作者:BIGBANG-YG-BEAR | 来源:互联网 | 2023-09-16 13:03

一、前言
Canal 是阿里的一款开源项目,纯 Java 开发。基于数据库增量日志解析,提供增量数据订阅&消费,目前主要支持了 MySQL(也支持 mariaDB)。
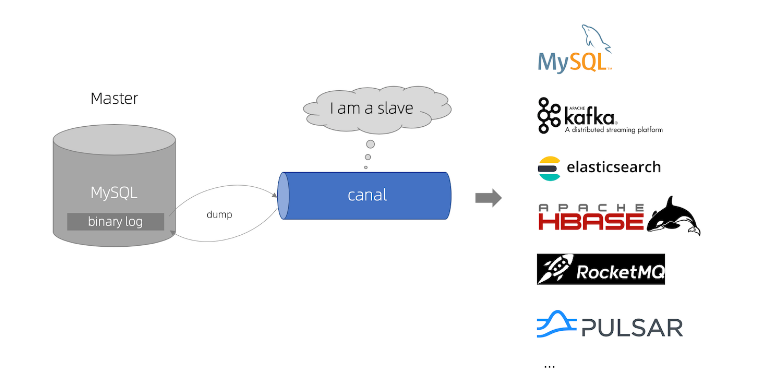
Canal 除了支持 binlog 实时 增量同步 数据库之外也支持 全量同步 ,本文主要分享使用Canal来实现从MySQL到Elasticsearch的全量同步;
可通过使用 adapter 的 REST 接口手动触发 ETL 任务,实现全量同步。
在执行全量同步的时候,同一个 destination 的增量同步任务会被 阻塞,待全量同步完成被阻塞的增量同步会被 重新唤醒
PS:关于Canal的部署与 实时同步 请看文章《Canal高可用架构部署》
二、ETL接口
adapter 的 ETL 接口为:/etl/{type}/{task}
- 默认web端口为
8081 - type 为类型(hbase/es7/rdb)
- task 为任务名对应配置文件名,如sys_user.yml
例子:
curl -X POST http://127.0.0.1:8081/etl/es7/sys_user.yml
执行成功输出:
{"succeeded":true,"resultMessage":"导入ES 数据:17 条"}
三、实践过程中遇到的坑
3.1. 连接池不够
当同步的数据量比较大时,执行一段时间后会出现下图的错误 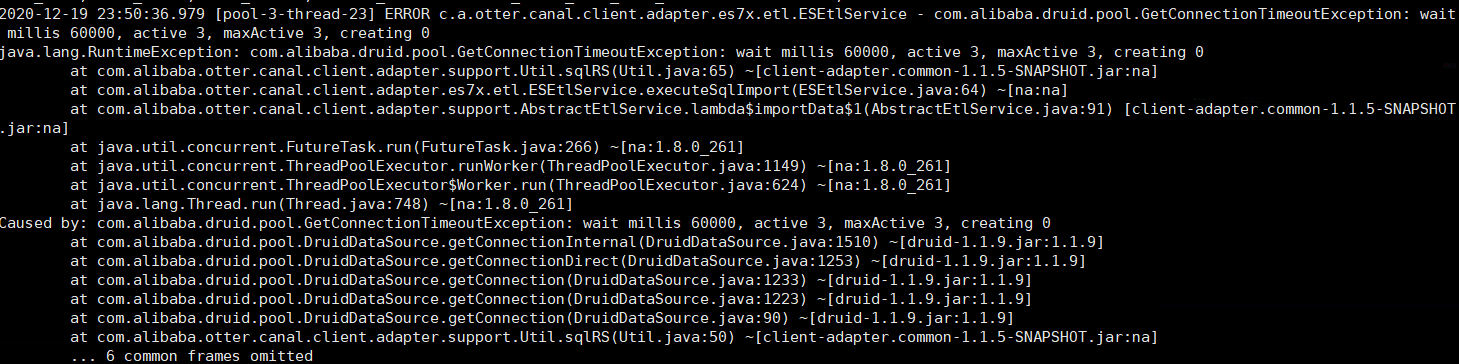
3.1.1. 原因分析
查看 canal 源码得知当同步的数据量大于1w时,会分批进行同步,每批1w条记录,并使用多线程来并行执行任务,而 adapter 默认的连接池为3,当线程获取数据库连接等待超过1分钟就会抛出该异常。
线程数为当前服务器cpu的可用线程数
3.1.2. 解决方式
修改 adapter 的 conf/application.yml 文件中的 srcDataSources 配置项,增加 maxActive 配置数据库的最大连接数为当前服务器cpu的可用线程数
cpu线程数可以下命令查看
grep 'processor' /proc/cpuinfo | sort -u | wc -l
3.2. es连接超时
当同步的表字段比较多时,几率出现以下报错 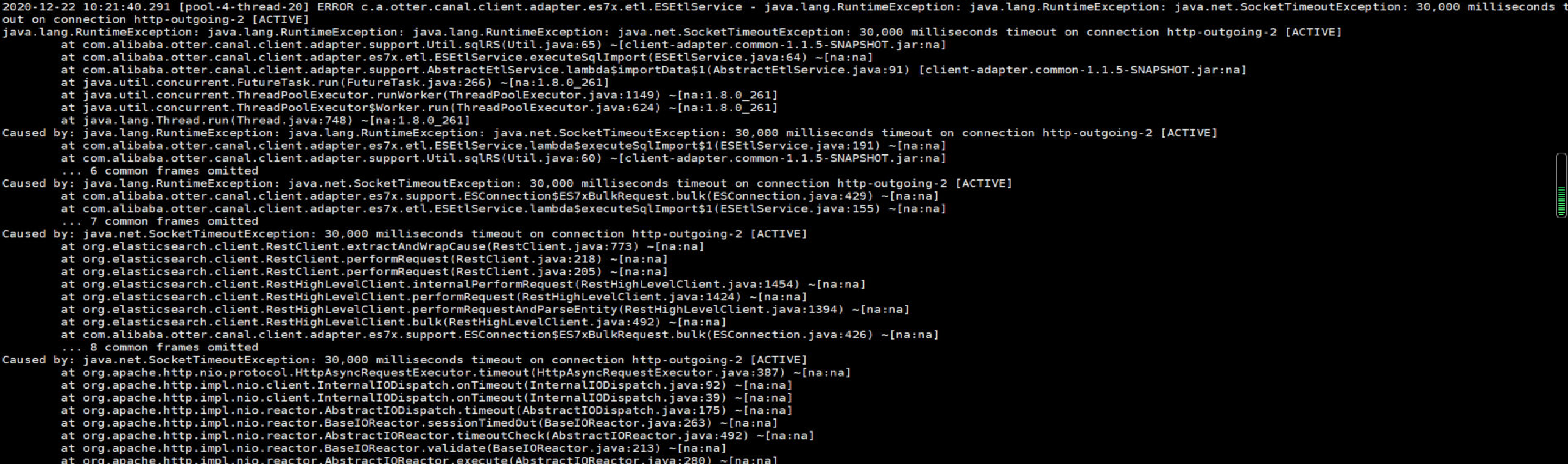
3.2.1. 原因分析
由于 adapter 的表映射配置文件中的 commitBatch 提交批大小设置过大导致(6000)
3.2.2. 解决方式
修改 adapter 的 conf/es7/xxx.yml 映射文件中的 commitBatch 配置项为3000
3.3. 同步慢
三千万的数据量用时3.5小时左右
3.3.1. 原因分析
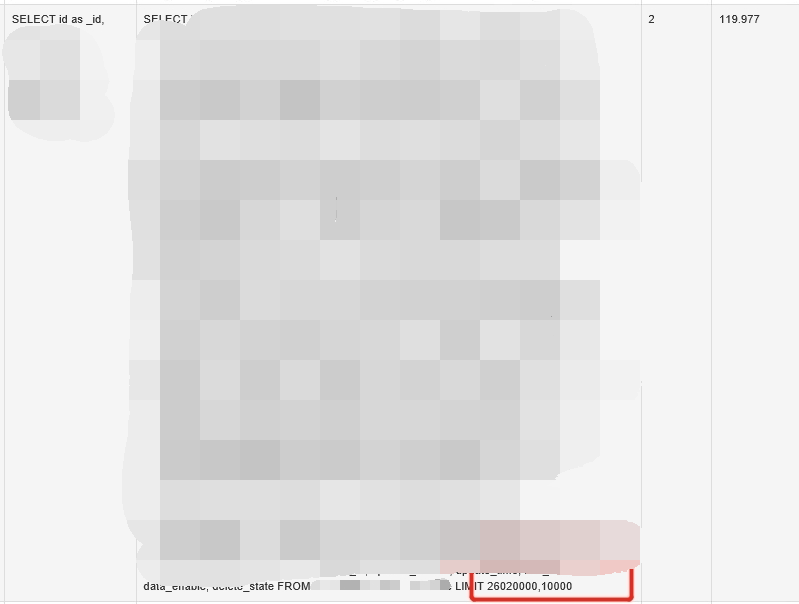
由于当数据量大于1w时 canal 会对数据进行分批同步,每批1w条通过分页查询实现;所以当数据量较大时会出现深分页的情况导致查询非常慢。
3.3.2. 解决方式
预先使用ID、时间或者业务字段等进行数据分批后再进行同步,减少每次同步的数据量。
3.3.3. 案例
使用ID进行数据分批,适合增长类型的ID,如自增ID、雪花ID等;
- 查出 最小ID、最大ID 与 总数据量
- 根据每批数据量大小计算每批的 ID区间
计算过程:
- 最小ID = 1333224842416979257
- 最大ID = 1341698897306914816
- 总数据量 = 3kw
- 每次同步量 = 300w
(1) 计算同步的次数
总数据量 / 每次同步量 = 10
(2) 计算每批ID的增量值
(最大ID - 最小ID) / 次数 = 847405488993555.9
(3) 计算每批ID的值
最小ID + 增量值 = ID2 ID2 + 增量值 = ID3 ... ID9 + 增量值 = 最大ID
(4) 使用分批的ID值进行同步
修改sql映射配置,的 etlCondition 参数:
etlCondition: "where id >= {} and id <{}"
调用etl接口,并增加 params 参数,多个参数之间使用 ; 分割
curl -X POST http://127.0.0.1:8081/etl/es7/sys_user.yml?params=最小ID;ID2 curl -X POST http://127.0.0.1:8081/etl/es7/sys_user.yml?params=ID2;ID3 ...
扫码关注有惊喜!







 京公网安备 11010802041100号
京公网安备 11010802041100号