1 Solr介绍
1.1 什么是solr
Solr 是Apache下的一个顶级开源项目,采用Java开发,它是基于Lucene的全文搜索服务器。Solr可以独立运行在Jetty、Tomcat等这些Servlet容器中。
Solr提供了比Lucene更为丰富的查询语言,同时实现了可配置、可扩展,并对索引、搜索性能进行了优化。
使用Solr 进行创建索引和搜索索引的实现方法很简单,如下:
l 创建索引:客户端(可以是浏览器可以是Java程序)用 POST 方法向 Solr 服务器发送一个描述 Field 及其内容的 XML 文档,Solr服务器根据xml文档添加、删除、更新索引 。
l 搜索索引:客户端(可以是浏览器可以是Java程序)用 GET方法向 Solr 服务器发送请求,然后对 Solr服务器返回Xml、json等格式的查询结果进行解析,组织页面布局。Solr不提供构建页面UI的功能,但是Solr提供了一个管理界面,通过管理界面可以查询Solr的配置和运行情况。
1.2 Solr和Lucene的区别
Lucene是一个开放源代码的全文检索引擎工具包,它不是一个完整的全文检索应用。Lucene仅提供了完整的查询引擎和索引引擎,目的是为软件开发人员提供一个简单易用的工具包,以方便的在目标系统中实现全文检索的功能,或者以Lucene为基础构建全文检索应用。
Solr的目标是打造一款企业级的搜索引擎系统,它是基于Lucene一个搜索引擎服务,可以独立运行,通过Solr可以非常快速的构建企业的搜索引擎,通过Solr也可以高效的完成站内搜索功能。
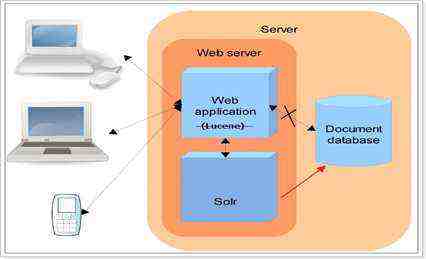
2 Solr安装配置
2.1 SolrCore配置
2.1.1 SolrHome和SolrCore
SolrHome是Solr运行的主目录,该目录中包括了多个SolrCore目录。SolrCore目录中包含了运行Solr实例所有的配置文件和数据文件,Solr实例就是SolrCore。
一个SolrHome可以包括多个SolrCore(Solr实例),每个SolrCore提供单独的搜索和索引服务。
2.1.2 目录结构
SolrHome目录:

SolrCore目录:

2.1.2 创建SolrCore
创建SolrCore先要创建SolrHome。在solr解压包下solr-4.10.3\example\solr文件夹就是一个标准的SolrHome。
l 拷贝solr解压包下solr-4.10.3\example\solr文件夹。
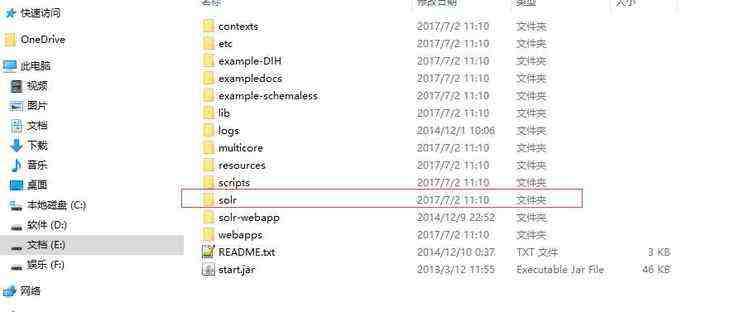
l 复制该文件夹到本地的一个目录,把文件名称改为mySolrHome。
注:改名不是必须的,只是为了便于理解

进入此目录
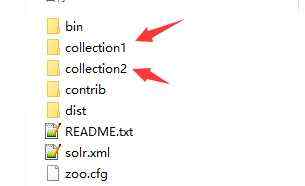
SolrCore创建成功。
2.1.3 配置SolrCore
在conf文件夹下有一个solrconfig.xml。这个文件是来配置SolrCore实例的相关信息。如果使用默认配置可以不用做任何修改。它里面包含了不少标签,但是我们关注的标签为:lib标签、datadir标签、requestHandler标签。
2.1.4 lib 标签
将contrib和dist两个目录拷贝到mySolrHome目录下;
在solrconfig.xml中可以加载一些扩展的jar,solr.install.dir表示solrCore的目录位置,需要如下修改:
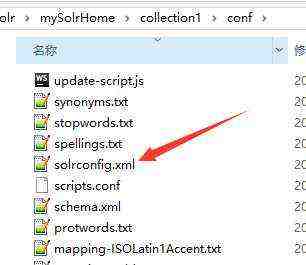

注意:把../..改为自己jar包存放的路径,才可以找到相关jar包。也可以配置相对路径:
2.2 datadir标签
每个SolrCore都有自己的索引文件目录 ,默认在SolrCore目录下的data中。

data数据目录下包括了index索引目录 和tlog日志文件目录。
如果不想使用默认的目录也可以通过solrConfig.xml更改索引目录 ,如下:

2.3 requestHandler标签
requestHandler请求处理器,定义了索引和搜索的访问方式。
通过/update维护索引,可以完成索引的添加、修改、删除操作。
提交xml、json数据完成索引维护,索引维护小节详细介绍。
通过/select搜索索引。
设置搜索参数完成搜索,搜索参数也可以设置一些默认值,如下:
explicit
10
json
text
3 Solr工程部署
由于在项目中用到的web服务器大多数是用的Tomcat,所以就讲solr和Tomcat的整合。
3.1 安装Tomcat
3.2 把solr.war部署到Tomcat中
1、 从solr解压包下的solr-4.10.3\example\webapps目录中拷贝solr.war
3.3 添加solr服务的扩展依赖包(日志包)
l 把solr解压包下的solr-4.10.3\example\lib\ext目录下的所有jar包拷贝。
l 复制到解压缩后的solr工程的WEB-INF\lib目录
3.4 添加log4j.properties
1、 把solr解压包下solr-4.10.3\example\resources\log4j.properties文件进行拷贝
2、 在解压缩后的solr工程中的WEB-INF目录中创建classes文件夹
3、 复制log4j.properties文件到刚创建的classes目录
3.5 在solr应用的web.xml文件中,加载SolrHome
修改web.xml使用jndi的方式告诉solr服务器。
Solr/home名称必须是固定的。

4 启动Tomcat进行访问
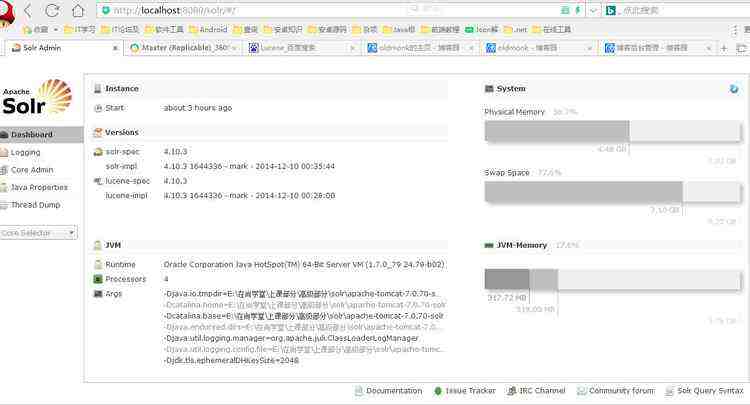
先启动部署了solr项目的tomcat服务器,再访问http://localhost:8080/solr/
出现以下界面则说明solr安装成功!!!
5 Solrj的使用
5.1 什么是solrj
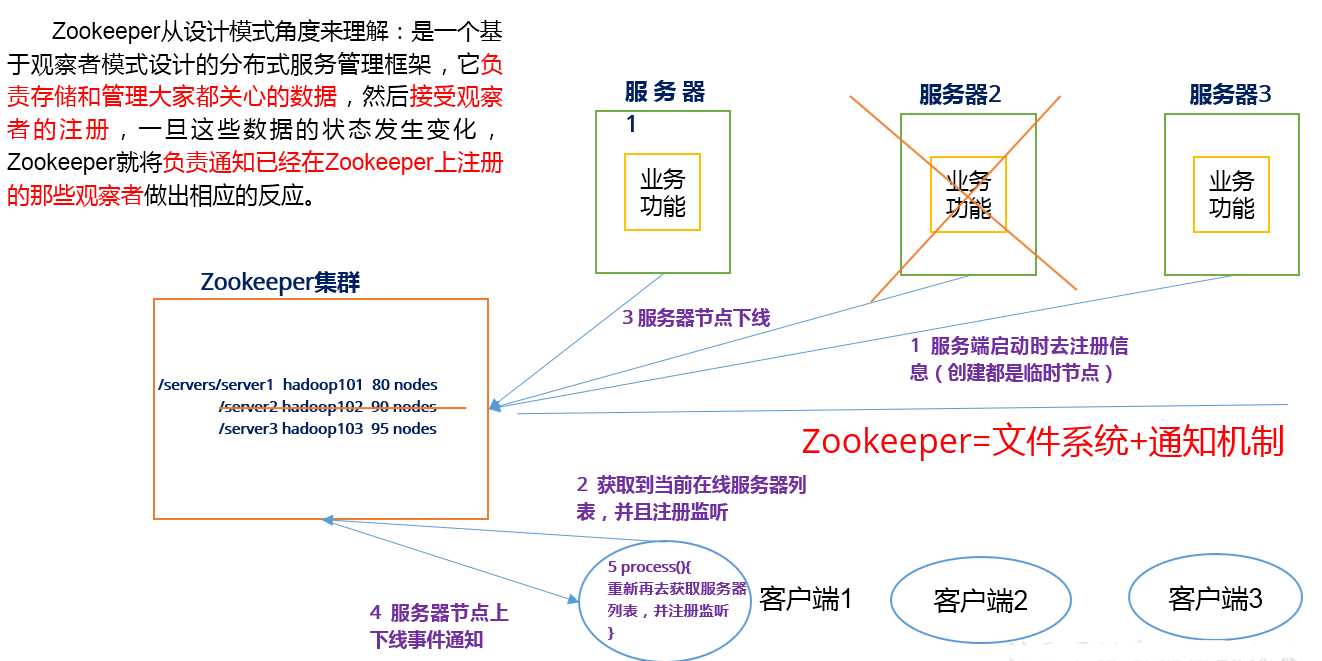
solrj是访问Solr服务的java客户端,提供索引和搜索的请求方法,SolrJ通常在嵌入在业务系统中,通过SolrJ的API接口操作Solr服务,如下图:

Solrj和图形界面操作的区别就类似于数据库中你使用jdbc和mysql客户端的区别一样。
代码示例:
1 添加jar

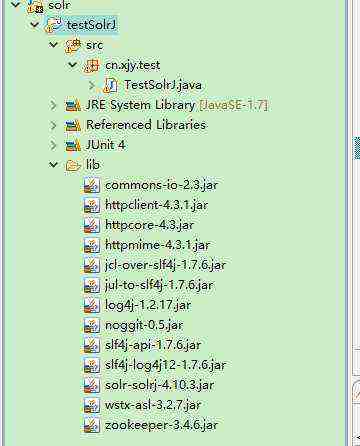


1 package cn.xjy.test ;
2
3 import java.io.IOException ;
4 import org.apache.solr.client.solrj.SolrQuery ;
5 import org.apache.solr.client.solrj.SolrQuery.ORDER ;
6 import org.apache.solr.client.solrj.SolrServer ;
7 import org.apache.solr.client.solrj.impl.HttpSolrServer ;
8 import org.apache.solr.client.solrj.response.QueryResponse ;
9 import org.apache.solr.common.SolrDocument ;
10 import org.apache.solr.common.SolrDocumentList ;
11 import org.apache.solr.common.SolrInputDocument ;
12 import org.junit.Before ;
13 import org.junit.Test ;
14
15 public class TestSolrJ {
16
17 SolrServer solrServer = null ;
18
19 @Before
20 public void init() {
21 // 1、 创建HttpSolrServer对象,通过它和Solr服务器建立连接。
22 // 参数:solr服务器的访问地址
23 solrServer = new HttpSolrServer("http://localhost:8080/solr/collection2") ;
24 }
25
26 /**
27 * 更新或添加
28 * 存在就更新,不存在就添加(根据id判断)
29 * @throws Exception
30 * @throws IOException
31 */
32 @Test
33 public void testAddandUpdate() throws Exception, IOException {
34
35 // 2、 创建SolrInputDocument对象,然后通过它来添加域。
36 SolrInputDocument doc = new SolrInputDocument() ;
37
38 /* 测试添加 */
39 /* doc.addField("id","测试1"); doc.addField("product_name","测试name");
40 * doc.addField("product_catalog_name","测试product_catalog_name");
41 * doc.addField("product_price",22f);
42 * doc.addField("product_description","测试product_description");
43 * doc.addField("product_picture","测试product_picture"); */
44
45 /* 测试更新 */
46
47 // 第一个参数:域的名称,域的名称必须是在schema.xml中定义的
48 // 第二个参数:域的值
49 // 注意:id的域不能少
50 doc.addField("id", "测试1") ;
51 doc.addField("product_name", "测试更新name") ;
52 doc.addField("product_catalog_name", "测试更新product_catalog_name") ;
53 doc.addField("product_price", 23f) ;
54 doc.addField("product_description", "测试更新product_description") ;
55 doc.addField("product_picture", "测试更新product_picture") ;
56
57 // 3、 通过HttpSolrServer对象将SolrInputDocument添加到索引库。
58 solrServer.add(doc) ;
59
60 // 4、 提交。
61 solrServer.commit() ;
62
63 }
64
65 /**
66 * 删除索引
67 * @throws Exception
68 */
69 @Test
70 public void testDelete() throws Exception {
71 // 根据id删除
72 /* solrServer.deleteById("测试1") ; solrServer.commit(); */
73
74 // 根据条件删除
75 solrServer.deleteByQuery("product_price:23") ;
76
77 // 全部删除
78 // solrServer.deleteByQuery("*:*");
79 solrServer.commit() ;
80 }
81
82 /**
83 * 简单查询
84 * @throws Exception
85 */
86 @Test
87 public void testSimpleQuery() throws Exception {
88
89 SolrQuery query = new SolrQuery() ;
90 // q是固定的且必须 的
91 query.set("q", "id:测试1") ;
92 query.set("fl", "id,product_catalog_name") ;
93 // query.setFields("id", "product_catalog_name");//效果同上
94
95 QueryResponse queryRespOnse= solrServer.query(query) ;
96
97 SolrDocumentList results = queryResponse.getResults() ;
98
99 System.out.println("总数:" + results.getNumFound()) ;
100
101 for (SolrDocument solrDocument : results) {
102 // System.out.println(solrDocument.get("id")) ;
103 System.out.println(solrDocument) ;
104 }
105 }
106
107 /**
108 * 复杂查询
109 * @throws Exception
110 */
111 @Test
112 public void testComplexQuery() throws Exception {
113 SolrServer solrServer2 = new HttpSolrServer("http://localhost:8080/solr") ;
114
115 SolrQuery query = new SolrQuery() ;
116
117 // 查询条件
118 query.setQuery("*:*") ;
119
120 // 过滤条件
121 query.setFilterQueries("product_catalog_name:幽默杂货") ;
122
123 // 按指定字段排序
124 query.setSort("id", ORDER.desc) ;
125
126 // 分页
127 query.setStart(0) ;
128 query.setRows(100) ;
129
130 // 设置要显示的字段
131 query.setFields("id,product_catalog_name") ;
132
133 // 给特定字段设置样式
134 query.setHighlight(true) ;
135 query.addHighlightField("product_catalog_name") ;
136 query.setHighlightSimplePre("") ;
137 query.setHighlightSimplePost("") ;
138
139 // 查询
140 QueryResponse queryRespOnse= solrServer2.query(query) ;
141
142 // 获得结果集
143 SolrDocumentList results = queryResponse.getResults() ;
144
145 System.out.println("总数:" + results.getNumFound()) ;
146
147 // 遍历结果集
148 for (SolrDocument solrDocument : results) {
149 System.out.println(solrDocument) ;
150 }
151 }
152 }
View Code
全文检索技术---solr




![[c++基础]STL](https://img.php1.cn/3c972/1edc8/c5a/a04ecc977fd8ed28.jpeg)




 京公网安备 11010802041100号
京公网安备 11010802041100号