代码地址:新建标签页 (github.com)
视频:https://www.bilibili.com/video/BV1dU4y1C7so/?p=4&vd_source=91219057315288b0881021e879825aa3
from datasets import load_dataset
dataset = load_dataset("./data/clone/squad")
dataset.save_to_disk('./data/squad')
因为无法访问外网,这里先用git把数据集下下来,然后加载。
from transformers import AutoTokenizer
#加载分词工具
tokenizer = AutoTokenizer.from_pretrained('distilbert-base-uncased')
#采样,数据量太大了跑不动
dataset['train'] = dataset['train'].shuffle().select(range(10000))
dataset['validation'] = dataset['validation'].shuffle().select(range(200))
print(dataset['train'][0])
dataset

#从官方教程里抄出来的函数,总之就是squad数据的处理函数,过程非常复杂,即使是官方的实现也是有问题的,我实在没本事写这个
def prepare_train_features(examples):
examples["question"] = [q.lstrip() for q in examples["question"]]
tokenized_examples = tokenizer(
examples['question'],
examples['context'],
truncation='only_second',
max_length=384,
stride=128,
return_overflowing_tokens=True,
return_offsets_mapping=True,
padding='max_length',
)
sample_mapping = tokenized_examples.pop("overflow_to_sample_mapping")
offset_mapping = tokenized_examples.pop("offset_mapping")
tokenized_examples["start_positions"] = []
tokenized_examples["end_positions"] = []
for i, offsets in enumerate(offset_mapping):
input_ids = tokenized_examples["input_ids"][i]
cls_index = input_ids.index(tokenizer.cls_token_id)
sequence_ids = tokenized_examples.sequence_ids(i)
sample_index = sample_mapping[i]
answers = examples["answers"][sample_index]
if len(answers["answer_start"]) == 0:
tokenized_examples["start_positions"].append(cls_index)
tokenized_examples["end_positions"].append(cls_index)
else:
start_char = answers["answer_start"][0]
end_char = start_char + len(answers["text"][0])
token_start_index = 0
while sequence_ids[token_start_index] != 1:
token_start_index += 1
token_end_index = len(input_ids) - 1
while sequence_ids[token_end_index] != 1:
token_end_index -= 1
if not (offsets[token_start_index][0] <= start_char
and offsets[token_end_index][1] >= end_char):
tokenized_examples["start_positions"].append(cls_index)
tokenized_examples["end_positions"].append(cls_index)
else:
while token_start_index
token_start_index += 1
tokenized_examples["start_positions"].append(
token_start_index - 1)
while offsets[token_end_index][1] >= end_char:
token_end_index -= 1
tokenized_examples["end_positions"].append(token_end_index + 1)
return tokenized_examples
#调用squad数据预处理函数
examples = prepare_train_features(dataset['train'][:3])
#先看看处理后的结果
for k, v in examples.items():
print(k, len(v), v)
print()
#还原成文字查看,很显然,即使是huggingface的实现也是有问题的
for i in range(len(examples['input_ids'])):
input_ids = examples['input_ids'][i]
start_positiOns= examples['start_positions'][i]
end_positiOns= examples['end_positions'][i]
print('问题和文本')
question_and_cOntext= tokenizer.decode(input_ids)
print(question_and_context)
print('答案')
answer = tokenizer.decode(input_ids[start_positions:end_positions])
print(answer)
print('原答案')
original_answer = dataset['train'][i]['answers']['text'][0]
print(original_answer)
print()
#应用预处理函数
dataset = dataset.map(
function=prepare_train_features,
batched=True,
remove_columns=['id', 'title', 'context', 'question', 'answers'])
print(dataset['train'][0])
dataset
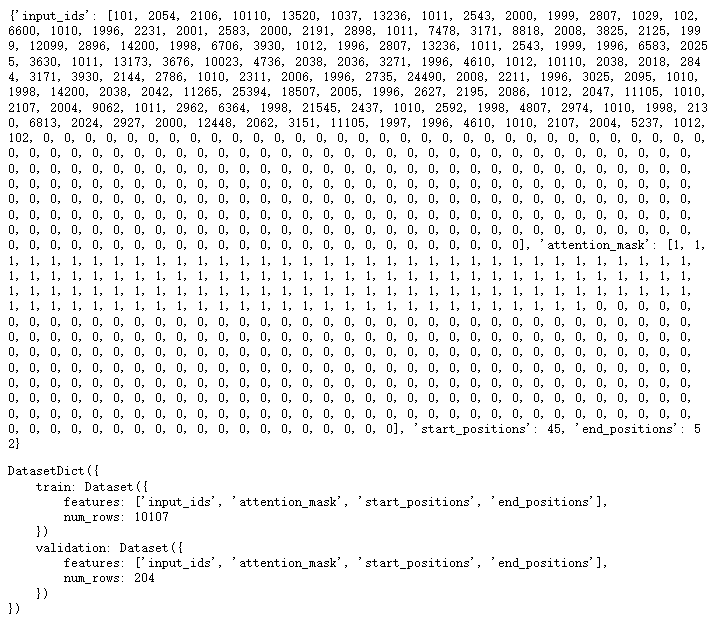
import torch
from transformers.data.data_collator import default_data_collator
#数据加载器
loader = torch.utils.data.DataLoader(
dataset=dataset['train'],
batch_size=8,
collate_fn=default_data_collator,
shuffle=True,
drop_last=True,
)
for i, data in enumerate(loader):
break
data
def try_gpu(i=0):
"""如果存在,则返回gpu(i),否则返回cpu()。"""
if torch.cuda.device_count() >= i + 1:
return torch.device(f'cuda:{i}')
return torch.device('cpu')
def try_all_gpus():
"""返回所有可用的GPU,如果没有GPU,则返回[cpu(),]。"""
devices = [
torch.device(f'cuda:{i}') for i in range(torch.cuda.device_count())]
return devices if devices else [torch.device('cpu')]
device = try_gpu()
from transformers import AutoModelForQuestionAnswering, DistilBertModel
#加载模型
#model = AutoModelForQuestionAnswering.from_pretrained('distilbert-base-uncased')
#定义下游任务模型
class Model(torch.nn.Module):
def __init__(self):
super().__init__()
self.pretrained = DistilBertModel.from_pretrained(
'distilbert-base-uncased')
self.fc = torch.nn.Sequential(torch.nn.Dropout(0.1),
torch.nn.Linear(768, 2))
#加载预训练模型的参数
parameters = AutoModelForQuestionAnswering.from_pretrained('distilbert-base-uncased')
self.fc[1].load_state_dict(parameters.qa_outputs.state_dict())
def forward(self, input_ids, attention_mask, start_positions,
end_positions):
# 放在gpu上训练
if torch.cuda.is_available():
input_ids = input_ids.to(device)
attention_mask = attention_mask.to(device)
start_positiOns= start_positions.to(device)
end_positiOns= end_positions.to(device)
#[b, lens] -> [b, lens, 768]
logits = self.pretrained(input_ids=input_ids,
attention_mask=attention_mask)
logits = logits.last_hidden_state
#[b, lens, 768] -> [b, lens, 2]
logits = self.fc(logits)
#[b, lens, 2] -> [b, lens, 1],[b, lens, 1]
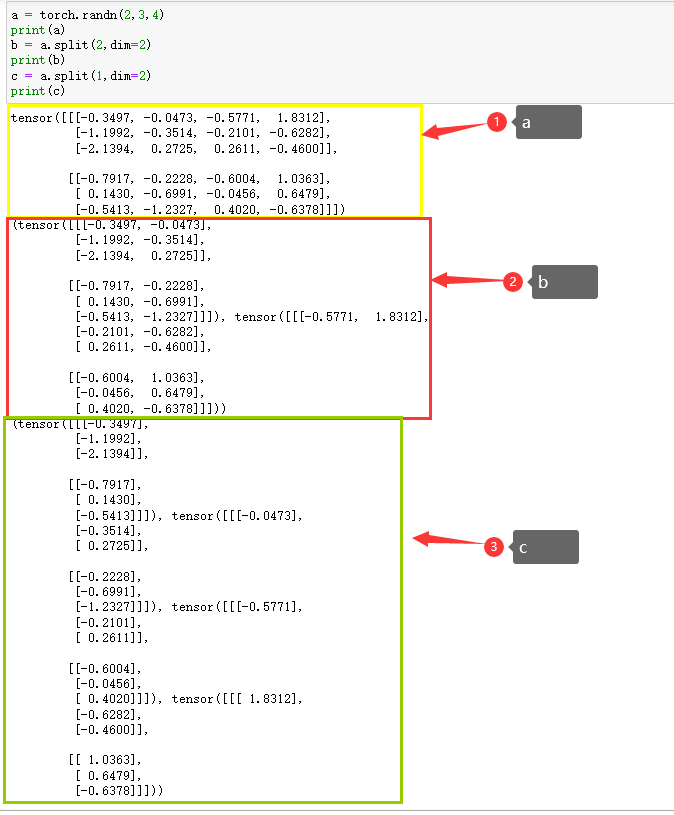
start_logits, end_logits = logits.split(1, dim=2)
#[b, lens, 1] -> [b, lens]
start_logits = start_logits.squeeze(2)
end_logits = end_logits.squeeze(2)
#起点和终点都不能超出句子的长度
lens = start_logits.shape[1]
start_positiOns= start_positions.clamp(0, lens)
end_positiOns= end_positions.clamp(0, lens)
criterion = torch.nn.CrossEntropyLoss(ignore_index=lens)
start_loss = criterion(start_logits, start_positions)
end_loss = criterion(end_logits, end_positions)
loss = (start_loss + end_loss) / 2
return {
'loss': loss,
'start_logits': start_logits,
'end_logits': end_logits
}
model = Model()
model = model.to(device)
#统计参数量
print(sum(i.numel() for i in model.parameters()) / 10000)
out = model(**data)
out['loss'], out['start_logits'].shape, out['end_logits'].shape
distilbert-base-uncased: 基于bert-base-uncased的蒸馏(压缩)模型, 编码器具有6个隐层, 输出768维张量, 12个自注意力头, 共66M参数量。 DistilBERT 是一种小型、快速、廉价和轻量级的 Transformer 模型,通过蒸馏 BERT 基础进行训练。 根据 GLUE 语言理解基准测试,它的参数比 Bert-base-uncased 少 40%,运行速度提高 60%,同时保持 BERT 95% 以上的性能。
5分钟NLP:使用 Hugging Face 微调BERT 并使用 TensorBoard 可视化 - 知乎 (zhihu.com)
BERT预训练模型的使用_熊思健WHUT的博客-CSDN博客_bert预训练模型怎么用
huggingface文档的介绍

官网说这个模型适合用在question answering上面
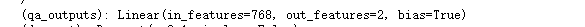
一分钟带你认识深度学习中的知识蒸馏 - 知乎 (zhihu.com)
pytorch把所有的模型参数用一个内部定义的dict进行保存,自称为“state_dict”。这个所谓的state_dict就是不带模型结构的模型参数加载state_dict参数。
#测试
def test():
model.eval()
#数据加载器
loader_val = torch.utils.data.DataLoader(
dataset=dataset['validation'],
batch_size=16,
collate_fn=default_data_collator,
shuffle=True,
drop_last=True,
)
start_offset = 0
end_offset = 0
total = 0
for i, data in enumerate(loader_val):
#计算
with torch.no_grad():
out = model(**data)
start_offset += (out['start_logits'].argmax(dim=1) -
data['start_positions']).abs().sum().item()
end_offset += (out['end_logits'].argmax(dim=1) -
data['end_positions']).abs().sum().item()
total += 16
if i % 10 == 0:
print(i)
if i == 50:
break
print(start_offset / total, end_offset / total)
start_logits = out['start_logits'].argmax(dim=1)
end_logits = out['end_logits'].argmax(dim=1)
for i in range(4):
input_ids = data['input_ids'][i]
pred_answer = input_ids[start_logits[i]:end_logits[i]]
label_answer = input_ids[
data['start_positions'][i]:data['end_positions'][i]]
print('input_ids=', tokenizer.decode(input_ids))
print('pred_answer=', tokenizer.decode(pred_answer))
print('label_answer=', tokenizer.decode(label_answer))
print()
test()
from transformers import AdamW
from transformers.optimization import get_scheduler
#训练
def train():
optimizer = AdamW(model.parameters(), lr=2e-5)
scheduler = get_scheduler(name='linear',
num_warmup_steps=0,
num_training_steps=len(loader),
optimizer=optimizer)
model.train()
for i, data in enumerate(loader):
out = model(**data)
loss = out['loss']
loss.backward()
torch.nn.utils.clip_grad_norm_(model.parameters(), 1.0)
optimizer.step()
scheduler.step()
optimizer.zero_grad()
model.zero_grad()
if i % 50 == 0:
lr = optimizer.state_dict()['param_groups'][0]['lr']
start_offset = (out['start_logits'].argmax(dim=1) -
data['start_positions']).abs().sum().item() / 8
end_offset = (out['end_logits'].argmax(dim=1) -
data['end_positions']).abs().sum().item() / 8
print(i, loss.item(), lr, start_offset, end_offset)
# model文件夹提前创建好
torch.save(model, './models/3.阅读理解.model')
train()
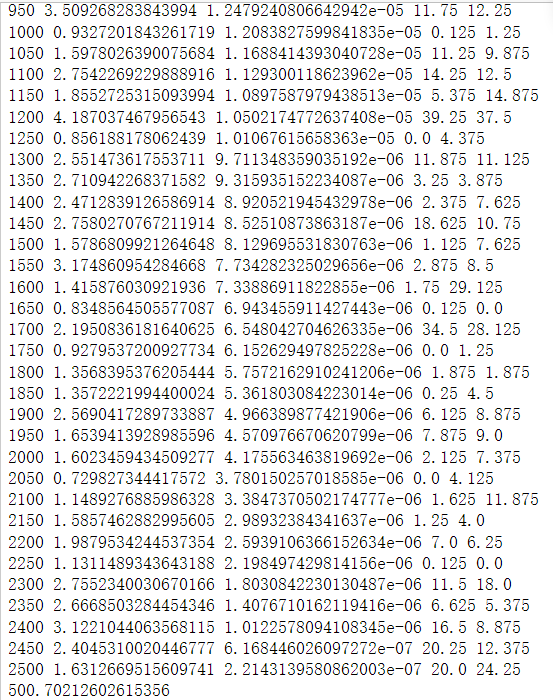
optimizer.step()和scheduler.step()是我们在训练网络之前都需要设置。我理解的是optimizer是指定使用哪个优化器,scheduler是对优化器的学习率进行调整,正常情况下训练的步骤越大,学习率应该变得越小。optimizer.step()通常用在每个mini-batch之中,而scheduler.step()通常用在epoch里面,但是不绝对。可以根据具体的需求来做。只有用了optimizer.step(),模型才会更新,而scheduler.step()是对lr进行调整。通常我们在scheduler的step_size表示scheduler.step()每调用step_size次,对应的学习率就会按照策略调整一次。所以如果scheduler.step()是放在mini-batch里面,那么step_size指的是经过这么多次迭代,学习率改变一次。
训练时的学习率调整:optimizer和scheduler - 知乎 (zhihu.com)
model = torch.load('models/3.阅读理解.model')
test()

torch.nn.DataParallel
【Pytorch】多GPU并行与显存管理_ccamelliatree的博客-CSDN博客
报错内容:AttributeError: 'dict' object has no attribute 'cuda'
解决方法:data = {key:data[key].to(device) for key in data}
'dict' object has no attribute 'cuda'的解决方法_York1996的博客-CSDN博客




 京公网安备 11010802041100号 | 京ICP备19059560号-4 | PHP1.CN 第一PHP社区 版权所有
京公网安备 11010802041100号 | 京ICP备19059560号-4 | PHP1.CN 第一PHP社区 版权所有