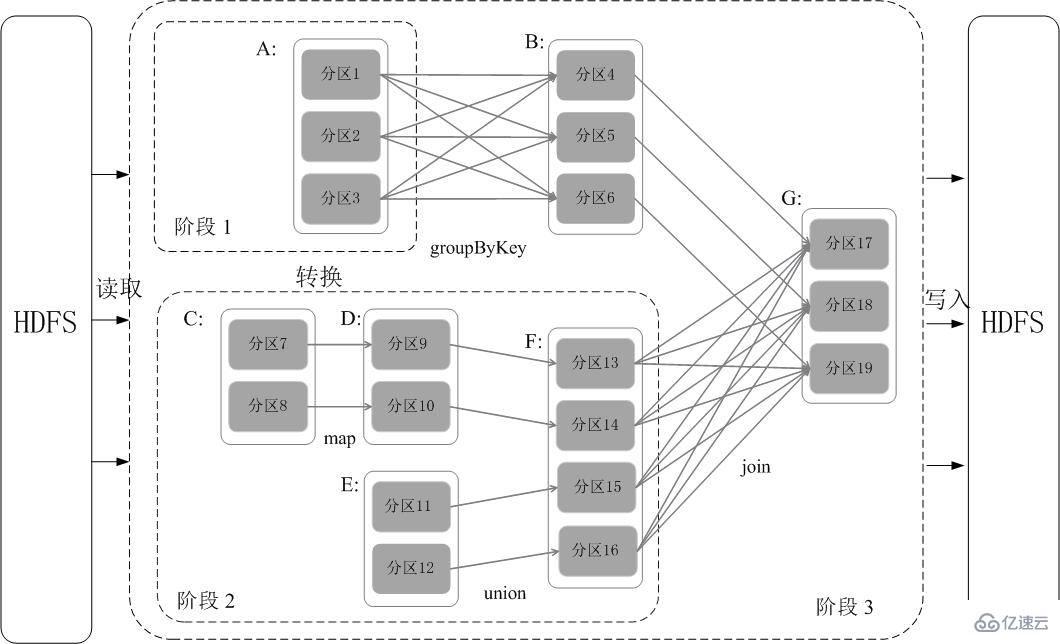
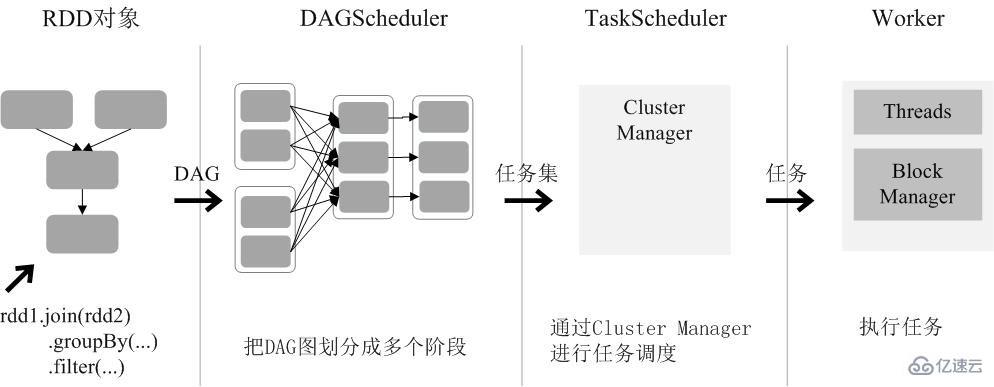
Spark 通过分析各个 RDD 的依赖关系生成了 DAG ,再通过分析各个 RDD 中的分区之间的依赖关系来决定如何划分阶段,具体划分方法是:在 DAG 中进行反向解析,遇到宽依赖就断开,遇到窄依赖就把当前的 RDD 加入到当前的阶段中;将窄依赖尽量划分在同一个阶段中,可以实现流水线计算。例如在下图中,首先根据数据的读取、转化和行为等操作生成 DAG。然后在执行行为操作时,反向解析 DAG,由于从 A 到 B 的转换和从 B、F 到 G 的转换都属于宽依赖,则需要从在宽依赖处进行断开,从而划分为三个阶段。把一个 DAG 图划分成多个 “阶段” 以后,每个阶段都代表了一组关联的、相互之间没有 Shuffle 依赖关系的任务组成的任务集合。每个任务集合会被提交给任务调度器(TaskScheduler)进行处理,由任务调度器将任务分发给 Executor 运行。








 京公网安备 11010802041100号
京公网安备 11010802041100号