目录
一、序言
二、序列编码
(a)RNN
(b)CNN
(c)Attention
三、相关文献
1、attention
2、GNN用于用户历史行为建模
2.1 无监督的方法
2.2 有监督的方法
四、总结
1、推荐算法中常用attention、RNN、sumpooling思考
2、GNN对用户历史行为建模得到user-embedding思考
在推荐系统中,能获取的信息有user属性特征、item属性特征、user的历史行为特征、推荐场景有关的环境信息(如金融场景下股市的实时行情信息)。其中user的历史行为特征,具有user和item的交互信息,近年来成为推荐算法研究的重点。
深度学习做NLP的方法,基本上都是先将句子分词,然后每个词转化为对应的词向量序列。这样一来,每个句子都对应的是一个矩阵X=(x1,x2,…,xt),其中xi都代表着第i个词的词向量(行向量),维度为d维,故X∈ℝn×d。这样的话,问题就变成了编码这些序列了。
第一个基本的思路是RNN层,RNN的方案很简单,递归式进行:
yt=f(yt−1,xt)
不管是已经被广泛使用的LSTM、GRU还是最近的SRU,都并未脱离这个递归框架。RNN结构本身比较简单,也很适合序列建模,但RNN的明显缺点之一就是无法并行,因此速度较慢,这是递归的天然缺陷。RNN无法很好地学习到全局的结构信息,当前词的编码只考虑到之前的词,没有考虑到之后的词。
第二个思路是CNN层,其实CNN的方案也是很自然的,窗口式遍历,比如尺寸为3的卷积,就是
yt=f(xt−1,xt,xt+1)
在FaceBook《Convolutional Sequence to Sequence Learning》论文中,纯粹使用卷积也完成了Seq2Seq的学习,是卷积的一个精致且极致的使用案例。CNN方便并行,而且容易捕捉到一些全局的结构信息,但精度一般。
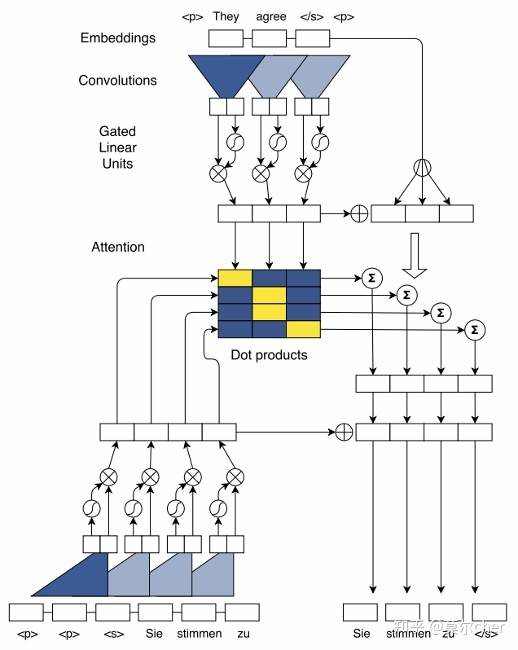
(1)Position Embedding,在输入信息中加入位置向量P=(p1,p2,....),把位置向量与词向量W=(w1,w2,.....)求和构成向量E=(w1+p1,w2+p2),做为网络输入,使由CNN构成的Encoder和Decoder也具备了RNN捕捉输入Sequence中词的位置信息的功能。
(2)捕获long-distance依赖关系。底层的CNN捕捉相聚较近的词之间的依赖关系,高层CNN捕捉较远词之间的依赖关系。通过层次化的结构,实现了类似RNN(LSTM)捕捉长度在20个词以上的Sequence的依赖关系的功能。
(3)效率高。假设一个sequence序列长度为n,采用RNN(LSTM)对其进行建模 需要进行n次操作,时间复杂度O(n)。相比,采用层叠CNN只需要进行n/k次操作,时间复杂度O(n/k),k为卷积窗口大小。
第三个思路:纯Attention,单靠注意力就可以。RNN要逐步递归才能获得全局信息,因此一般要双向RNN才比较好;CNN事实上只能获取局部信息。
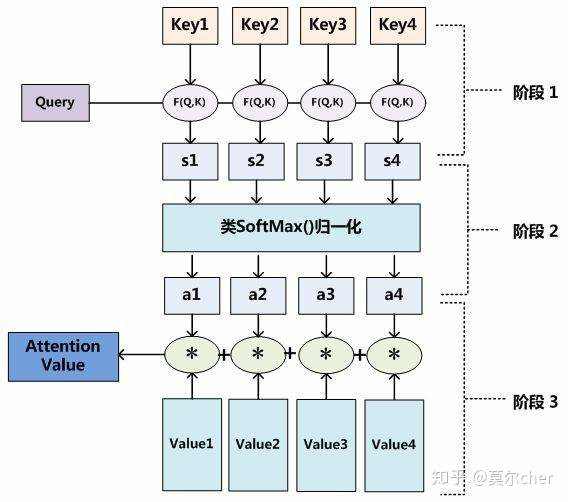
attention函数共有三步完成得到attention value。
- Q与K进行相似度计算得到权值
- 对上部权值归一化
- 用归一化的权值与V加权求和
此时加权求和的结果就为注意力值。公式如下:$$Attention Value = similarity(QK^T)V$$
在自然语言任务中,往往K和V是相同的。这时计算出的attention value是一个向量,代表序列元素xj的编码向量。此向量中包含了元素xj的上下文关系,即包含全局联系也拥有局部联系。全局联系是因为在求相似度的时候,序列中元素与其他所有元素的相似度计算,然后加权得到了编码向量。局部联系可以这么解释,因为它所计算出的attention value是属于当前输入的x_j的。这也就是attention的强大优势之一,它可以灵活的捕捉长期和local依赖,而且是一步到位的。具有以下优点:
(1)一步到位的全局联系捕捉
attention机制可以灵活的捕捉全局和局部的联系,而且是一步到位的。另一方面从attention函数就可以看出来,它先是进行序列的每一个元素与其他元素的对比,在这个过程中每一个元素间的距离都是一,因此它比时间序列RNNs的一步步递推得到长期依赖关系好的多,越长的序列RNNs捕捉长期依赖关系就越弱。
(2)并行计算减少模型训练时间
Attention机制每一步计算不依赖于上一步的计算结果,因此可以和CNN一样并行处理。但是CNN也只是每次捕捉局部信息,通过层叠来获取全局的联系增强视野。
(3)模型复杂度小,参数少
模型复杂度是与CNN和RNN同条件下相比较的。
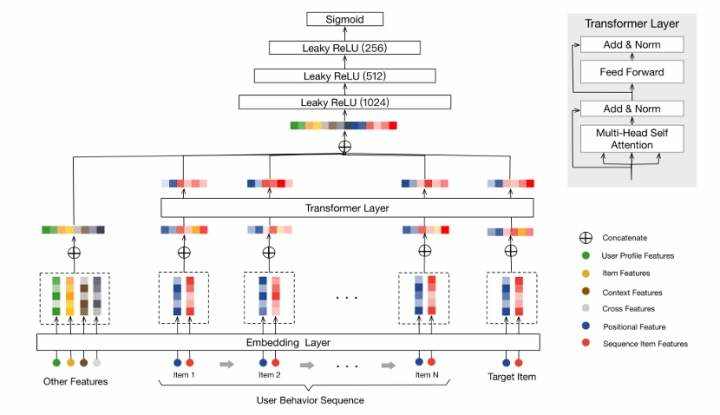
(1) 2019_Behavior Sequence Transformer for E-commerce Recommendation in Alibaba

1、“序列商品特征”包含item_id 和category_id。文中指出,尽管商品特征很多,但发现使用这两个特征效果最好。 2. position emdedding“位置特征”用于捕获序列中的顺序信息,因为Transformer架构不像RNN,前者没有序列顺序的定义。商品vi 的位置值表示为pos(vi) = t(vt) - t(vi),其中 t(vt) 代表推荐时间, t(vi) 是用户点击商品 vi时的时间戳。
(2) 2019_KDD_DSTN
提出将辅助广告信息,有三种类型:上下文广告、用户点击过的广告、用户未点击的广告,用于ctr模型。
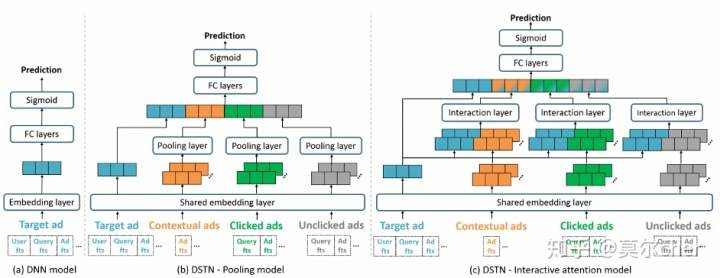
针对这些广告信息, (a)DSTN - Pooling Model 对不同域的广告特征直接做average pooling 再做concat (b)DSTN - Self-Attention Mode 对不同域的广告特征直接做Self-Attention的average pooling 再做concat
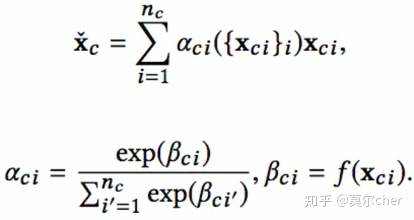
(c)DSTN - Interactive Attention Model 对不同域的广告特征和target广告做Attention的average pooling 再做concat
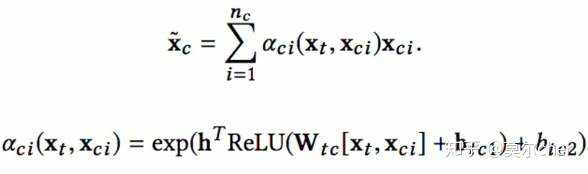
(3)2019_IJCAI_DSIN 主要贡献在于对用户的历史点击行为划分为不同session,对每个session使用Transformer学习session embedding,最后使用BiLSTM对session序列建模。
模型主要由四个部分组成,Session Division Layer是对用户的历史行为划分到不同session,Session Interest Extractor Layer是学习session的表 征,Session Interest Interacting Layer是学习session之间的演变,Session Interest Activating Layer是学习当前item和历史点击session的相关性。
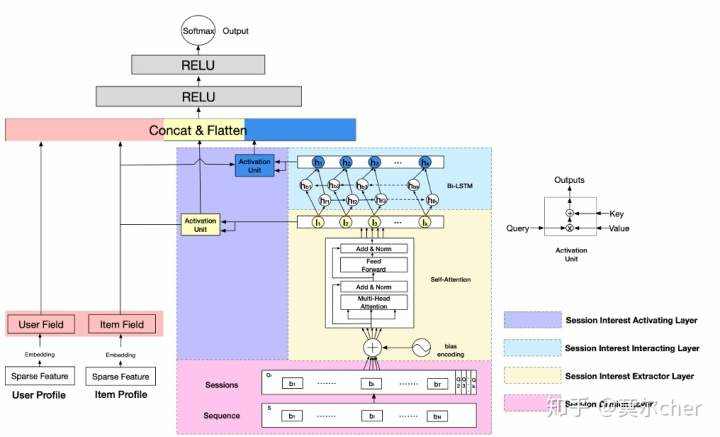
(a)Session Division Layer 主要是将用户的历史点击行为序列划分为多个sessions。这里有一个假设是相同session用户的行为是接近的,比如都是在点一些和裤子相关的商品,而不同session间的用户行为是有差异的,比如后面可能是点一些和洗发水相关的商品。文章将间隔超过30分钟作为session的划分,比如将历史点击序列S转换为session Q ,第 k个session表示为:

其中T是第 k个session的长度, dmodel是输入item的embedding大小。
(b)Session Interest Extractor Layer 这部分主要是获取session表征。用户在相同session内的行为是高度相关的,此外用户在session内的一些随意行为会偏离整个session表达。为了刻画相同session内行为间的相关性,同时减小不相关行为的影响,DSIN使用multi-head self-attention对每个session建模。为了刻画不同session间的顺序,DSIN使用了Bias Encoding。为了刻画不同session的顺序关系,使用bias encoding,定义如下:
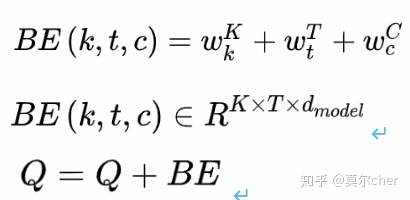
第 k个session中,第 t个物品的embedding向量的第 d 个位置的偏置项。也就是说,对每个session中的每个物品对应的embedding的每个位置,都加入了偏置项。加入bias encoding后,用户的session表示为Q。
(4)2019_AAAI_DIEN
相对于DIN,DIEN对用户行为序列User behavior sequence的处理做了调整。这里包含了3个部分,最底层是Behavior Layer,用于将用户浏览过的商品转换成对应的embedding,并且按照浏览时间做排序,中间层是兴趣提取层Interest Extractor Layer,最上层是兴趣发展层Interest Evolving Layer。
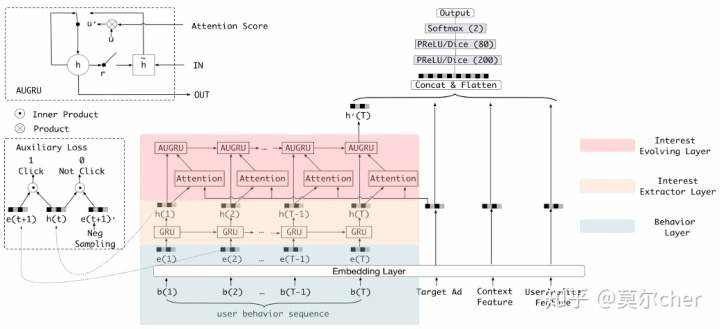
通过引入RNN来发掘和利用行为序列(也就是浏览过的商品序列)中的依赖关系,比直接对行为序列做pooling效果更好。但是这些算法存在的问题就是直接将RNN的隐层输出作为用户的兴趣表示。而商品embedding才是对商品的真实表达,也是对用户兴趣的直接反应,RNN的隐层输出向量未必能够真正表达用户的兴趣。因此兴趣提取层引入了一个有监督学习,强行将RNN输出隐层与商品embedding发生交互,如图中左侧的Auxiliary Loss所示。兴趣提取层采用一个基本的GRU单元。 用户的兴趣表示,兴趣发展层的作用就是捕获与candidate相关的兴趣发展模式,如图中红色区域所示,这里使用了第2个GRU。将candidate的embedding向量与第1个GRU的输出隐向量发生交互,生成attention分数,将attention分数与update gate相乘,替换原始update gate,为AUGRU。
(5)2018_KDD_DIN

将candidate与点击序列中的每个商品发生交互来计算attention分数,论文中还提出了两个小的改进点。一个是对L2正则化的改进,在进行SGD优化的时候,每个mini-batch都只会输入部分训练数据,反向传播只针对部分非零特征参数进行训练,添加上L2之后,需要对整个网络的参数包括所有特征的embedding向量进行训练,这个计算量非常大且不可接受。论文中提出,在每个mini-batch中只对该batch的特征embedding参数进行L2正则化。第二个是提出了一个激活函数Dice。对于Relu或者PRelu来说,rectified point(梯度发生变化的点)都在0值,Dice对每个特征以mini-batch为单位计算均值和方差,然后将rectified point调整到均值位置。
(6)2019_MA-DNN

利用RNN对用户历史行为序列进行建模可以有效提升CTR预估的效果,但是RNN结构的网络通畅比较复杂,而且不太方便进行并行化,这都给该类模型的线上部署与应用带来很大的挑战。所以为了保证模型足够简单的同时,又能更好的对用户历史行为进行建模从而提升预估效果。
从模型结构上来看MA-DNN网络并不复杂,主要包括DNN部分和记忆网络部分,记忆网络部分主要存储两个向量,即mu1和mu0,两者分别用于存储用户“喜欢的内容”和“不喜欢的内容”(后续会讲mu1和mu0的意义)。首先原始用户特征同样通过Embedding层得到稠密的Embedding向量,将不同特征的Embedding向量全部拼接起来形成一个大的Embedding向量x;然后针对每一个用户,从记忆网络中获取用户u的两个向量mu1和mu0,将x、mu1和mu0拼接到一起得到向量v,即v=[x,mu1,mu0];之后将向量v经过几层全连接网络得到最终的预测结果。
GNN在推荐系统中的应用,表征学习。我们都知道在数据结构中,图是一种基础且常用的结构。现实世界中许多场景可以抽象为一种图结构,如社交网络,交通网络,电商网站中用户与物品的关系等。
(a)2014_KDD_Deepwalk DeepWalk最主要的贡献就是他将Network Embedding与自然语言处理中重要的Word Embedding方法Word2Vec联系了起来,使得Network Embedding问题转化为了一个Word Embedding问题。

算法过程:
(1) user的历史行为序列(访问的item序列)构建图网络 (2) 从网络中的每个节点开始分别进行Random Walk 采样,得到局部相关联的训练数据 (3) 对采样数据进行SkipGram训练,将离散的网络节点表示成向量化,最大化节点共现,使用Hierarchical Softmax来做超大规模分类的分类器
(b)LINE LINE不再采用随机游走的方法。相反,他在图上定义了两种相似度:一阶相似度与二阶相似度。
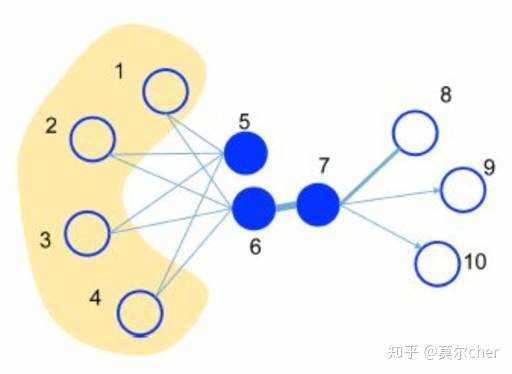
一阶相似度:一阶相似度就是要保证低维的嵌入中要保留两个结点之间的直接联系的紧密程度,换句话说就是保留结点之间的边权,若两个结点之间不存在边,那么他们之间的一阶相似度为0。例如上图中的6、7两个结点就拥有很高的一阶相似度。
二阶相似度:二阶相似度用一句俗话来概括就是“我朋友的朋友也可能是我的朋友”。他所比较的是两个结点邻居的相似程度。若两个结点拥有相同的邻居,他们也更加的相似。如果将邻居看作context,那么两个二阶相似度高的结点之间拥有相似的context。这一点与DeepWalk的目标一致。例如上图中的5、6两点拥有很高的二阶相似度。
LINE的目标就是保留这两种相似度。 LINE的一阶相似度,两个结点实际的一阶相似度表达如下:
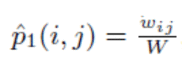
其中W是所有边权重之和。而两个结点embedding之间的相似度为:

其中u是结点的embedding。即两个结点表示的内积套上一个 对率函数的结果。这样一来目标函数设为实际相似度与表示相似度之间的KL散度就可以了,这样一来,只要最小化KL散度(下式中约去了一些常数),就能保证表示相似度尽量接近实际相似度。
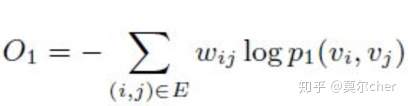
LINE的二阶相似度,两个结点实际的二阶相似度表达式如下:
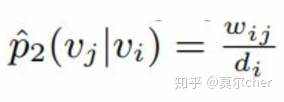
其中wij是边ij的权重,di是结点i的出度。两个结点embedding的相似度为:
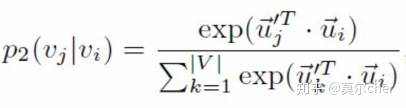
其中V为结点i的所有邻居,这里与一阶相似度不同的地方是,对于邻居结点,使用了另一组的embedding,称作context。目标函数依旧是KL散度,也就是最终,拥有相似邻居的结点,将会拥有相近的embedding。
最终要获得同时包含有一阶相似度和二阶相似度的embedding,只需要将通过一阶相似度获得的embedding与通过二阶相似度获得的embedding拼接即可。
(c)Node2Vec Node2Vec是一份基于DeepWalk的延伸工作,它改进了DeepWalk随机游走的策略。 Node2Vec认为,现有的方法无法很好的保留网络的结构信息,例如下图所示,有一些点之间的连接非常紧密(比如u, s1, s2, s3, s4),他们之间就组成了一个社区(community)。网络中可能存在着各种各样的社区,而有的结点在社区中可能又扮演着相似的角色(比如u与s6)。
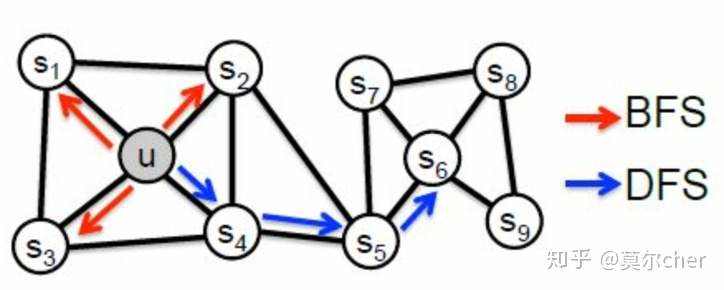
Node2Vec的优化目标为以下两个:
让同一个社区内的结点表示能够相互接近 在不同社区内扮演相似角色的结点表示也要相互接近。 为此,Node2Vec就要在DeepWalk现有的基础上,对随机游走的策略进行优化。Node2Vec提出了两种游走策略: 广度优先策略 深度优先策略达到这样的两种随机游走策略呢,这里需要用到两个超参数p和q用来控制深度优先策略和广度优先策略的比重,如下图所示。
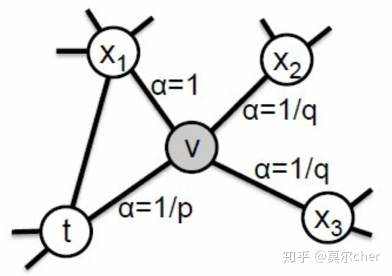
假设现在游走序列从t走到v,这时候需要算出三个系数,分别作为控制下一步走向方向的偏置α。
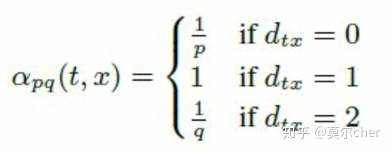
其中d(t, x)代表t结点到下一步结点x的最短路,最多为2。
当d(t, x)=0时,表示下一步游走是回到上一步的结点; 当d(t, x)=1时,表示下一步游走跳向t的另外一个邻居结点; 当d(t, x)=2时,表示下一步游走向更远的结点移动。 而Node2Vec同时还考虑了边权w的影响,所以最终的偏置系数以及游走策略为
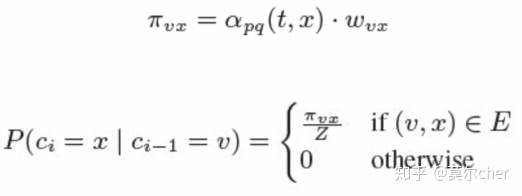
这样一来,就可以看出,超参数p控制的是重新访问原来结点的概率,也就是保守探索系数,而超参数q控制的是游走向更远方向的概率,也就是激进探索系数。如果q较大,那么游走策略则更偏向于广度优先策略,若q较小,则偏向于深度优先策略。
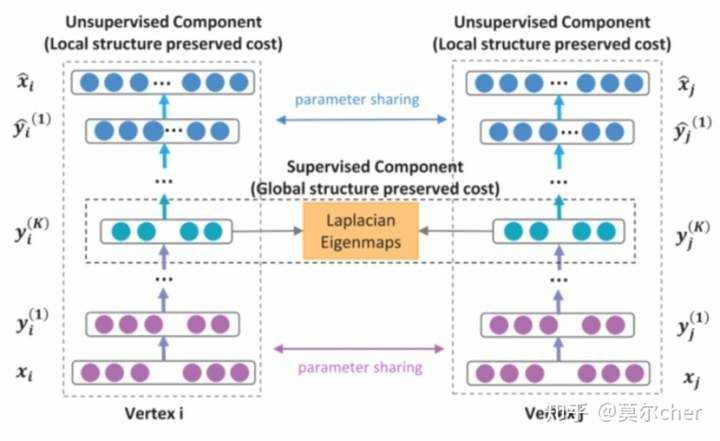
(d)SDNE: Structural Deep Network Embedding SDNE使用一个自动编码器结构来同时优化1阶和2阶相似度(LINE是分别优化的),学习得到的向量表示能够保留局部和全局结构,并且对稀疏网络具有鲁棒性。 SDNE提出了这样一个框架,能够使用深度自编码器,在训练的过程中,同时获得节点的一阶相似度和二阶相似度。
2阶相似度优化目标
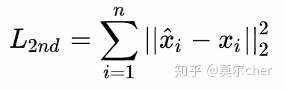
1阶相似度优化目标
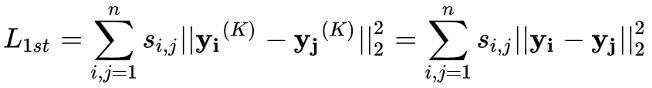
一个自动编码器的结构,输入输出分别是邻接矩阵和重构后的邻接矩阵。通过优化重构损失可以保留顶点的全局结构特性(Global structure preserved cost)。 自编码器中间的输出就是我们需要的embedding向量,模型通过1阶损失函数使得邻接的顶点对应的embedding向量接近,从而保留顶点的局部结构特性(中间应该是 Local structure preserved cost)
(a) 2019_aaai_ Session-based Recommendation with Graph Neural Networks
推荐系统可帮助用户发掘感兴趣的商品。大多数学术研究都关注根据长期用户档案进行个性化推荐的方法。然而,在许多现实世界的应用中,这种配置文件不会长期保存,而且用户的兴趣是动态变化的,因此必须仅基于用户在正在进行的会话对系统做出推荐。假设用户已连续访问电子商务网站中的上述五个项目。前四个将用作训练数据,我们的目标是准确预测最后一个项目。用户无需登录系统、也可能无法获得其他辅助信息。
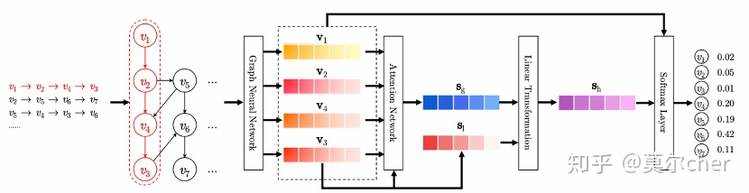
提出的SR-GNN 模型包括以下四个步骤:
(1)会话图建模
会话序列s由一个有向图构成,然后对edge的权重进行归一化。
(2)节点表示学习
文章采用GGNN来学习会话图中所有节点的统一表示。
主要的计算传播公式
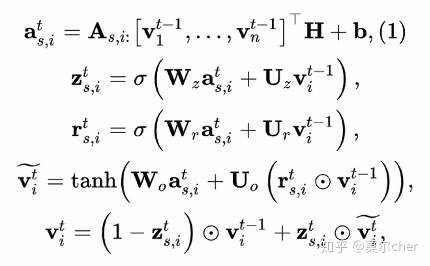
第一个等式利用连接矩阵(connection matrix)从邻接节点中整合信息。其他等式的更新与GRU模型类似。
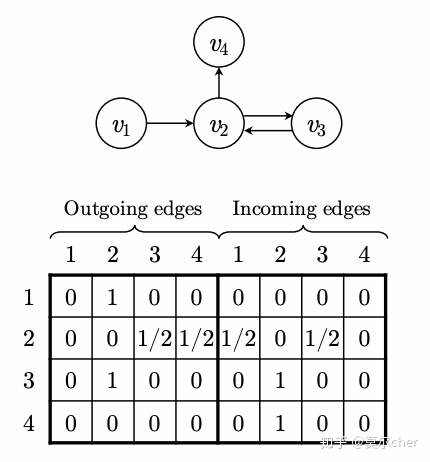
连接矩阵(connection matrix):
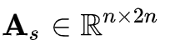
决定了图中的节点之间如何连接,由出度和入职矩阵组成
(3)会话表示生成
在获得项目嵌入之后,我们生成会话嵌入。会话由该会话中涉及的节点嵌入直接表示。
首先,我们代表用户当前的兴趣,也称作local embedding,以强调最后点击的项目的影响。
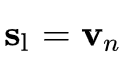
再者,通过软注意力网络(soft-attention network)获得global embedding,来表示全局偏好
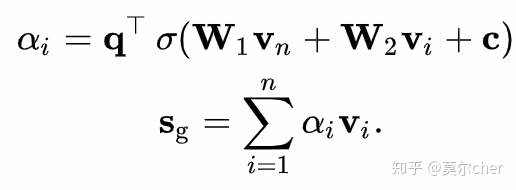
然后,我们通过简单的线性变换将两个向量组合起来以获得混合嵌入(hybrid embedding)
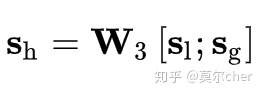
(4)生成推荐结果
最后,我们通过将其embedding与其会话表示相乘来计算每个候选项的得分。然后,我们应用softmax函数来获得模型的输出向量。
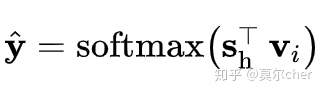
对于每个会话图,损失函数被定义为预测值与实际值的交叉熵。
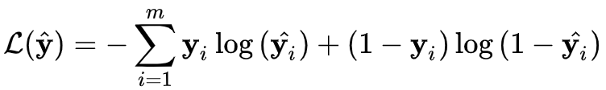
(b)2017_Inductive Representation Learning on Large Graphs
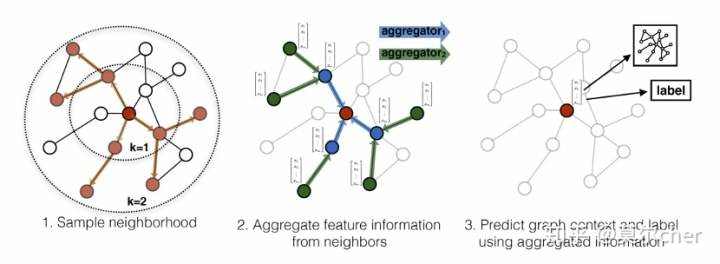
GraphSAGE同时利用节点特征信息和结构信息得到Graph Embedding的映射,相比之前的方法,之前都是保存了映射后的结果,而GraphSAGE保存了生成embedding的映射,可扩展性更强,对于节点分类和链接预测问题的表现也比较突出。
现存的方法需要图中所有的顶点在训练embedding的时候都出现;这些前人的方法本质上是transductive,不能自然地泛化到未见过的顶点。
文中提出了GraphSAGE,是一个inductive的框架,可以利用顶点特征信息(比如文本属性)来高效地为没有见过的顶点生成embedding。
GraphSAGE是为了学习一种节点表示方法,即如何通过从一个顶点的局部邻居采样并聚合顶点特征,而不是为每个顶点训练单独的embedding。
而GraphSAGE方法学到的node embedding,是根据node的邻居关系的变化而变化的,也就是说,即使是旧的node,如果建立了一些新的link,那么其对应的embedding也会变化,而且也很方便地学到。
第一步是对图中每个顶点邻居顶点进行采样,因为每个节点的度是不一致的,为了计算高效, 为每个节点采样固定数量的邻居
第二步是聚合邻居节点的信息,获得目标节点的embedding;
第三步是使用聚合得到的信息,也就是目标节点的embedding,来预测图中想预测的信息;
在实践中,每个节点的receptive field设置为固定大小,且使用了均匀采样方法简化邻居选择过程。作者设计了四种不同的聚集策略,分别是Mean、GCN、LSTM、MaxPooling。

Mean Aggregator: 对所有对邻居节点特征取均值。
GCN Aggregator: 图卷积聚集W(PX),W为参数矩阵,P为邻接矩阵的对称归一化矩阵,X为节点特征矩阵。
LSTM Aggregator: 把所有节点按随机排列输入LSTM,取最终隐状态为聚集之后对表示。
Pooling Aggregator: 邻接特征经过线性变换化取各个位置上对最大值。
1)Concat/Pooling,即将用户历史行为序列中物品对应的embedding进行concat或者pooling,实现比较简单,但没有考虑到历史行为与目标物品的相关性
2)attention,如阿里DIN,历史行为物品与目标物品进行attention计算对应的权重,然后进行加权求和,考虑了历史行为与目标物品的相关性,但是没有考虑历史行为的先后顺序以及时间因素
3)RNN结构,考虑了历史行为的时间顺序,但同样没有考虑到历史行为与目标物品的相关性
4)attention + GRU,如阿里的DIEN,考虑了用户历史行为中兴趣的演进过程,以及和目标物品的相关性,但是RNN结构线上耗时太高
5)Transformer,如阿里的BST,将RNN结构替换为Transformer,可以对历史行为进行并行处理,同时将时间因素加入到position encoding,考虑了历史行为发生的时间
总体而言针对ctr模型中的GNN对用户历史行为建模。主要是获得item的embedding。
(a)GNN的embedding相比于推荐模型中的embedding层获取的embedding,强调item在全部item集合中的空间位置(考虑图的结构信息)
(b)GNN的embedding构造方法可以分为2种。
b.1无监督方法(强调节点位置的临近和结构相似性)
(1)deepwalk:基于用户点击/购买的item序列,构建图,并基于random walk提取上下文序列,用于word2vec训练得到embedding,不能反映节点的结构信息。
(2)node2vec:改进deepwalk的random walk算法,基于bfs和dfs两种游走方式,挖掘结构信息。
(3)line:不使用随机游走,定义一阶相似度(是否临近)和二阶相似度(邻居集合是否相同),训练得到embedding
(4)SDNE:在line的基础上引入自编码器结构,融合一阶相似度和二阶相似度训练提取embedding
这些方法,基于节点位置的临近和结构相似性,强调图结构中item的位置和空间特性,与具体的预测任务无关。
b.2有监督方法(训练时有具体目标,训练时结合图结构)
(1)SR-GNN:训练时将item在图中获得的出度和入度举证,作为输入,经过Gate-GNN得到embedding,之后将embedding用于计算任务目标。基于任务目标的loss end-to-end训练。
(2)GraphSAGE:对图中每个顶点邻居顶点进行采样,聚合邻居节点的信息,根据聚合得到的信息预测图中想预测的信息(任务目标);可以预测没出现过的item的embedding,通过从一个顶点的局部邻居采样并聚合顶点特征,而不是为每个顶点训练固定的embedding。
(c) GNN的embedding是否可以获取历史行为中的时序信息
个人理解上,GNN的embedding更强调图结构中item的位置和空间特性信息,不同于之前推荐模型中的embedding层获取的embedding,可以作为新的信息加入,时序信息上体现较少。











 京公网安备 11010802041100号 | 京ICP备19059560号-4 | PHP1.CN 第一PHP社区 版权所有
京公网安备 11010802041100号 | 京ICP备19059560号-4 | PHP1.CN 第一PHP社区 版权所有