的机制并没有比BERT-large有什么明显的效果,主要原因是,CoQA和QuAC数据集的文章大部分不是特别的长

根据上图我们了解到,CoQA和QuAC的训练集合的文章长度平均为352和516个单词,显然很多文章并不需要切分。因此Recurrent chunking机制发挥不了什么作用,但是随着最大长度的减小,比如,当最大长度限制为192的时候,也就是说当一篇文章会被切分成很多长度不超过192的segment的时候,循环切分的方式明显好于baseline,因为baseline的做法是将切分的各个segment独立的预测答案,而且也不考虑answer在segment中的位置,前面已经分析了,那些answer位置在segment位置中心的答案容易预测出来,而处于segment边缘的答案由于缺少足够的上下文,是不容易准确的预测出来的。
下表是在TriviaQA数据集上的实验结果:

因为TriviaQA数据集比较长,max_seq_len固定为512的情况下,显然循环切分机制效果要好于baseline的,说明循环切分机制适用于处理长文本。

上图指的是BERT-large这个基线模型和RCM这个循环切分机制在切分文本时,切分的文本包含完整答案在切分的所有文本中的比例,也叫Hit rate,命中率。显然循环切分机制切分的文章中有大部分都是包含完整答案的。而baseline这种按照固定滑动步数切分文章的做法,有相当一部分的文章是不包含有答案的。
补充:
在循环切分机制当中,对于不包含有答案的segment,仍然会保留下来作为样本参与训练,因为整个切分过程是在一篇document上连续切分的,中间断了显然是不行的,而且我们需要让模型学会避免切分出这种不包含answer的segment.具体的做法是,对于不包含答案的segment,和question构成一个example输入到BERT当中,BERT的CLS的表示和上一时刻的segment的LSTM的输出一起输入到LSTM当中,得到
红色字体代表的是answer,第一次切分时,固定到max_seq_length为止,也就是图片中的黄色部分,第二次切分时,向右滑动128个单词,滑动有点多,答案到右边界,也就是蓝色部分chunk 2,第三次切分下模型向左移动了16个单词,目的是使得第三个chunk包含答案更多的上下文,也就是图片中的橘色部分,显然这种切分方式比固定切分要好,而且固定的切分方式是不会向左移动的。









 京公网安备 11010802041100号
京公网安备 11010802041100号