基础介绍——数据类型及其简单用法
本文中涉及的全部代码有:
data() #得到R语言内置数据集
class(rivers) #查看向量rivers的数据类型
plot(rivers) #画向量rivers的散点图
hist(rivers) #画向量rivers的直方图
class(state.abb) #查看向量state.abb的数据类型
pie(table(state.region)) #用table函数统计一下state.region这个向量,得到一个饼图
yanse <- c("red","green","blue","yellow") #定义yanse变量
pie(table(state.region),col &#61; yanse) #把yanse这个向量传递给pie函数中的col选项
labs <- c("NC","S","N","W") #设置只一个labs字符向量
pie(table(state.region),col &#61; yanse,labels &#61; labs) #将其传给pie函数中的labels选项
class(state.division) #查看向量state.division的数据类型
plot(mtcars$cyl,mtcars$disp) #取mtcars数据集中的cyl和disp这两列来绘散点图
plot(as.factor(mtcars$cyl),mtcars$disp) #把其中的cyl使用as.factor函数转化成因子
class(state.x77) #查看向量state.x77的数据类型
heatmap(state.x77) #将矩阵向量state.x77画成热图
heatmap(as.data.frame(state.x77)) #将矩阵转化成数据框
fit <- lm(weight ~ height,data &#61; women) #简单的线性回归的案例&#xff1a;fit等于lm函数&#xff0c;weight变量~height变量&#xff0c;data等于数据集women。
#lm&#xff08;Linear Models&#xff09;是用来适应线性模型的。它可用于进行回归、单层分析方差分析和协方差分析。
plot(fit)
正文&#xff1a;
在R console中输入data函数&#xff0c;就可以得到R语言内置数据集。
data()
然后就可以看到按字母顺序的内置的数据集&#xff1a;

我们在学习R语言绘图的时候要时刻知道输入数据的结构和类型。可以使用class函数来查看。例如&#xff1a;
数值向量可以直接用来画点图&#xff0c;饼图&#xff0c;条形图&#xff0c;直方图等。
在R console中敲
class(rivers)

结果返回&#xff1a;numeric&#xff0c;表明这是数值类型的向量。
数值向量可以直接用来画点图&#xff0c;饼图&#xff0c;条形图&#xff0c;直方图等。
例如&#xff0c;在R console中敲plot(rivers)&#xff0c;绘制散点图
plot(rivers)
即可出现&#xff1a;

例如&#xff0c;在R console中敲hist(rivers)&#xff0c;绘制直方图
hist(rivers)
即可出现&#xff1a;

字符串类向量数据主要用在画图中的label标签部分或用于设置不同颜色等
接下来&#xff0c;在R console中敲class(state.abb)
class(state.abb)
返回的结果是&#xff1a;character&#xff0c;即字符串类向量。

字符串类向量数据主要用在画图中的label标签部分或用于设置不同颜色等
比如每条染色体的名字等。
例如&#xff0c;在R console中敲pie函数&#xff0c;
pie(table(state.region))
用table函数统计一下state.region这个向量&#xff0c;就可以得到一个饼图&#xff1a;

但是感觉颜色不好看。那么我们就可以设置一个字符向量&#xff0c;里面包含我们需要的颜色。
例如&#xff0c;定义一个变量:
yanse <- c("red","green","blue","yellow")
接下来&#xff0c;我们把这个向量传递给pie函数中的col选项
pie(table(state.region),col &#61; yanse)
就可以得到&#xff1a;

这个颜色其实也不好看&#xff0c;之后会介绍如何在R中设置好看的颜色。
我们还可以再设置只一个labs字符向量
labs <- c("NC","S","N","W")
然后将其传给pie函数中的labels选项&#xff1a;
pie(table(state.region),col &#61; yanse,labels &#61; labs)
就可以得到&#xff1a;

因子是用来分组的向量
在R console中敲class(state.division)
class(state.division)
返回的结果是&#xff1a;factor&#xff0c;即因子&#xff0c;因子是一类特殊的向量。

因子是用来分组的向量。
比如&#xff0c;处理组与对照组&#xff0c;或不同样品之间来进行比较&#xff0c;例如不同染色体长度分布的条形图等&#xff0c;这些地方都会用到factor向量
例如&#xff1a;我们取mtcars数据集中的cyl和disp这两列来绘图
plot(mtcars$cyl,mtcars$disp)
cyl和disp表示不同发动机汽缸数目与发动机排量之间的关系。这两个数据集都是向量&#xff0c;这样画出来的是一个散点图&#xff1a;

如果我们把 其中的cyl使用as.factor函数转化成因子
plot(as.factor(mtcars$cyl),mtcars$disp)

所以&#xff0c;以后看见这种分组展示数据的图&#xff0c;就该知道&#xff0c;x轴应该是“因子”的数据类型。
接下来是矩阵&#xff0c;矩阵在R中特别适合绘制热图。用基因表达的数据&#xff0c;经常用到热图。
在R console中敲class(state.x77)
class(state.x77)
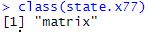
返回的结果是&#xff1a;matrix&#xff0c;即矩阵&#xff0c;矩阵在R中特别适合绘制热图。用基因表达的数据&#xff0c;经常用到热图。
heatmap(state.x77)

如果将矩阵转化成数据框
heatmap(as.data.frame(state.x77))
就会提示错误&#xff1a;x必须为数值矩阵&#xff08;才能够画热图&#xff09;。

此外&#xff0c;R中还经常包括对各种测定结果进行绘图&#xff0c;例如线性回归等
例如一个简单的线性回归的案例&#xff1a;fit等于lm函数&#xff0c;weight变量~height变量&#xff0c;data等于数据集women。
fit <- lm(weight ~ height,data &#61; women)
这个结果中&#xff0c;fit是lm类型的函数。

lm&#xff08;Linear Models&#xff09;是用来适应线性模型的。它可用于进行回归、单层分析方差分析和协方差分析。
直接使用plot函数来绘制
plot(fit)

这样就会出现四张图&#xff1a;




这是对特定数据类型有特定的绘图函数。
总之&#xff0c;对于用R语言作图&#xff0c;了解数据结构非常重要&#xff0c;在使用每个绘图函数的时候&#xff0c;首先需要知道&#xff0c;输入的数据结果才能绘出正确的图。
![[echarts] 同指标对比柱状图相关的知识介绍及应用示例](https://img7.php1.cn/3cdc5/c7bc/ae9/d860963d11bbd36d.jpeg)









 京公网安备 11010802041100号
京公网安备 11010802041100号