作者:TiaoHun35p_376 | 来源:互联网 | 2023-09-24 13:52
这三种网络结构主要是用于物体的检测以及识别。一、RCNN:首先使用搜索算法(SelectiveSearch)在图像上面选取出来大约2k个候选框,然后将这些候选框都送入到网络中进行特
这三种网络结构主要是用于物体的检测以及识别。
一、RCNN:
首先使用搜索算法(SelectiveSearch)在图像上面选取出来大约2k个候选框,然后将这些候选框都送入到网络中进行特征提取,然后在对其进行分类与回归。

RCNN存在三个明显的问题:
1)多个候选区域对应的图像需要预先提取,占用较大的磁盘空间;
2)针对传统CNN需要固定尺寸的输入图像,crop/warp(归一化)产生物体截断或拉伸,会导致输入CNN的信息丢失;
3)每一个ProposalRegion都需要进入CNN网络计算,上千个Region存在大量的范围重叠,重复的特征提取带来巨大的计算浪费。
二、Fast RCNN
为了解决以上的问题,fast rcnn主要引进了2个方面。
1、提取候选框的时间上,fast rcnn首先直接对图片进行特征提去,然后在卷积的最后一层使用搜索算法(SelectiveSearch)对特征进行候选框提取,
在通过ROI Pooling对提取的候选框进行Warp到统一的大小格式。
2、A)SoftmaxLoss代替了SVM,证明了softmax比SVM更好的效果;
B)SmoothL1Loss取代Bouding box回归。
将分类和边框回归进行合并(又一个开创性的思路),通过多任务Loss层进一步整合深度网络,统一了训练过程,从而提高了算法准确度。
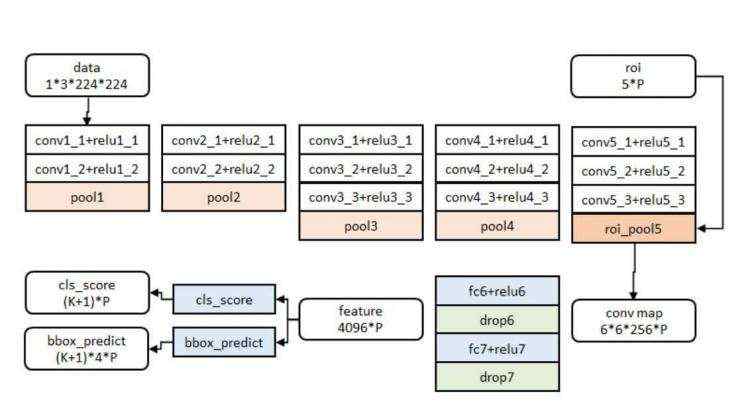
三、Faster RCNN
faster rcnn主要是在提取特征上面进行了修改,加快了模型的处理速度以及精准度。
使用RPN网络代替fast rcnn的搜索算法(SelectiveSearch)对特征进行自动的候选框提取,使得网络得到的候选框质量更高、更好。(具体的思路查看:https://i.cnblogs.com/EditArticles.aspx?postid=8491734&update=1)
参考网站:
http://blog.csdn.net/linolzhang/article/details/54344350



![Python3爬虫入门:pyspider的基本使用[python爬虫入门]](https://img1.php1.cn/3cdc5/324f/339/9d0ec9721f26646a.jpeg)

 京公网安备 11010802041100号
京公网安备 11010802041100号