本节书摘来自华章计算机《R语言数据挖掘:实用项目解析》一书中的第2章,第2.5节,作者[印度]普拉迪帕塔·米什拉(Pradeepta Mishra),译 黄芸,更多章节内容可以访问云栖社区“华章计算机”公众号查看。
计算概率分布、将数据点拟合于一些特定类型的分布以及后续的解读有助于建立假设。此假设可用于在给定一组参数下估算事件的概率。我们来看看对不同类型分布的解读。
一个数据集的任何变量都可通过拟合一个分布来得到其分布参数的最大似然估计。密度函数适用于诸如“贝塔”“柯西”“卡方”“指数”“f”“伽马”“几何”“对数正态”“logistic”“负二项”“正态”“泊松”“t”和“威布尔”等分布。这些分布都是常用的,这里不给出示例。对于连续型数据,我们采用正态分布和t分布:

在上面的代码中,我们用的是Cars93数据集中的MPG.highway变量。通过让t分布拟合这个变量,我们得到参数估计、标准误差估计、协方差矩阵估计、对数似然值还有总数。类似的操作也适用于对连续型变量执行正态分布拟合:

现在我们来看如何图形化地表示变量的正态性:

可以看到,所表示的偏离的数据点距离直线很远。
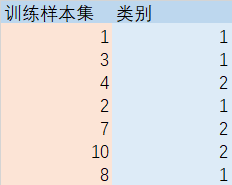
下面解读离散数据,因为其中有所有分类:


为了将结果可视化,我们需要用到下图所示的盒状图:











 京公网安备 11010802041100号 | 京ICP备19059560号-4 | PHP1.CN 第一PHP社区 版权所有
京公网安备 11010802041100号 | 京ICP备19059560号-4 | PHP1.CN 第一PHP社区 版权所有 