常用Action算子
- countByKey
- collect
- reduce
- fold
- first
- take
- top
- count
- takeSample
- takeOrdered
- foreach
- saveAsTextFile
- countByKey()
返回值是一个 字典类型
rdd1 = sc.textFile(f"file:///{ROOT}/data/input/words.txt")
rdd2 = rdd1.flatMap(lambda x:x.split(" ")).map(lambda x:(x,1))
print(rdd2.collect())
res = rdd2.countByKey()
print(res)
print(type(res))
- collect()
将RDD各分区数据统一收集到Driver 形成一个List对象
确定数据量不是太大 不然会把Driver 内存撑爆
- reduce()
将RDD数据集 进行聚合,返回值就是传入的数据同类型
注意reduceByKey 返回值是RDD
rdd = sc.parallelize([1, 2, 3, 4, 5])
res = rdd.reduce(lambda a,b:a+b)
res
- fold

初始值 在分区内 和 分区间 都会作用
一般不使用
- first()
RDD的第一个元素
- take(N)
取RDD的前N个元素 组合成List 返回
- top(N)
对RDD数据进行降序排序 ,取得前N个 组合成List
- count()
计算RDD有多少条数据,返回值是一个数字
-
takeSample(参数1:True or False,参数2:采样数,参数3:随机种子)
参数1: True 表示可以重复取同一个数据
随机抽样RDD数据 返回List
-
takeOrdered(N,参数2)
升序排列
参数2 可以对排序数据进行改变 不改变本身
对RDD进行排序 取前N个
rdd = sc.parallelize([1, 3, 2, 4, 7, 9, 6], 1)
print(rdd.takeOrdered(3))
print(rdd.takeOrdered(3, lambda x: -x))
- foreach(func)
对RDD每一个元素 执行提供的逻辑操作(同map)也不改变传入的RDD 但是没有返回值
rdd = sc.parallelize([1, 2, 3, 4, 5])
rdd2 = rdd.foreach(lambda x:print(x*10) )
print(rdd2)
20
10
30
40
50
None
- saveasTextFile()
rdd = sc.parallelize([1, 3, 2, 4, 7, 9, 6], 1)
rdd.saveAsTextFile(f"file:///{ROOT}/data/output/out1")
rdd.saveTextFile("hdfs://hadoop102:8080/路径")
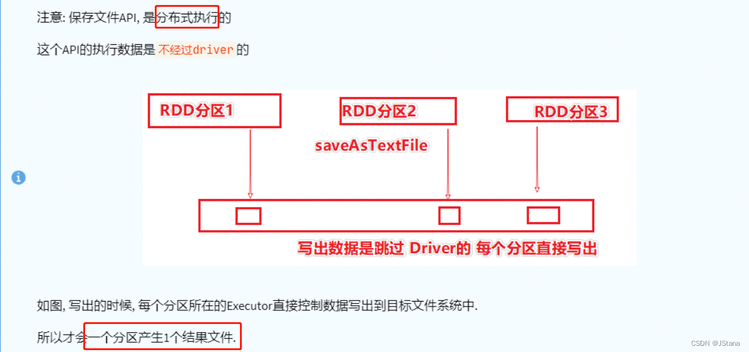
foreach; saveAsTextFile 都是由分区(Excutor)直接执行的,跳过Driver
其余的 Action 算子都会将结果发送至Driver






 京公网安备 11010802041100号
京公网安备 11010802041100号